Избор на ключови думи в Yandex Wordstat. Статистика на заявките за търсене на Yandex, Google и Rambler, как и защо да работите с Wordstat
Здравейте, скъпи читатели на сайта на блога. Днес ще се опитам да ви разкажа за такова понятие като семантично ядро, във всеки случай ще се опитам, защото темата е доста специфична и едва ли ще представлява интерес за всички, въпреки че ...
А вътрешните страници на сайта, чието статично тегло не е много високо, могат да бъдат оптимизирани за нискочестотни заявки (LF), които, както вече споменах повече от веднъж, с късмет могат да бъдат популяризирани с малко или без външна оптимизация (закупуване на препратки към тези статии).
Но тъй като сме на темата честота на заявките, без да вземем предвид които едва ли ще успеем да съставим семантично ядро, тогава ще си позволя да ви напомня малко за това и как да определите тяхната честота. Така че всички заявки, които потребителите въвеждат в лентата за търсене на Yandex, Google или друга търсачка, могат да бъдат грубо разделени на три групи:
- висока честота (HF)
- средна честота (MF)
- ниска честота (LF)
Атрибут ключова фразакъм тази или онази група ще бъде възможно според броя на тези заявки, направени от потребителите през месеца. Но за различни предметиграниците могат да бъдат доста различни. Въпросът тук е, че ние всъщност, когато избираме ключови думине се интересува от честотата на въвеждане от техните потребители, а от колко трудно ще бъде напредванетовърху тях (колко оптимизатори се опитват да направят същото като вас).
Следователно ще бъде възможно да се въведат още три градации, които за съставяне семантично ядроще бъде от голямо значение:
- силно конкурентен (VC)
- средно състезателен (SC)
- ниска конкурентност (NC)
Но не винаги е лесно да се определи конкурентоспособността на определена ключова дума или фраза. Следователно, за простота, често се правят паралели и VC се идентифицира с HF, MF с SC и LF с NC. В повечето случаи такова обобщение ще бъде оправдано, но както знаете, има изключения от всяко правило и в някои теми NP могат да се окажат силно конкурентни и веднага ще видите това колко трудно ще бъде за да се преместите в ТОП за тези ключови думи.
Такива сблъсъци са възможни в теми, където има свръхвисока конкуренция и има борба за всеки отделен посетител, издърпвайки го дори напълно. нискочестотни заявки. Въпреки че това може да е присъщо не само на търговски теми. Например, информационните сайтове на тема "WordPress" при съставянето на семантичното ядро трябва да имат предвид, че дори заявки с честота под 100 (сто импресии на месец) могат да бъдат силно конкурентни по простата причина, че сайтовете на тази тема са тъмен, защото дори такива "тъпи чичковци" като мен се опитват да напишат нещо по тази тема.
Но ние няма да навлизаме в подробности толкова дълбоко и ще приемем, когато съставяме семантичното ядро, че конкурентоспособността (колко оптимизатори се опитват да популяризират своите проекти за този ключ) и честотата (колко често потребителите ги въвеждат в полето за търсене) са пряко свързани с всеки друго. Е, можем по някакъв начин да определим честотата на определени ключови думи, нали?
Можете да използвате няколко за това, но най-много харесвам инструмента Yandex. Преди това беше предназначено само за да могат рекламодателите да съставят правилно текстовете на своите контекстуални реклами, като вземат предвид кои думи потребителите най-често питат от тази търсачка.
Но след това достъп до онлайн услуга за проучване на ключови думипод името Yandex Wordstat (Wordstat.Yandex.ru) беше отворен за всички и същите тези хора не пропуснаха да се възползват от него. Е, с какво сме по-лоши?
Yandex Wordstat - какво да имате предвид при събиране на семена
Така че, нека да отидем на тази прекрасна услуга от Yandex, която се нарича „статистика на ключови думи“ и се намира на Wordstat.Yandex.ru. Тази услуга е създадена и се позиционира като незаменим инструмент за работа с Yandex Direct, както и за SEO промоция на вашия сайт за тази търсачка. Но всъщност той се превърна в най-мощния инструмент за анализ на ключови думи в Runet.
Следователно, в допълнение към прякото си предназначение Yandex Wordstat също може да се използва успешно:
- Работа с Google Adwords
- За търсене на популярни хаштагове в социалните мрежи
- За получаване на данни за търсенето на определен продукт
- За изграждане на структурата на сайта
- За търсене на подобни думи
- За тестване на търсенето на стоки или услуги в друг регион при търсене на нови пазари
- Да се анализира успеха на офлайн рекламата, като се анализира честотата на споменаване на думи на марка
С всичко това интерфейсът на Wordstat може да се каже, че е спартански, но това може би е само за добро. Ако искате повече, можете да използвате различни програми за отдалечена работа с тази услуга или да инсталирате плъгин като Yandex Wordstat Assistant във вашия браузър.
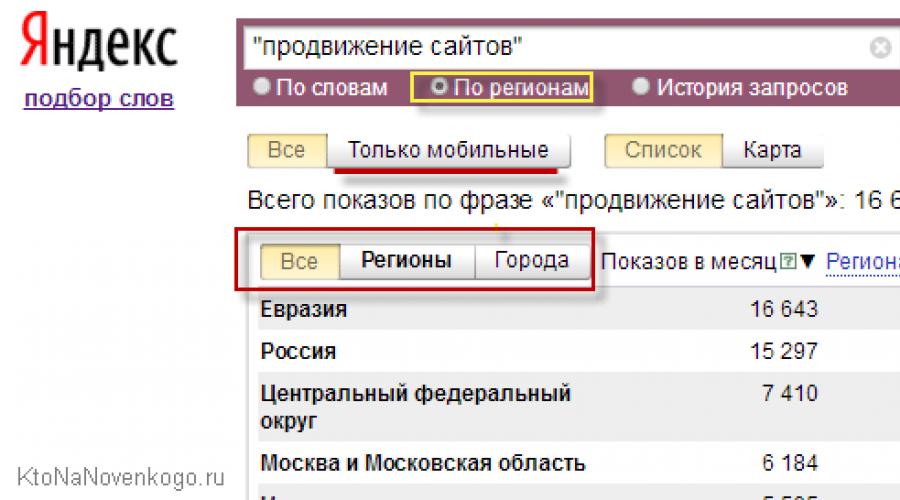
След като Yandex въведе разделението на резултатите от търсенето в зависимост от региона, имате възможност да видите честотата на въвеждане на определени заявки за търсенеза всеки регион поотделно (за това ще ви трябва изберете регионкато щракнете върху съответния раздел).

Ако регионалността не ви притеснява, тогава има смисъл да погледнете статистиката в първия раздел, без да вземете предвид геозависимостта. По принцип това не е толкова важно на етапа на изучаване на принципите за съставяне на семантично ядро за сайт. Както и наскоро появилата се възможност за преглед на статистика отделно само за мобилни потребители (използващи таблети и смартфони). Това може да е от значение в светлината на лавинообразния растеж на мобилния трафик.
Във всеки случай, първо ще трябва да изберете за себе си редица основни ключови думи (маски)по темата на вашия бъдещ проект, от който вече ще започнем да танцуваме по-нататък и ще изберем всички други ключови ключови думи с помощта на Yandex wordstat. Къде да ги вземем? Е, просто помислете или погледнете конкурентите, които познавате във вашата ниша (има услуга Serpstat, която може да помогне с това).
Да, и простата логика често е много полезна. Например, ако вашият бъдещ сайт ще бъде на тема "Joomla", тогава за да съставите семантичното ядро, би било съвсем логично да въведете тази ключова дума в Yandex.Wordstat като начало. Логиката е проста. Ако сайтът е базиран на SEO, тогава може да има много първоначални ключове (SEO, промоция на уебсайт, промоция, оптимизация и т.н.).
Е, като пример ще вземем друга фраза: „wordstat“. Нека да видим какво ни казва тази онлайн услуга за себе си. Тук си струва да направим няколко забележки.
Какво трябва да знаете и разбирате, за да използвате успешно WordStat
- Първо, за да започнете да получавате значителен приток от посетители за избрания от вас ключ, Вашият сайт трябва да е в топ 10(за първите десет живота, уви, практически няма) резултати от търсене (сърп - виж). И представете си, че има стотици, ако не и хиляди желаещи (състезатели). Следователно семето е само необходимо условие за успеха на сайта, но съвсем не достатъчно.
- Второ, освен това, сега почти всеки потребител има свой собствен проблем, който е малко по-различен от това, което вижда дори неговият съсед на пода. Предпочитанията и желанията на този конкретен потребител се вземат предвид, ако Yandex е успял да ги идентифицира по-рано (е, и регионът, разбира се, ако заявката е геозависима - например „доставка на пица“). Позициите в този план са „средна температура за болницата“ и не винаги ще доведат до очаквания наплив от посетители. Искате ли да видите истинската картина? Използвайте .
- Трето, дори ако се класирате в Топ 10 SERP (показвани на повечето от вашите целеви потребители), тогава броят на кликванията към вашия сайт ще зависи до голяма степен от две неща: позицията (първата и десетата позиция могат да се различават в възможността за кликване десетки пъти) и привлекателността на вашия сайт (информация за страницата на вашия сайт, показана в резултатите от търсенето за тази конкретна заявка).
- Заявките, които сте избрали да популяризирате и формират семантичното ядро, са прости може да е празен. Въпреки че манекените могат да бъдат идентифицирани и отстранени, начинаещите доста често се хващат на тази стръв. Как да го видите и поправите, прочетете малко по-надолу.
- Има такова нещо като опакованезаявки за търсене. На мен лично не ми хрумва на кого и защо е нужно това, но има такива искания. Започвайки промоция върху тях, няма да получите трафика, на който бихте могли да разчитате въз основа на данните на Yandex Wordstat. Прочетете повече за методите за откриване на измама по-долу.
- Посочете вашия регион (ако имате регионален бизнес или регионални запитвания), когато преглеждате статистиката, в противен случай може да получите напълно невярна картина.
- Не забравяйте да вземете предвид сезонността на вашите заявки (ако има такава), когато анализирате резултатите от промоцията. В Wordstat сезонността е ясно видима в раздела „История на заявките“. Не вземайте предвид сезонните възходи и падения като фактор за вашите неуспехи или успех в повишението.
- Удобно е да работите директно с интерфейса на услугата с малък брой заявки, но тогава вече става „мъчение“. Следователно основният въпрос за успешното използване на Wordstat е автоматизирането на рутинните операции. Как и с какво да автоматизирате ще бъде описано по-долу.
- Ако се научите как да използвате правилно операторите на Wordstat, тогава възвръщаемостта от него може да се увеличи значително. Това са кавички и знак плюс, както и разбиране за това какво дава тази услуга при въвеждане на не съвсем обикновени заявки. Прочетете за това по-долу и в раздела „Тайните на YanVo“
уплашен? Дори се уплаших, въпреки факта, че за стотици заявки (доста чести) блогът ми е в Топ (и не на последно място поради факта, че почти веднага започнах да работя въз основа на семантичното ядро, макар и в малко съкратена версия - избор на ключове за бъдеща статия точно преди да я напишете). Но ако започна сега (дори с настоящ опит), не бих повярвал, че ще „успея да пробия“. Вярно ли е! Мисля, че в по-голямата си част съм късметлия.
Wordstat оператори в примери
И така, нека разгледаме по-отблизо последните две точки - заявки с фиктив и измама. Готов? Е, тогава тръгваме. Да започнем с фиктивни заявки. Помните ли примера, който използвахме малко по-горе? Въведете думата WORDSTAT в реда на тази услуга и кликнете върху бутона "Избор".

Така че трябва да разберете, че цифрата, показана за тази дума (или друга фраза), изобщо не отразява действителния брой заявки за този ключ. Показан (внимание!) е общият брой заявени фрази на месец, в които е намерена думата "Wordstat", а не броят на заявките, които включват тази една дума (или фраза, ако въведете ключова фраза във формуляра на Wordstat) . Всъщност това е ясно от екранната снимка - "Какво са търсили с думата ...".
Но Yandex Wordstat разполага с подходящия инструментариум, който ви позволява да отделите житото от плявата (да идентифицирате манекени или да получите информация за честотата, която е адекватна на реалността) и да получите данните, от които се нуждаем. Това са различни оператори, които можете да добавите към вашата заявка и да получите прецизиран резултат.

Оператори за кавички и удивителен знак - премахване на празните места в Wordstat
Както можете да видите, има няколко основни оператора и основните, според мен, са ограждайки ключовата фраза в кавичкии поставяне на удивителен знак пред дума. Въпреки че за силно конкурентни теми може да е подходящо и нов оператор Wordstat под формата на квадратни кавички. Понякога е важно да знаете как най-често потребителите поставят думите в заявката, от която се нуждаете (например „купете апартамент“ или все още „купете апартамент“). Все още обаче не го използвам.
Така, wordstat оператор "кавички"ще ви позволи да преброите броя на записите в низа за търсене на Yandex на тази конкретна фраза през месеца, но в същото време ще бъдат взети предвид и изчислени всички нейни възможни словоформи - друго число, случай и т.н. (например заявките за Yandex Wordstat няма да бъдат взети под внимание, а само Wordstat в нашия пример). Всъщност това е същото нещо, за което разгледахме в статията. Цифра на честотата след такъв най-простата операцияще бъдат значително намалени:

Тези. такъв брой пъти на месец потребителите са въвели една дума WORDSTAT във всичките й словоформи (ако изобщо съществуват) в низа за търсене на Yandex. Разбира се, дадено исканеизобщо не е манекен, а пълноценен HF, но има моменти, когато просто затварянето на фраза в кавички намалява честотата от няколко хиляди до няколко десетки или дори единици (например, ударете фразата „печалба 100“ в кавички и без). Това беше наистина празно.
Второто важно твърдение в Wordstat е Удивителен знакпред дума, което ще задължи тази услуга да брои само думи точно в начина на изписване, в който сте ги въвели (без да се вземат предвид словоформите). Както очаквах, за думата "Joomla" инсталацията на оператора с удивителен знак не добави никакви корекции, но това е само поради спецификата на тази конкретна ключова дума.
Е, за ключовата фраза „промоция на уебсайт“ разликата ще бъде очевидна и поразителна:

И добавете "!" преди всяка дума без добавяне на интервал:

Откъде идва такава разлика в числата? Очевидно има заявка(и) със същите ключови думи, но в различна словоформа, която изяжда останалите числа. За нашия пример е лесно да се досетите, че това ще бъде множественото число:

По този начин, като използвате кавички около фразата и поставяте удивителен знак пред всяка от думите, можете да получите напълно различни честотни стойности. По този начин можете не само да премахнете манекени, но и да получите идеи за словоформите на фразата, които би било желателно да използвате в текста по-често и кои по-рядко (въпреки че не забравяйте за синонимите). Въпреки че лично аз не виждам голяма разлика при добавянето на удивителни знаци, така че се задоволявам с прости цитати.
Как бързо да премахнете боклука и да оставите само целеви заявки
Има друг оператор, който ви позволява да отрежете всички ненужни и да видите реалната честота на фразата. Това "+" пред дума. Това означава, че дадената дума трябва да присъства във фразата. Защо това може да е необходимо? Е, всичко е свързано с характеристиките на търсачката Yandex.
По подразбиране класирането (и съответно статистиката на Wordstat) не отчита съюзи, предлози, междуметия и т.н. думи. Това се прави, за да се опрости, но често се интересуваме от перспективата да се движим точно под фразата с предлог или съюз. Тук е полезен знакът плюс.
Между другото, минус операторще ви позволи веднага да изчистите ключовите думи от тези, които не са целеви за вас. Например, такава заявка към WordStat веднага ще даде желания резултат:
Смартфони (+до|+от|+до) -изтегляне -игри -интернет -mts- снимка

Тук, за да не се повтаря тази заявка три пъти, се прилага операторът "вертикална лента", което ви позволява да събирате фрази с три предлога наведнъж (до, от, до). Е, думите с минус (стоп думи) са необходими, за да изчистите фразите от боклука.
Ето още един пример за използване на оператори за същата цел:
Перални (автомобили | машини) (samsung | samsung)
Много е удобно и бързо отрязва ненужното и спестява време.
Избор на ключови думи в Yandex Wordstat
Вероятно вече ви става ясно, че тези основни ключови фрази (маски), които можете да формулирате сами, въз основа на бъдещата тема на вашия проект, ще трябва да бъдат разширени с помощта на Wordstat. И тук също има, като че ли, две посоки за получаване на нови ключови думиза съставяне на пълноценно семантично ядро.
- Първо, можете да се възползвате от тези разширени опции, които Wordstat дава. в лявата колонавашия прозорец. Ще има заявки, които съдържат думи от вашата маска (например „строителство“, ако вашият проект има съответна тема). Те ще бъдат сортирани в низходящ ред според честотата на използването им от потребителите в реда за търсене на Yandex на месец.
Кое е важното тук? Важно е веднага да подчертаете тези разширени ключови опции, които ще бъдат насочени към вашия проект. Мишена- това са такива заявки, според съдържанието на които веднага става ясно, че потребителят, който влиза в него, търси точно това, което можете да му предложите на вашия сайт, който планирате да популяризирате.
Например, заявката „ядро“ е изключително висока честота, но изобщо не ми трябва, защото това абсолютно не е целевата ключова дума за тази публикация. Никога не знаете какво търсят потребителите, когато го въвеждат в лентата за търсене на Yandex, добре, със сигурност не „семантично“, което между другото ще бъде ярък пример за целева заявка във връзка с тази статия.
Но трябва да изберете целеви ключове по отношение на целия бъдещ сайт, въпреки че понякога е полезно да преминете към общи заявки, но това е по-скоро изключение от правилото.
Целевите фрази ще бъдат с по-ниска честота и потребителите, дошли от тях от резултатите от търсенето, ще могат да намерят поне нещо подобно на това, което са искали да намерят, което означава, че няма веднага да напуснат проекта ви, като по този начин влошат . Да, и такива посетители са много важни за вас, защото те могат да извършат действието, от което се нуждаете (направете покупка или поръчайте услуга).
Мисля, че няма нужда да говорим повече за избора на точно такива ключови думи от статистиката на Yandex - вече разбирате всичко. Единственото "но". Всички фрази от дясната колона на Wordstat отново за вас трябва да проверите за грешки, а именно ги оградете в кавички (статистика с удивителни знацимогат да бъдат разгледани и анализирани по-късно. Ако честотата не клони към нула, тогава я добавете към скривалището.

Вероятно сте забелязали, че за много фрази списъкът в лявата колона не е ограничен до една страница (в долната част има бутон „следващ“). Максимумът, който Wordstat дава според мен е 2000 заявки. И всички те ще трябва да бъдат проверени за манекени. Можеш ли да се справиш? Но това е само една от многото "маски" ( начални ключове) на вашето семантично ядро. В крайна сметка можете да „преместите коне“ там.
Но не се притеснявайте, има начин. На линка ще намерите подробна статия и ако след това остане нещо неясно, хвърлете камък върху мен.
- Вторият нюанс при подбора на фрази за семантичното ядро е възможността за използване на т.нар асоциацииот статистиките на Yandex Wordstat. Дадени са тези много асоциативни запитвания в дясната колонаглавния му прозорец.

Тук вероятно е важно да разберете как се формират тези много асоциативни заявки в статистиката на Yandex и откъде идват. Факт е, че търсачката анализира поведението на потребителя, който търси нещо от него.
Например, ако потребителят, след (или преди) да напише нашата ключова фраза „семантично ядро“, въведе някаква друга заявка в низа за търсене (това се извиква в една сесия за търсене), тогава Yandex може да направи предположение, че тези заявки по някакъв начин са взаимосвързани .
Ако същата асоциативна връзка се наблюдава сред някои други потребители, тогава тази заявка, зададена заедно с основната заявка, ще бъде показана в дясната колона на Wordstat. Е, просто трябва да използвате тези данни, за да разширите семантичното ядро на вашия сайт.
Всички сдружения ще имат индикация за честотата на заявките си през месеца. Но, разбира се, ще бъде общо, т.е. все още трябва да идентифицирате манекени отново, като поставите отметка във всички тези фрази в кавички (Slovoeb или Key Collector ще ви помогнат - прочетете за тях на връзката по-горе).
Някои от запитванията за асоцииране вероятно са ви минавали през ума, но винаги ще има други, които сте пренебрегвали. Е, колкото повече целеви ключови думи ще включва вашето семантично ядро, толкова голямо количествоМожете да привлечете правилните посетители към вашия сайт с подходяща вътрешна и външна оптимизация.
Така че ще приемем, че въз основа на основните маски (ключови думи, които ясно определят предмета на вашия бъдещ проект) и възможностите на Yandex Wordstat сте успели да въведете достатъчен брой фрази за семантичното ядро. Сега ще трябва ясно да ги разделите по честота на употреба.
Тайни техники за работа с WordStat
Разбира се, това заглавие е донякъде светло, но все пак „тайните“, описани по-долу, могат да ви помогнат да използвате този инструмент на 200%. Просто, ако това не се вземе предвид, тогава можете да отделите време, пари и усилия напразно.
Как да видите увеличение на заявката за търсене в Wordstat
Очевидно е обаче, че за някои ключови думи Wordstat дава невярна информация. Свързано ли е това с някакви опции за измама и как да се определи такава залъгалкиЩе се опитам да обясня. Разбира се, проверката на всички фрази по този начин може да бъде досадна и вероятно просто изисква опит (усещане), но работи доста добре.
Лично аз изхождам от предпоставката, че те се завършват, като правило, не години наред, което означава, че отклонението от средната стойност на честотата може да се проследи на графиката „История на заявките“(превключвателят е скрит под реда за въвеждане на заявка за услуга Yandex Wordstat). Например, наскоро пуснах заявки, свързани с " партньорска програма” и просто се натъкнах на измама (почти всички ключове, свързани с темата).

Просто работя с тези заявки от дълго време и приблизително знам „оформлението“. Там HF един или два грешно изчислени и тогава това, което не е ключът, тогава HF. Но просто погледнете историята на честотата на тази заявка в Wordstat (не забравяйте да премахнете кавичките предварително) и всичко става ясно (започнаха да се въртят от началото на лятото):

Освен това честотата на заявката е нараснала почти с два порядъка за няколко месеца, а няколко години преди това беше стабилна и дори не претърпя специални сезонни колебания. Явна измама - не знам защо, но те изкривяват всички придружаващи ключове.
Как да автоматизирате събирането на ключови думи в услугата Yandex
По принцип можете да работите през уеб интерфейса, но е много досадно. Има програми (платени и безплатни), подходящи за тази цел. Има дори разширения на браузъра, които ви позволяват да победите малко рутината. Нека просто ги изброим:
Защо има толкова висока честота на заявки с повтарящи се думи?
Ако вече повече или по-малко сте се потопили в проблемите на компилирането на семена и анализирането на много заявки в Wordestat, тогава вероятно сте срещнали странни заявки с повтарящи се думи, които по някаква причина имат висока честота, дори когато са оградени в кавички и удивителни знаци се поставят пред думите.

Дори ако добавите „гледайте“ още няколко пъти, честотата ще остане почти същата висока. И какво, вярвайте на Yandex и оптимизирайте статиите за такива глупости? Не на твоята Нели. Това е друг вид "манекен". Всъщност Wordstat възприема само една от повтарящите се думи, но „мислено“ замества останалите с други възможни думи със същия брой знаци. Като цяло, въпреки големите числа, не трябва да обръщате внимание на заявки с повтарящи се думи. Това е фантом.
Завършване на компилацията на семантичното ядро
Както казах малко по-нагоре, ще разгледаме HF и VC по подразбиране, което означава, че за да се движите през тях, трябва да изберете онези страници от вашия сайт, които ще имат най-голямо статично тегло. Този е нает от входящи връзки към тази страница.
Важно е да разберете, че когато се изчислява, съдържанието на анкора на връзката не се взема предвид и няма значение дали е външно или вътрешно. Прочетете повече за дадения линк.
Че. за напредък на най-високите честотизаявките (от компилираното семантично ядро) са най-подходящи за главната страница, тъй като по правило връзките ще водят към нея от всички други страници на вашия ресурс (с нормална структура), както и повечето външни връзкиособено получените по естествен път. Така че статичното тегло на основния ресурс за повечето ресурси ще бъде най-високо (преди това можеше да се разбере по индикацията на стойността на лентата с инструменти на Google PageRank, която за него винаги ще бъде по-висока, отколкото за вътрешните, но сега Google реши да спре споделяне на тази информация с нас).
При равни други условия (еднакво качество на вътрешна и външна оптимизация) търсачките ще класират по-високо страницата, чието статично тегло е по-голямо. Следователно, ако решите да напреднете на требъл вътрешна страница(с очевидно по-ниска статистическа тежест), тогава конкурентите ще имат предимство пред вас, ако рекламират със същите ключови думи, но вече начална страницавашия сайт. Макар че, по най-добрия начинще има анализ на Топ 10 за ключовата дума, от която се нуждаете, по отношение на броя на основните, които участват в класирането (това, между другото, косвено показва конкурентоспособността на заявката).
Ако структурата на вътрешното свързване на вашия бъдещ проект включва и други страници с голямо статично тегло (секции, категории и т.н.), тогава в семантичното ядро ще трябва да ги маркирате като потенциални кандидати за оптимизация за повече или по-малко високи - и средночестотни заявки от тези, които сте избрали.
По този начин ще можете да използвате добре характеристиките на разпределението на статичното тегло на вашия сайт и в съответствие с това да изберете най-подходящите по честота заявки за всяка от страниците, т.е. съставете напълно семантично ядро: съвпадение на двойки заявка - страница.
Въпреки това, когато оптимизирате страница за промоция чрез HF или MF ключова фраза, можете да добавите ключова дума с по-ниска честота, която ще бъде получена чрез разреждане на главния ключ. но отново, не всички ключове могат да бъдат направени съседи на едно и също целева страница . За да разберете кои могат и не могат да се използват заедно, можете да анализирате преките си конкуренти в Топ 10 за основната ключова дума. Ако са в Топ, това означава, че търсенето на тяхната версия на семето е по техен вкус.
Въпреки това, лесно да се каже и трудно да се направи. Опитайте се да потърсите изхода за стотици (хиляди) заявки от вашето предварително семантично ядро относно тяхната съвместимост или несъвместимост. Тук със сигурност "конете могат да бъдат преместени". И тук обаче ще ви се притека на помощ, като дам линк към подробна публикация за. В действителност всичко е опростено от малка програма.

При външна оптимизация (закупуване и поставяне на връзки с необходимите котви), трябва отново да вземете предвид създаденото семантично ядро и да поставите обратни връзки, като вземете предвид онези ключови думи, за които е оптимизирано тази страницавашия сайт. Не забравяйте, че в ерата на Minusinsk и Penguin е по-добре да поставите обратна връзка с директно влизане, но от много смел и тематичен сайт, и „разреждане“ с котви, заглавия на статии и т.н. струва си да направиш повече.
На практика вашето семантично ядро вероятно ще представлява доста разклонена схема от страници с избрани за тях ключови думи, за които те ще бъдат оптимизирани и популяризирани. Там ще бъде начертана и схемата на вътрешната връзка за изпомпване. желаните страницистатично тегло.
Общо взето всичко възможно ще бъде включено и обмислено, остава само да се започне изграждане (или преправяне) на обекта по този проект(семантично ядро). Лично аз напоследък винаги следвам правилото за предварителното му компилиране, защото работата на сляпо може да не е печеливша дейност - ще изразходвам енергията си, а тези, които намират материала за интересен и полезен, няма да го намерят нито в Yandex, нито в Google. ..
Ако говорим за този блог, тогава преди да напиша статия, определено ще отида в Wordstat и ще видя как потребителите формулират въпросите си по темата, за която планирам да пиша. По този начин аз по-вероятноЩе намеря своя читател, който с успешна публикация може да стане постоянен. Това не е лошо за никого, освен че просто трябва да отделите малко време.
Е, в случай на проект на нова за вас тема и особено ако сте начинаещ оптимизатор, компилирането на такова ядро и подбора на подходящи ключови думи може да ви помогне много и да избегнете ненужни грешки. Въпреки това, не всеки има време и енергия да извърши такава работа, но все пак го направете задължително. Но ако има търсене, ще има и предлагане. Винаги ще има хора, които ще са готови да го направят вместо вас, друго нещо е, че те не винаги могат да бъдат честни и ефективни.
Късмет! Ще се видим скоро на сайта на страниците на блога
Можете да гледате още видеоклипове, като отидете на");">

Може да се интересувате
 Статистика на заявките за търсене на Yandex, Google и Rambler, как и защо да работите с Wordstat
Статистика на заявките за търсене на Yandex, Google и Rambler, как и защо да работите с Wordstat  Отчитане на морфологията на езика и други проблеми, решавани от търсачките, както и разликата между HF, MF и LF заявки
Отчитане на морфологията на езика и други проблеми, решавани от търсачките, както и разликата между HF, MF и LF заявки
Здравейте всички! Днес искам да говоря за правилата за работа с услугата wordstat.yandex.ru, която предоставя статистика за заявките за търсене в Yandex. Използвам тази услуга много често. Задължително преди писане на всяка статия.
Факт е, че е важно не просто да напишете статия, а да го направите правилно от гледна точка на оптимизацията за търсачки. Всяка статия трябва да бъде съобразена с определена дума или фраза, която се нарича ключ или само ключ. Тези ключови думи са начинът, по който потребителите намират вашия сайт с помощта на търсачките.
Всъщност ключът е думата за търсене, в която рекламирате търсачкиах с надеждата, че хората ще дойдат на вашия сайт, използвайки го. Разбира се, за да вземете решение за тях, просто трябва да имате представа колко хора го използват за определен период от време. В крайна сметка, ако честотата на употреба е малка, тогава е напълно безсмислено да се насърчава.
Имайте предвид, че не винаги си струва да избирате най-често използваната заявка за търсене, тъй като конкуренцията за тях е много висока. Не забравяйте да прочетете за - тази информация ще ви позволи да изберете правилните ключови думи за вашия сайт.
Както знаете, в Русия има две водещи търсачки - Yandex и Google. Всеки от тях предоставя своя собствена услуга за преглед на честотата на заявките за търсене. Днес ще говорим за статистическите данни за ключовите думи на Yandex -.
Правила за работа с wordstat.yandex.ru
Услугата wordstat.yandex поддържа пет филтъра, които ви позволяват да получите изчерпателна статистика за желаната ключова дума.
1. По думи (използва се по подразбиране). Отляво посочваме региона, в който искаме да видим статистиката на импресиите на тази заявка за търсене в Yandex.
Въведете точна думаили фраза и щракнете върху „Избор“. Ако не използвате допълнителни оператори, които ще разгледам по-долу, wordstat.yandex ще върне резултата под формата на два списъка. Списъкът отляво показва статистика за заявки, съдържащи думата, която се изследва. Списъкът вдясно ще ви покаже какво още са търсили хората, използвайки заявката, която сте въвели.

Основната грешка е, че при липса на допълнителни оператори wordstat.yandex ще даде броя импресии на месец, който съответства на всички заявки за търсене, които съдържат въведената фраза в различни словоформи. Не забравяйте да използвате оператори, за да сте конкретни.
Словоформа - формата на думата, получена от основната част на думата чрез спрежение или склонение.
2. По региони. Показва статистика за ключови думи по регион и град. Можете да изберете статистика отделно за градове и отделно за региони. В допълнение към показването на броя импресии на месец е посочена друга стойност - регионална популярност.

Името говори само за себе си: регионална популярносте условна стойност, измерена като процент, показваща популярността на тази заявка в определен регион/град.
- 100% - искането не е нищо забележително.
- Над 100% - има повишен интерес.
- По-малко от 100% - намалена лихва.
- 0% - изобщо не се използва в този регион.
3. На картата. Статистика за ключови думи от Yandex по региони, представена вече не под формата на таблица, а визуално в количката Mira. Задръжте курсора на мишката над желания регион и вижте броя импресии на месец и регионалната популярност. За да увеличите, щракнете върху страната и отидете на нейните субекти.

4. По месеци. Месечна статистика. Само не забравяйте да посочите региона, за който ще се показва. Информацията е дадена под формата на графика, както в абсолютни, така и в относителни стойности (можете да изберете). Графиката е прекъсната линия. Координатите на всеки връх са броя на импресиите (по Y) и месеца (по X). Всичко звучи малко неясно, но на практика всичко е много просто. Просто погледнете чертежа.

5. Ежеседмично. Идентичен с предишния филтър, само че сега времевият интервал не е месец, а седмица.
Оператори Yandex.WordStat
Допълнителните оператори са предназначени да персонализират получената статистика. Нека ги разгледаме с примери, така че всичко да стане много ясно.
1. - (оператор минус). Операторът "-" се поставя преди думата, която трябва да бъде изключена. Операторът се предхожда от интервал.
Пример. Ако посочите в търсенето игри - компютър, след това вземете статистика за всички заявки, съдържащи „игри“, с изключение на тези, съдържащи „компютър“. Можете да изключите няколко думи наведнъж, като поставите оператор "-" пред всяка от тях (само не забравяйте да ги разделите с интервали). Например, игри - компютър - дъска. Всички заявки, съдържащи "компютър" или "десктоп", ще бъдат изключени от резултатите.
2. () (оператор за групиране "скоби"), | (логически оператор "или"). При споделяневи позволяват да създавате много сложни заявки.
Пример. Заявка сървър (специален | локален)еквивалентен отдалечен сървърИ локален сървър.
3. "" (оператор за кавички). Много важен оператор, който ви позволява да посочите заявката. Ще бъдат взети предвид само впечатления от дадената дума и нейните словоформи. Всички заявки, които включват допълнителни думи, ще бъдат филтрирани.
Пример. Заявка "таблица". Броят импресии на думите "маси", "маси", "маса" ще бъде даден, но изключен с допълнителна дума - "тенис маса", "компютърна маса" и др.
4. + (оператор плюс). Поставя се пред предлози, за да се вземат предвид.
Пример. Инсталиране на wordpress + на denwerпредлогът "на" ще бъде взет предвид.
5. ! (оператор с удивителен знак). Думата, предшествана от оператора "!", се взема предвид при точното й изписване. Всички словоформи са премахнати.
От всички тези оператори най-често се използват "" и!, което ви позволява да посочите статистическите данни, получени от Yandex. Да кажем резултата от въвеждането "!инсталиране!wordpress"ще бъде броят импресии на заявката инсталация на wordpressи никой друг.
Изглежда, че на пръв поглед услугата wordstat.yandex.ru е много проста, но каква голяма функционалност се крие в нея! Горещо препоръчвам да го разберете и овладеете.
Благодаря за вниманието. Пази се!
Какво е Yandex.Wordstat
Той предоставя месечна статистика на импресиите на заявките за търсене, зададени от потребителите в търсачката Yandex. Да приемем, че съм написал фразата „2016 е високосна година или не“ в лентата за търсене. В Yandex.Wordstat можете да разберете колко пъти през месеца посетителите на Yandex са се интересували от едно и също нещо.
Защо имате нужда от Wordstat

Как работи wordstat
Опростен пример за това как се сортират думите в Wordstat:
новини Русия 4
новини Русия Украйна 1
Руски бизнес новини 1
Руски футболни новини 1
новини Русия Украйна 1
бизнес новини на Украйна 1
Украински футболни новини 1
Новини 8
новини Украйна 4
зелени числае броят на импресиите. Всяка фраза беше зададена дума по дума веднъж. Попитаха „новини“ веднъж, попитаха „новини от Русия“ веднъж, попитаха „новини от Русия Украйна“, „новини от руски бизнес“, „новини от руски футбол“ по веднъж. Общо заедно 2 думи "новини Русия" са намерени 4 пъти. Няма значение в каква словоформа („Русия“, „Русия“) и в каква последователност („новини Русия“, „новини в Русия“). Думата "новини" - 8 пъти, тъй като "новини Русия Украйна" е дадена веднъж и се споменава в две групи "новини Русия" и "новини Украйна".
Инструкции за използване на Wordstat
В полето за търсене трябва да въведете желаната ключова фраза, например „2016 е високосна година или не“ 
Импресии: 50 741. Тази цифра включва всички заявки, изброени по-долу: и „високосна година“ дали 2016" и "високосна 2016 г знаци", И " може да се оженивисокосна 2016 г.“ и др. Ако щракнете върху "високосна година 2016", тогава ще има 4 или повече заявки за думи.
„Високосната 2016“ има същия брой импресии. Тези фрази са идентични, тъй като в Yandex.Wordstat:

Оператори Yandex.Wordstat
Плюс оператор + : вземат под внимание определени местоимения, предлози, съюзи, частици


Оператори за вертикална лента | "или" и скоби () "групиране": вземете предвид изброените синоними




оператор с удивителен знак! : търси дума само в зададената словоформа


Не всички заявки се показват по подразбиране, например "без високосни години" се появява при търсене на "високосни години".
Минус оператор - : премахване на определени допълнителни думи


Оператор за кавички " ": ограничаване на дължината на заявката (брой думи)
1 дума. Заявката ""година"" се използва по-рядко от ""високосна година"". Ясно е. Какво очакват да видят хората? Каква е годината сега? Какво е година? 
2 речника 
3 речника: тук отново изглеждаше „без високосна година“ 
4 речника 
12 речника. Дори не искам да мисля как могат да бъдат формулирани. 
Бележки:
- Еднаквите думи се комбинират, кавичките ограничават броя на думите, в резултат на което всяка друга дума се замества с втората и следващите еднакви думи.
- Не се учудвайте, че няма 5 речника, а има 6 речника.
- Местоименията, предлозите, съюзите, частиците се включват в заявката в кавички. Пред тях не е необходимо да се пише плюс.
- Не можете да комбинирате кавички с оператори минус, вертикална лента, скоби.
Оператор в квадратни скоби: спазвайте реда на думите


Бележки:

Официални обяснения: Yandex.Help, блог на AdWords
Регион в Wordstat: как да видите статистика за ключови думи само в рамките на един регион или един град

Как да разберете в Wordstat колко гледания има точен запис
За формулиране на фрази е необходимо точно съвпадение:
- За контекстна реклама(например Yandex.Direct, Google AdWords),
- За ,
- за заглавки.

Брой импресии: 6
- за търговски сайтове в повечето случаи трябва да запомните да зададете региона.
- цялата фраза трябва да бъде оградена в кавички и квадратни скоби.
- предписвайте удивителен знак преди всички думи (не можете да го поставите пред предлози, съюзи и частици).
Струва си да запомните, че 5000 импресии в Yandex.Worstat няма да доведат 5000 души на страницата на сайта, защото:

Как да съберем всички заявки за Wordstat
За първоначалното запитване "как да изберем парцел за строеж на къща" от двете колони трябва да изберете думи, подходящи за темата 
Разширете търсенето, като първо премахнете думата "строителство", след това "изберете" и т.н. 
Редки фрази могат да се събират от предложения за търсене, включително с помощта на специални програми 
Ще получите приблизително такава таблица, където можете да комбинирате клетки. Например „избор на място за къща“, „как да изберем правилното място за строителство“ и др.
| избирам | парцел | За | |||||||
| как | вярно | Вдигни | добре | поземлен имот | под | строителство | жилищен блок | къща | в държавата |
| Който | избор | подходящ | място | сградите | многоетажна | ижс | в селото | ||
| селекция | място на партидата | лятна вила | вила | в града | |||||
| земя | частен | къща | |||||||
| държава |
Здравейте момчета! Всички знаете много добре, че продавам ключови думи от доста време. Искам да кажа, че правя това на комерсиална основа от дълго време.
Всички тези услуги, които описах, бяха разширени многократно от мен за дълго време. Влизат разни перверзници, които измислят такива задачи, за които преди не бих се сетил. Е, постепенно ставам майка поради факта, че ме карат да изпълнявам трудните им задачи.
Вероятно всеки си спомня, че съм писал много пъти за базите данни на Пастухов: преди много време казах какво представлява този страхотен софтуер, след това казах, че Максим Пастухова (авторът на софтуера) обяви пускането на 180-милионната руска база данни с ключови думи. Това .
Но наскоро направих проект за сайта на един уважаван човек. Проектът беше изключително за Yandex. Анализирах сайта му, намерих ключовете, за които той вече заема нормални позиции в резултатите от търсенето, оцених тези ключове с помощта на wordstat, rambler, Rookee ... това е, нека да забавим.
Резултатът е списък с добри ключове. Но! Те произвеждат много двусмислени ключове. Ето ги и тях

Тоест вземаме за пример ключа " радио радио слушайте онлайн". Разглеждаме честотата според wordstat. Ето екранна снимка, показваща точната честота. Тоест използван е операторът "! дума! дума". И какво виждаме? Че този ключ е с честота 563141 за моя регион, за който е направен анализът.
Клиентът веднага ме пита: „Сергей, какво по дяволите? Къде отиде нещастникът радио радио слушайте онлайн"563141 импресии на месец?" И прогнозата за кликване на Rookee показва -1 кликвания върху този ключ, което означава xs колко кликвания ще има. Тоест пише, че ще има 0 от тях.
И тогава аз просто допер, тази епта, защото е така великолепна идеяза поста - да го нарисувам тази залепа, която е в wordstat, още повече, че Maul наскоро писа за нея. Само аз ще разкажа за това от моята камбанария и ще покажа допълнително как се решава този проблем.
И каквото се залепи, значи заседна. Ето как да разберете какво всъщност е? Първото нещо, което идва на ум, е да отидете на помощта на самия Wordstat и да прочетете какво пишат самите те за него. Но не, единственото нещо, което виждаме:
И какъв е резултатът? Но нищо! От написаното тук нищо не става ясно защо дрънка по молбата " радио радио слушайте онлайн» такива голям бройимпресии.
И всъщност тази залепка има просто обяснение. Отваряме свежи бази данни на Пастухов за 180 милиона kei, правим селекция от базата данни за ключовата дума "слушайте радио онлайн"

Мисля, че тези, които често се ровят в wordstat, са добре наясно, че изваждането на такива ключови думи от там е почти нереалистично.
Между другото, това не са най-дългите ключови думи. IN бази на ПастуховДобавих показване на честотата според wordstat.yandex. Вижте, има по-готини или по-скоро по-автентични ключове

Или ето още един
Ясно е, 10 речника " интернет радио онлайн слушайте безплатно европа плюс класически медиен плейър» не може да има честота, а ако може, тя е толкова незначителна, че не се показва в wordstat. Но факт е, че такива многословни хора създават този шамар с ключови думи. Вижте сами

Какво виждаме тук? Виждаме, че десетте думи ” е с честота 5967, което само по себе си изглежда някаква утопия.
Защо е така?
Има една функция в wordstat - в него не ми пукаредът на ключовите думи, във връзка с който, ако не разбирате целия този механизъм, тогава можете глупаво да пропилеете бабло, премествайки в бъдеще ключови думи, които не дават трафик на изхода.
Всичко това се вижда много ясно, когато добавим колона със статистика на заявките към Rambler в базите данни на Пастухов, в която редът на думите не ми пука. Тогава картината веднага става ясна и виждаме за кои заявки има система и за кои не. Тоест, кои заявки се въвеждат редовно, кои наистина могат да бъдат повишени и кои просто създават статистика за такива залепи, които показах по-горе. Тук, в базите данни на Пастухов, е особено удивително, че можете веднага да оцените честотите на Yandex и Rambler за една ключова дума

Специално съм групирал исканията тук, за да стане ясно. Тоест в идеалния случай, ако популяризирате, тогава вземете такива ключове, където ще има честота както за Rambler, така и за Yandex. Но това е идеално.
И все пак, как става така, че заявка от 10 думи с повтарящи се думи може да има честота 5967?
Честно казано, защо не са написали в помощта на Wordstat, защо може да е така. Но тук е смисълът.
Както вече беше споменато по-горе, в Yandex те въвеждат много заявки, сред които има много такива с десет думи. И още повече. Често тази информация не може да бъде извадена от wordstat, но всички тези ключове показват добре базите на Пастухов (забележете - сега затворен проект). И самата улика се крие във факта, че дублиращите се думи не се вземат предвид директно в заявката.
Тоест искането "!радио!радио!радио!радио!радио!радио!радио!радио!слушайте!онлайн”, който има честота 5967, всъщност в абсолютно същата форма не се показва толкова, колкото показва wordstat. Тук се взема предвид само фразата „слушайте радио онлайн“. Тоест последните три думи. И вместо предишните 7 думи „радио“, могат да се използват напълно различни думи. И всичко това създава статистика за тези десет думи. Специално направих селекция от резултатите, получени от „слушане на радио онлайн“ в базите данни на Пастухов. Там можете да сортирате по дължината на заявките за търсене и по броя на думите.

И в резултат на това получаваме всички (или почти всички) ключови думи от десет думи, които правят статистика за нашите "!радио!радио!радио!радио!радио!радио!радио!радио!слушайте!онлайн". Ето ги и тях:

И има повече от достатъчно такива десет думи. Тоест, повтарям още веднъж, че вместо думата „радио“ може да има всяка друга дума, стига да е включена в десетте думи, които съдържа фразата „слушайте радио онлайн“.
Ситуацията не би била толкова двусмислена, ако wordstat показваше ключовите думи в точно същия ред, в който са поискани. Но не. В нашите десет думи, вместо думата "радио"може да има всякакви други думи и всички те могат да бъдат разменени в рамките на този списък с десет думи, като по този начин се затваря индикаторът му в wordstat.
Ето защо се оказва, че искането " радио радио слушайте онлайн“ всъщност в точно същата последователност и с точно същите думи, както е посочено тук, няма честота 563141 и никога не е имала. И такава цифра се получава, защото вместо първата дума "радио" може да има всяка друга и тя може да стои на произволно място в този списък от четири думи, което в крайна сметка формира толкова голяма цифра в 563141. И има много такива четири думи с различни тълкувания
Здравейте, скъпи читатели на сайта на блога. Искам още веднъж да засегна темата за избора на ключови думи за отделни статии и целия сайт като цяло. Това ще ви позволи по-точно да достигнете до аудиторията, която може да се интересува от вашата публикация.
Потенциално. Тези. това не гарантира успех, но ви позволява да се надявате на него. С други думи това е необходимо условие за успешното развитие на сайта, но съвсем не е достатъчно.
Най-популярният инструмент, който ви позволява да анализирате статистиката за използването на различни думи и фрази в заявките на потребителите на търсачката, е инструментът „Избор на думи“ от Yandex(известен WordStat). Предназначен е за рекламодатели, които рекламират в, но това не е същността му, тъй като статистиката, която произвежда, може да бъде полезна и за оптимизиране на вашия собствен сайт.
Можете да работите с Wordstat както ръчно, така и с помощта на специални програми. Ако трябва да пробиете една или две ключови фрази според статистиката на заявките на Yandex, тогава ще бъде по-лесно да отидете на сайта, посочен точно по-горе, но ако искате да съберете база данни с ключови думи за себе си по темата, от която се нуждаете, тогава автоматизацията ще бъде незаменима.
Онлайн услуга „Избор на думи“ от Yandex
Разбирам, че има повече от достатъчно публикации по темата за компилиране на семантично ядро в Интернет. Но, струва ми се, те са написани предимно от тези, които се занимават професионално с тази материя, т.е. SEO оптимизатори или фрийлансъри. Методите, които описват, са доста интересни, защото ви позволяват да автоматизирате и опростите процеса на изграждане на ядрото, но за мен лично ме карат да се отегчавам, когато чета.
Малките неща и нюанси, които описват, помагат да спестите време с голям поток от проекти, които минават през ръцете им, но ако имате задача избор на ключови думи за вашия собствен уебсайт, тогава в повечето случаи прекомерната автоматизация може дори да попречи, защото нещо може да бъде пропуснато или не взето предвид.
Тук, струва ми се, няма нужда да бързате. Например, веднъж купих чудесна програма с бонуси за партньори в печалбата Колектор на ключове. Тук. Завъртя го, завъртя го и го сложи на далечния рафт. Защо? Да, просто не е за мен - трудно е да се овладее и разбере полезността на цялата най-богата функционалност, налична в него. По същата причина използвам Yandex Metrica, а не Google Analytics.
Разбира се, греша и беше необходимо да се опре на клаксона и да се постигне разбиране на всички налични чипове в Key Collector (безусловно полезно). Но в действителност изтеглих от сайта на същия разработчик лека версия на тази програма за избор на думи, макар и под непредставимо име Slovoeb(написано с руски букви, не е много отпечатано).
Това е всичко, сега работя изключително с него и Key Collector отново ме блокира след актуализиране на системата (има връзка към компютърната конфигурация) и ме мързи отново да отпиша автора, за да го съживя.
Затова днес ще говоря само за ръчното използване на инструмента „Избор на думи“ от Yandex, за използването на Slovoeb за бързо получаване на статистика за хиляди ключови фрази наведнъж и отсяване на манекени. Има и други инструменти като Wordstat (можете да прочетете за тях в статията за), но те не са придобили толкова широка популярност.
Като цяло, разбира се, работата с Wordstat е безобразно простана теория, но доста мрачно на практика. Между другото, не толкова отдавна промениха дизайна, но не само. Според субективните усещания скоростта на разбор нова версия онлайн инструментизборът на думи се увеличи значително.
Откъде да започна? От спокойно мислене за текущата ситуация и това, което бихте искали да получите като резултат. Имате предмета на вашия ресурс (бъдещ или съществуващ). Под тази тема можете веднага да изберете дузина или две фрази или думи, които може да са свързани с нея. Как да разберете коя от фразите, които се въртят в главата ви, има перспектива?
Трябва да погледнете статистиката за тяхното използване, когато влизате в търсачката Yandex. За тази цел е необходим Wordstat. Вярно е, че напоследък той е достъпен само за регистрирани потребители, така че първо трябва да го направите и също да го добавите.
Ако вече имате цялата тази доброта, тогава няма да навреди да запомните данните си за оторизация, защото те ще трябва да бъдат въведени в Slovoeb, за да работи. След това въведете първата си заявка в съответния формуляр на страницата на услугата Избор на дума :
О, колко много се случи. Wordstat предоставя статистика за ключовите думи за последния календарен месец. Това означава, че след една година ще бъде възможно да се получи число дори с порядък по-голямо. Въпреки че това не е съвсем вярно. Една от причините може да е колебанието в честотата на заявките в зависимост от времето на годината (т.е. сезонност).
Можете да проверите това, като поставите отметка в квадратчето „История на заявките“. За по-голяма яснота, нека вземем наистина нещо с ясно изразена сезонност, където честотата на въвеждане на дадена ключова дума в низа за търсене на Yandex, в зависимост от времето на годината, може да се промени шест пъти.

Ако заявката, която ви интересува, има регионална референция, това също ще повлияе значително на честотата на нейното влизане в Yandex. За да разберете това, просто кликнете върху връзката „Всички региони“и изберете местоположението, което желаете.
Например, така ще изглежда статистиката за аудиторията на Yandex, която се интересува от доставка на пица в малък град.

Освен това много SEO специалисти и собственици на сайтове проверяват) за всякакви ключови думи и не винаги използват свои собствени за това. И това означава, че изневярата се случва(не специални) честоти. Затова не бива безразсъдно да се вярва на цифрите от тази статистика и не трябва да се приема буквално.
И без него всичко не е толкова просто. Ако беше статистика само за използването на тази една дума (фраза), която сте въвели, тогава всичко щеше да е страхотно. Но услугата за избор на думи на Yandex, когато въвеждате заявка в нея без допълнителни оператори, взема предвид на показаната фигура всички фрази, в които е използвана тази фраза (във всяка дума).
Например, ако се върнем към първата екранна снимка, можем да кажем с увереност, че почти 900 000 пъти на месец потребителите на Yandex са въвели заявки, в които е намерена думата Joomla (например „шаблони за Joomla“ или „най-популярните сайтове в света на системата за управление на съдържанието Joomla").
Това статистиката ще ви помогне да оцените перспективатасъздаване на сайт или отделен раздел по тази тема, но когато пишете конкретни статии, ще трябва да използвате други цифри, които имат повече специфика. Къде да ги вземем? Добър въпросна които сега ще се опитаме да отговорим.
Как да събираме статистика за действителната честота на заявките (оператори на Wordstat)
Преди да пристъпя към практиката, искам да се спра на тях Wordstat оператори, който може да се използва в услугата за избор на ключови думи на Yandex. Всъщност има много малко от тях. Мисля, че никой не може да разкаже за тях по-добре от собствената помощ на тази услуга.
Лично аз използвам само две от тях - кавички и удивителен знак. Вие сте свободни да правите както сметнете за добре.
Така, кавичкипринуди търсачката да споделя статистика за въвеждане само на тази фраза. Това обаче ще вземе предвид всички възможни словоформи на думите, съдържащи се в него (падежи, числа). Например така:
Странно, нали? Цифрата е намаляла три пъти. Как иначе можете да формулирате тази заявка към търсачката? Е, ако се замислите, най-вероятно е в множествено число, особено след като останалите числа могат веднага да се видят къде са отишли:
Е, с теорията, смятайте, че приключи, време е да започнете да практикувате. Всички мои проекти са с информативен характер и затова сезонността и регионалността на заявките не ме притесняват много. Ако имате различна ситуация, тогава ще трябва да вземете предвид и тези данни, за да разберете перспективите.
Какво трябва да имате предвид при сглобяването на семантичното ядро на сайта
Когато става въпрос за перспектива. Сглобяванесе състои от няколко етапа:

Когато разработвате семантично ядро, е много важно да започнете отнякъде (да се придържате към нещо). Няколко ключови фрази, взети от вашите конкуренти, взети от главата ви или очевидно предполагащи, ще бъдат вашата отправна точка. Но не забравяйте да продължите процеса на търсене и винаги имайте лист хартия под ръка, за да можете да запишете възникналата идея и след това да погледнете статистиката в услугата за избор на думи на Yandex, за да се уверите, че е валидна.
От всяка високочестотна заявка можете да използвате Wordstat или Slovoeb, за да получите десетки или дори стотици ключови думи за вашите бъдещи статии. Как да го направим? Първо трябва да намерите такива високочестотни високоговорители. Това са най-очевидните фрази, които потребителите използват, когато се свързват с Yandex, когато искат да получат отговор на въпрос по темата, в която искате да се включите в създаването на сайт.
Например за моя блог това могат да бъдат думите Joomla, WordPress, промоция на уебсайт, промоция на уебсайт, приходи и т.н. Можете да започнете с тях. Но много хора правят това, така че няма да е лошо, ако се опитате да поставите всички идеи за бъдещи статии, които идват при вас, в тези заявки, чрез които потребителите на Yandex могат да ги намерят. Трябва да се опитаме да мислим като обикновен интернет потребител, задаващ въпрос на търсачка.
Избор на думи за семето директно в Yandex Wordstat
ДОБРЕ. Водата може да се налива дълго време. Нека напишем заявката „Популяризиране на уебсайт“ в Wordstat и да видим какво може да намери за вас и мен.

невероятно Получихме много информация, която сега ще трябва да се опитаме да обработим по някакъв начин. Yandex подбра думите за нас въз основа на фразата, която въведохме, и ги разпредели в две колони. И двете са много важни.
В лявата колона на Wordstatвсички фрази, където въведените ключови думи се срещат директно, се събират. Вдясно от тях се показва честотата на заявката им от Yandex от неговите потребители. Но не бързайте да се радвате, защото тази честота в повечето случаи е фалшива (). Тези. числата написани там всъщност може да са измислица.
Как да го проверя? Е, първото нещо, което идва на ум, е да отворите друг прозорец на Wordstat в нов раздел на браузъра и да въведете всички тези фрази от лявата колона на свой ред в него, като ги оградите в кавички.

Тогава получавате реални статистики (е, или по-близки до реалните). Можете да копирате тези фрази в документ на Word или Excel и да добавите изчислените по този начин честоти.
Просто? Теоретично да, но на практика, след като проверите дузина фрази от лявата колона (от горната екранна снимка) в Wordstat, отворени в нов раздел, ще искате да отбележите всичко това и да отидете да се напиете (добре, или да се обесите) .
Рутина, не се харесва на всеки. Но лявата колона на прозореца на услугата "Избор на дума" също има пагинация. Представете си, може да има до 50 страници, което общо ще даде 2000 избрани ключови фрази. И всички те ще трябва да бъдат проверени ръчно, като ги поставите в кавички. Може би това, което е по силите на единици.
И това не е всичко. Забравихме за дясна колона на Yandex Wordstat. И това са просто невероятни неща. Той показва заявки от същите потребители, които са въвели фразата от дясната колона, направени от тях в същата сесия за търсене. Това ще ви позволи значително да разширите семантичното ядро на сайта и понякога дори в много неочаквана посока.
Какво да правим с цялото това богатство от дясната колона? Вижте съдържанието му и всички фрази, които са свързани с вашата тема, и след това ги въведете отново отворен разделбраузър с Wordstat. В нашия пример фразата „оптимизация на уебсайт“ е поразителна с висока (потенциално) честота.

И какво виждаме тук? И пак много интересни неща. От лявата колона ще трябва да проверите всички фрази за фалшиви, като поставите фразата в кавички. И съдържанието на дясната колона може да бъде проверено за намиране на нещо ново там, което все още не сте добавили към вашето семантично ядро.
И така в продължение на много часове можете да седите със страниците на услугата Yandex Word Selection, отворени в различни раздели на браузъра, за да не пропуснете нищо от потенциални ключове и в същото време да премахнете всички манекени. След време обаче ще искате да се откажете от всичко това, защото усилията и постоянството тук са нужни наистина, а не човешки.
Точно на фона на тези терзания по ръчен избор на ключови думи ще усетите красотата на Key Collector, или неговата олекотена версия, наречена Slovoeb. Каква тръпка е (без преувеличение) да вкараш в програмата някой, който ти хрумне високочестотна заявка, анализира автоматично всички страници от лявата колона на Wordstat, след което също автоматично премахва залъгалките.
Полученият списък с действително заявени ключове може да бъде сортиран в низходящ ред по честота и съхранен в CSV форматза допълнителен анализ и разбивка по статии. Между другото, процесът на разпределяне на ключови думи между статиите също може да бъде автоматизиран. Научих за това съвсем наскоро от пощенския списък на борсата ContentMonster(Напоследък купувам артикули предимно само от тях).
Оказва се, че има онлайн услуга KeyAssistantпод егидата на тази борса (безплатна е, доколкото разбирам), която ви позволява да разпръсквате ключове по страници и страници в секции. Доста дълго е да обяснявам неговата функционалност, затова предлагам да гледате „филм“ по темата и може би ще ви заинтересува:
Добре, отклонихме се, но междувременно е време да се запознаем с днешния ни герой с изключително невзрачно име.
Как да автоматизирате избора на думи от Yandex в Slovoeb
Изтеглете Slovoebможете да следвате предоставената връзка. Не изисква инсталация - просто разархивирайте изтегления архив и стартирайте файла Slovoeb.exe
Веднага след стартирането има смисъл да отидете в настройките на програмата, където в разделите „Разбор“ - „Yandex Wordstat“ в областта „Настройки на акаунта в Yandex“ще трябва да въведете поне една двойка вход-парола (разделени с двоеточие и без интервали), за да получите достъп до услугите на тази търсачка. За какво? Вече споменах, че наскоро Wordstat позволява само оторизирани потребители да го използват.

забележи, че би било по-добре да създадете нови акаунти в Yandex(фалшиви, т.е. не основните, където например работите с YAN или пари). Защо? Търсачката не позволява директно парсване на изхода си (вместо това предоставя ограничения за работата на XML изхода), така че можете да вземете бан на акаунта за проява на прекомерна наглост.
Също така има смисъл да зададете максималния брой страници от лявата колона на услугата "Избор на думи" на Yandex, които ще бъдат анализирани (50). Това ще бъде полезно при пробиване на високочестотни заявки, защото. може да има много опции там. Понякога дори на последна страницаобщата честота е няколко хиляди, което означава, че не всички ключове могат да бъдат събрани с помощта на Wordstat (за съжаление).
Ако не искате да натоварвате силно и да ядосвате Yandex, тогава в първия раздел на настройките „Общи“ увеличете обхвата на изчакване (паузи между изпращане на заявки към търсачката).

Запазете настройките и щракнете върху бутона "Създаване на проект" или върху "Отвори проект", ако не сте завършили някаква работа преди.

Дайте име на проекта и след това въведете ключовата фраза или дума, която ви интересува, в реда, който се появява. Въведено? Добре, натиснете Enter на клавиатурата.
Да, има алтернатива. Кликнете върху бутона „Лява колона на Yandex Wordstat“и въведете в отворената форма няколко фрази наведнъж (по една на ред), статистиката, за която искате да анализирате. След това натиснете бутона, разположен по-долу, и ще получите няколко списъка, обединени наведнъж.

В съвременната версия на Slovoeb ще трябва да изчакате пет минути или малко по-малко, докато се свърже с Wordstat (това се случва само след стартиране на програмата и в по-нататъшна работаняма да има такова забавяне.
След ще започне анализирането на лявата колона на услугата "Избор на дума".за тази фраза до дълбочината (броя страници), която сте задали в настройките. Винаги имам 50 инсталирани там. В резултат на това ще получите не повече от 2000 ключа, включително вашата оригинална фраза.

Например, взех супер високочестотната заявка "работа". Както можете да видите, дори на последната страница на Wordstat общата честота на фразите надхвърля десет хиляди. Следователно в този случай не можем този инструментпокриват целия набор от заявки и много остават зад кулисите. Издърпването на "опашката" също вероятно е възможно, но това вече е много по-трудно и по-малко надеждно.
И така, ние просто анализирахме ключовете, но все още трябва да отделим житото от плявата, т.е. разберете кои от тези ключови думи има смисъл да продължите да използвате в семантичното ядро и кои да отхвърлите поради тяхната изключително ниска реална честота. Последният се изчислява чрез поставяне на фразата в кавички или дори с добавяне на удивителни знаци.
В Slovoeb всичко, което трябва да направите, е да изберете бутони от падащото меню "Честоти Yandex.Wordstat"последния или предпоследния параграф. Вече трябва да разберете разликата между тях, така че изберете това, което смятате за подходящо. По някаква причина предпочитам последния вариант, но това може ненужно да ограничи резултатите.
Пробиването на реалната честота в Slovoeb е много по-бавно от анализирането и, което е важно, не отивайте в Wordstat през браузъра в момента, защото, на който тази програмазакъсах. Възможно е този проблем да възникне само на моя компютър, но все пак си струва да предупредя.
Можете да проследите процеса на проверка на реалната честота със собствените си очи - нови числа ще се появят в съответната колона в реално време. Въпреки че има смисъл да оставите този въпрос да се развие и да направите нещо по-полезно, можете само периодично да разглеждате програмата. В края на процеса на събиране червеният шестоъгълник в горния ляв ъгъл ще стане сив.

Ако желаете, вие сами можете да спрете процеса, като изберете съответния елемент от контекстно менютози бутон. Проектът може да бъде запазен и Slovoeb затворен. След това отворете отново програмата и записания проект и след това продължете да събирате статистика, като използвате описания по-горе метод. Много удобно и, най-важното, просто за позор.
Тук. След като завършите процеса, можете да сортирате резултатите в низходящ ред по честота, като щракнете върху заглавието на колоната със статистика на фрази, оградени в кавички, или с тях и удивителни знаци пред всяка дума. Ще се окаже много ясно, защото най-обещаващите (макар и често нереални поради високата конкуренция) заявки ще бъдат в горната част на списъка.

съветвам запишете всички получени в резултат на избора на ключови думисписъци за архивиране. Това става в Slovoeb с помощта на иконата, показана на екранната снимка, разположена в горната част на прозореца на програмата. Запазването е във формат CSV, който при желание може да се отвори с обикновен Excel, основното е да посочите правилния разделител на колони, така че всичко да расте заедно.
Ако не работи, тогава в настройките на програмата в раздела "Интерфейс" - "Експортиране" изберете различен формат за запазване (xlsx). Можете също така да видите разделителя, използван при експортиране в CSV.

Допълнителните колони в Excel могат да бъдат изтрити (или премахнати в същите настройки за експортиране, като просто премахнете отметките от колоните, които не ви трябват - вижте екранната снимка по-горе), така че да не намаляват видимостта. Лично аз оставям само самата ключова фраза и нейната реална честота, а всичко останало отива в пещта.

Всъщност вече можете да работите с тези списъци, като вземете нещо от там директно и пробиете нещо отново през Wordstat, за да получите нови ключове (например не пълна фраза, а дума или фраза, намерени в нея, което само по себе си може генерирайте много опции). Като цяло процесът е много креативен и поради силната си автоматизация не е много досаден, особено в сравнение с ръчния метод за използване на услугата за избор на думи, описана по-горе.
Други функции на Slovoeb за събиране на статистика
Да, забравих да го спомена Slovoeb може също да събира съвети за търсене. Това е, което отпада, когато въведете заявка в полето за търсене на Yandex или Google.

Сред тях може да има и доста интересни варианти на ключови думи, които след това могат да бъдат проверени с помощта на гореописания метод за тяхната реална честота.
Преди това имаше отделна помощна програма за това (SlovoDer) от същия разработчик (Александър Люстик), а сега тази функционалност е затворена в една програма. За да съберете предложения за търсене, просто щракнете върху съответния бутон в лентата с инструменти на Slovoeb.
В прозореца, който се отваря, трябва да поставите отметка в квадратчетата до тези търсачки, откъдето тези съвети ще потрепват.

Всъщност трябва да посочите и ключовите думи, за които ще се събират тези съвети, и да щракнете върху бутона „Започнете да събирате“. Събраните ключове от подсказките ще бъдат добавени към общия списък, така че по-късно да можете да ги проверите всички в тълпа и да съберете статистика за честотата на използване.
В общия списък те ще бъдат маркирани с различна икона, така че да можете да работите с тях по-ясно и да правите разлика между разбор на Wordstat и предложения за търсене.

Същото важи и за събиране на думи от дясната колона на Wordstat(Slovoeb също може да го анализира).

Малко по-нагоре в текста казах, че е много важно при сглобяването на семантичното ядро да се обърне внимание не само на честотата на избраните думи и фрази, но и на факта, колко висока е конкуренциятасъществува в издаването на Yandex и Google за тези заявки. Колкото по-висок е, толкова по-трудно ще ви бъде да пробиете в ТОП.
За да го оценят, мнозина предлагат да се използва броят на отговорите на търсачката, които дават на дадена заявка. Малко по-високо писах за това по-подробно. Така че нашата прекрасна програма може да анализира точно този брой отговори от резултатите от търсенето на Yandex и Google.
Тези. за всички събрани думи можете да пробиете конкуренцията им с помощта на бутон KEIв лентата с инструменти Slovoeb:

Параметърът KEI се получава и за да разчитате на него, е по-добре да използвате Key Collector ( платена версиядадено безплатна програмасъс значително по-разширена функционалност).
Както можете да видите, дори опростената версия на програмата има доста богата функционалност. Какво можем да кажем за Key Collector. Друго нещо - имате ли нужда от тази функционалност? Лично за мен се оказа много трудно да намеря време да го овладея, особено след като не виждах никакви специални перспективи в това. греша ли? Разубедете ме тогава в коментарите.
Независимо от това, не всеки има време и енергия да извърши такава работа (събиране на пълно семе), но все пак го направете задължително. Но ако има търсене, ще има и предлагане. Винаги ще има хора, които ще са готови да го направят вместо вас, друго нещо е, че те не винаги могат да бъдат честни и ефективни.
Ще си позволя наглостта и ще дам накрая видео, взето от блога на Максим Довженко, където той говори за настройките и избора на думи в Slovoeb: