Mire valók az indexek az sql-ben? Indexek az SQL Serverben
1) Az index fogalma
Index egy olyan eszköz, amely egy vagy több oszlop értékei alapján gyors hozzáférést biztosít egy táblázat soraihoz.
Ebben az operátorban nagy a változatosság, mivel nem szabványosított, mivel a szabványok nem vonatkoznak a teljesítményre.
2) Indexek létrehozása
INDEX LÉTREHOZÁSA
TOVÁBB()
3) Indexek módosítása és törlése
Az operátor az indextevékenység vezérlésére szolgál:
ALTER INDEX
Az index eltávolításához használja az operátort:
DROP INDEX
a) Táblaválasztási szabályok
1. Olyan táblázatokat célszerű indexelni, amelyekben a sorok legfeljebb 5%-a van kijelölve.
2. Indexelje azokat a táblákat, amelyek nem tartalmaznak ismétlődést a SELECT utasítás WHERE záradékában.
3. Nem praktikus a gyakran frissített táblázatok indexelése.
4. Nem célszerű olyan táblázatokat indexelni, amelyek legfeljebb 2 oldalt foglalnak el (az Oracle esetében ez kevesebb, mint 300 sor), mivel a teljes vizsgálat nem tart tovább.
b) Oszlopkiválasztási szabályok
1. Elsődleges és idegen kulcsok – gyakran használják táblák összekapcsolására, adatok kiválasztására és keresésre. Ezek mindig egyedi indexek, maximális hasznossággal
2. A hivatkozási integritás opciók használatakor mindig szükség van egy indexre az FK-n.
3. Oszlopok, amelyek alapján az adatokat gyakran rendezik és/vagy csoportosítják.
4. A SELECT utasítás WHERE záradékában gyakran keresett oszlopok.
5. Ne hozzon létre indexeket a hosszú leíró oszlopokhoz.
c) Összetett indexek létrehozásának elvei
1. Az összetett indexek akkor jók, ha az oszlopoknak egyenként kevés egyedi értéke van, és az összetett index nagyobb egyediséget biztosít.
2. Ha a SELECT utasítással kiválasztott összes érték az összetett indexhez tartozik, akkor az értékeket az indexből választjuk ki.
3. Létre kell hoznia egy összetett indexet, ha a WHERE záradék két vagy több értéket használ ÉS operátorral kombinálva.
d) Nem ajánlott létrehozni
Nem ajánlott indexeket létrehozni olyan oszlopokon, beleértve az összetetteket is, amelyek:
1. Ritkán használják a lekérdezések eredményeinek keresésére, egyesítésére és rendezésére.
2. Tartalmazzon gyakran változó értékeket, ami megköveteli az index gyakori frissítését, ami lassítja az adatbázis teljesítményét.
3. Tartalmaz sz nagyszámú egyedi értékek (kevesebb, mint 10% m/f) vagy az egy vagy két értékkel rendelkező sorok túlnyomó száma (a szállító lakóhelye Moszkva).
4. A WHERE záradékban függvények vagy kifejezések kerülnek rájuk, és az index nem működik.
e) Ne felejtsd el
Törekedni kell az indexek számának csökkentésére, mivel nagy számuk csökkenti az adatok frissítésének sebességét. Tehát MS SQL szerver táblázatonként legfeljebb 16 index létrehozását javasolja.
Általában az indexek a hivatkozási integritás lekérdezésére és fenntartására jönnek létre.
Ha egy indexet nem használnak lekérdezésekhez, akkor azt el kell dobni, és triggerekkel kell érvényesíteni a hivatkozási integritást.
Először is azt javaslom megérteni, mi az kiterjedő index, adok egy részletet egy Habréval kapcsolatos cikkből:
Miért használjunk lefedő indexet az összetett index helyett?
Először is győződjünk meg arról, hogy megértjük a köztük lévő különbséget.
Összetett index ez csak egy normál index, amely egynél több oszlopot tartalmaz. Több kulcsoszlop használható az egyes táblasorok egyediségének biztosítására, az is előfordulhat, hogy az elsődleges kulcs több oszlopból áll az egyediség biztosítása érdekében, vagy a gyakran hívott lekérdezések több oszlopon történő végrehajtását próbálja optimalizálni. Általában azonban minél több kulcsoszlopot tartalmaz egy index, annál kevésbé hatékony az index, ezért az összetett indexeket megfontoltan kell használni.Mint már említettük, egy lekérdezés óriási előnyökkel járhat, ha minden szükséges adat azonnal megtalálható az index lapjain, akárcsak maga az index. Ez nem jelent problémát a fürtözött indexeknél, mint pl minden adat már megvan (ezért olyan fontos, hogy alaposan átgondolja, amikor fürtözött indexet hoz létre). A levelek nem fürtözött indexe azonban csak a kulcsoszlopokat tartalmazza. A lekérdezésoptimalizálónak további lépésekre van szüksége az összes többi adat eléréséhez, ami jelentős többletköltséget okozhat a lekérdezések futtatásához.
Ahol kiterjedő index segítségére siet. Ha nem fürtözött indexet definiál, a kulcsfontosságú oszlopok mellett további oszlopokat is megadhat.
Így a fedőindex nem tartalmazhatja az indexfa szerkezetében található összes kiválasztható lekérdezési oszlopot, hanem csak azokat, amelyek a lekérdezésben az adatok szűrésére vagy csoportosítására szolgálnak, a SELECT záradékból származó többi oszlopot az INCLUDE index szekcióba kell helyezni.
Hasznosnak találhatja a választ egy másik kérdésben.
A fenti példában egy 3 mezős összetett indexet használunk a fedőindex helyett, a lefedő index létrehozásának kódja a következő:
NEM CLUSTERED INDEX LÉTREHOZÁSA ON . (ASC) TARTALMAZZA (, ) WITH-vel (PAD_INDEX=OFF, STATISTICS_NORECOMPUTE=OFF, SORT_IN_TEMPDB=OFF, IGNORE_DUP_KEY=OFF, DROP_EXISTING=OFF, ONLINE=KI, ALLOW_ROW_LOCKS=ON, ALLOWON_PON)_LOCKONP
Kérdésedre válaszolva:
fedőindex esetén az INCLUDE záradék oszlopainak sorrendje nem fontos, de az oszlopsorrend fontos az összetett index szempontjából, mert az oszlopadatok oszlopsorrendben kerülnek az indexfába, és a lekérdezésoptimalizáló nem tud kétoszlopos indexet használni csak a 2 oszlopos értékek megkeresésére. Az ábrán láthat egy szemléltető példát arra, hogyan fog kinézni egy 2 oszlopból álló indexstruktúra (EMPLOYEE_ID, SUBSIDIARY_ID).
6. Indexek és teljesítményoptimalizálás
Indexek az adatbázisokban: cél, hatás a teljesítményre, indexek létrehozásának elvei
6.1 Miért van szükség indexekre?
Az indexek olyan speciális struktúrák az adatbázisokban, amelyek lehetővé teszik a keresés és a rendezés felgyorsítását egy adott mező vagy mezőkészlet alapján egy táblázatban, valamint az adatok egyediségének biztosítására is szolgálnak. Az indexek összehasonlításának legegyszerűbb módja a könyvekben található indexekkel. Ha nincs mutató, akkor az egész könyvet át kell néznünk, hogy megtaláljuk a megfelelő helyet, és egy mutató segítségével ugyanaz a művelet sokkal gyorsabban végrehajtható.
Általában minél több index, annál jobb az adatbázis-lekérdezések teljesítménye. Az indexek számának túlzott növekedésével azonban az adatmódosítási műveletek (beszúrás/módosítás/törlés) teljesítménye csökken, az adatbázis mérete megnő, ezért az indexek hozzáadásával óvatosan kell bánni.
Néhány Általános elvek indexek létrehozásával kapcsolatban:
· Indexeket kell létrehozni az összeillesztéseknél használt oszlopokhoz, amelyeket gyakran keresnek és rendeznek. Meg kell jegyezni, hogy az indexek mindig automatikusan jönnek létre azokhoz az oszlopokhoz, amelyekre az elsődleges kulcs megkötése vonatkozik. Leggyakrabban idegen kulccsal rendelkező oszlopokhoz is létrejönnek (az Accessben - automatikusan);
Az indexnek benne kell lennie automatikus üzemmód olyan oszlopokhoz készült, amelyek egyedi megszorítással rendelkeznek;
· A legjobb, ha indexeket hoz létre azokhoz a mezőkhöz, amelyekben - az ismétlődő értékek minimális száma és az adatok egyenletesen oszlanak el. Az Oracle speciális bitindexekkel rendelkezik az oszlopokhoz nagy mennyiség duplikált értékek esetén az SQL Server és az Access nem biztosít ilyen típusú indexet;
· ha a keresést folyamatosan egy bizonyos oszlopkészleten hajtják végre (egy időben), akkor ebben az esetben érdemes lehet összetett indexet létrehozni (csak SQL Serverben) - egy indexet egy oszlopcsoporthoz;
· Ha módosítja a táblákat, akkor a táblában megadott indexek automatikusan megváltoznak. Ennek eredményeként az index erősen töredezett lehet, ami befolyásolja a teljesítményt. Az indexeket rendszeresen ellenőrizni kell töredezettség szempontjából, és töredezettségmentesíteni kell. Nagy mennyiségű adat betöltésekor néha érdemes először eltávolítani az összes indexet, majd a művelet befejezése után újra létrehozni;
· Indexek nem csak táblákhoz, hanem nézetekhez is készíthetők (csak SQL Serverben). Előnyök - a mezők kiszámításának lehetősége nem a kérés időpontjában, hanem az új értékek táblázatokban való megjelenése idején.
A nagy teljesítmény elérésének egyik legfontosabb módja SQL szerver az indexek használata. Az index felgyorsítja a lekérdezési folyamatot azáltal, hogy gyors hozzáférést biztosít egy táblázat adatsoraihoz, hasonlóan a könyvben található indexekhez, amelyek segítségével gyorsan megtalálhatja a szükséges információkat. Ebben a cikkben megadom rövid áttekintés indexek be SQL szerverés magyarázza el, hogyan vannak elrendezve az adatbázisban, és hogyan segítik felgyorsítani az adatbázis-lekérdezéseket.Az indexek táblázatok és nézetek oszlopaiban jönnek létre. Az indexek segítségével gyorsan megkeresheti az adatokat az oszlopok értékei alapján. Például, ha létrehoz egy indexet az elsődleges kulcson, majd megkeresi az adatsort az elsődleges kulcs értékeivel, akkor SQL szerver először megkeresi az index értékét, majd az index segítségével gyorsan megkeresi a teljes adatsort. Index nélkül az összes táblasor teljes kikeresése (ellenőrzése) megtörténik, ami jelentős hatással lehet a teljesítményre.
A táblázat vagy nézet legtöbb oszlopához létrehozhat indexet. A kivétel főleg a nagy objektumok tárolására szolgáló adattípusokat tartalmazó oszlopok ( FAJANKÓ), mint például kép, szöveg vagy varchar (max). Indexeket is létrehozhat az adatok formátumban való tárolására szolgáló oszlopokon XML, de ezek az indexek egy kicsit másképpen vannak elrendezve, mint a szabványosak, és ezek figyelembevétele meghaladja e cikk kereteit. Ezenkívül a cikk nem terjed ki oszloptár indexek. Ehelyett az adatbázisokban leggyakrabban használt indexekre összpontosítok. SQL szerver.
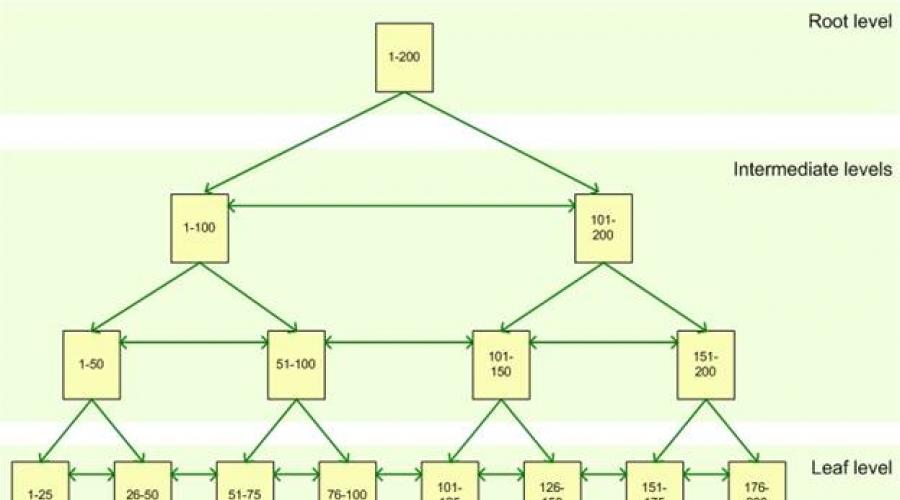
Az index oldalak halmazából, indexcsomópontokból áll, amelyek egy fastruktúrába vannak rendezve - kiegyensúlyozott fa. Ez a struktúra hierarchikus jellegű, és egy gyökércsomóponttal kezdődik a hierarchia tetején, a végcsomópontokkal pedig alul, ahogy az ábrán látható: 
Ha egy indexelt oszlopot kérdez le, a lekérdezőmotor a gyökércsomópont tetején indul, és fokozatosan lefelé halad a közbenső csomópontokon, és a középső réteg minden rétege részletesebb információkat tartalmaz az adatokról. A lekérdezési alrendszer továbbra is mozog az index csomópontjain, amíg el nem éri az index leveleivel az alsó szintet. Ha például a 123-as értéket keresi egy indexelt oszlopban, akkor a lekérdezőmotor először a gyökérszinten határozza meg az oldalt az első köztes szinten. Ebben az esetben az első oldal 1 és 100 közötti értékre mutat, a második oldal pedig 101 és 200 közötti értékre, tehát a lekérdezőmotor ennek a középszintnek a második oldalára fog hivatkozni. Ezt követően tisztázásra kerül, hogy a következő középszint harmadik oldalára kell hivatkoznia. Innentől kezdve a lekérdezési alrendszer az alsó szinten magának az indexnek az értékét olvassa be. Az indexlapok tartalmazhatják magukat a táblázatadatokat és csak egy mutatót a táblázatban lévő adatokat tartalmazó sorokra, az index típusától függően: fürtözött vagy nem fürtözött.
Klaszteres index
A fürtözött index a tényleges adatsorokat az index leveleiben tárolja. Visszatérve az előző példához, ez azt jelenti, hogy a 123-as kulcsértékhez tartozó adatsort magában az indexben tároljuk. Fontos jellemző A fürtözött index azt jelenti, hogy minden érték meghatározott sorrendben van rendezve, akár növekvő, akár csökkenő sorrendben. Így egy táblának vagy nézetnek csak egy fürtözött indexe lehet. Ezenkívül meg kell jegyezni, hogy a táblázatban szereplő adatok csak akkor tárolódnak rendezett formában, ha ehhez a táblához fürtözött indexet hoztak létre.A fürtözött index nélküli táblát kupacnak nevezzük.
Nem klaszterezett index
A fürtözött indexekkel ellentétben a nem csoportosított index levelei csak azokat az oszlopokat tartalmazzák ( kulcs), amely szerint adott index, és tartalmaz egy mutatót is a táblázat tényleges adatokat tartalmazó soraira. Ez azt jelenti, hogy a lekérdező rendszernek további műveletre van szüksége a kért adatok megkereséséhez és lekéréséhez. Az adatmutató tartalma az adatok tárolásának módjától függ: fürtözött tábla vagy kupac. Ha a mutató egy fürtözött táblára mutat, akkor egy fürtözött indexre mutat, amely a valós adatok megkeresésére használható. Ha a mutató egy kupacra hivatkozik, akkor egy adott adatsor-azonosítóra mutat. A nem fürtözött indexek nem rendezhetők, ellentétben a fürtözöttekkel, azonban egy táblán vagy nézeten egynél több nem fürtözött index is létrehozható, legfeljebb 999-ig. Ez nem jelenti azt, hogy minél több indexet kell létrehoznia. Az indexek javíthatják vagy ronthatják a rendszer teljesítményét. Amellett, hogy több nem fürtözött indexet is létrehozhat, további oszlopokat is beilleszthet ( tartalmazza oszlop). Ez a megközelítés lehetővé teszi, hogy megkerülje az indexre vonatkozó bizonyos korlátozásokat. Például engedélyezhet egy nem indexelt oszlopot, vagy megkerülheti az indexhossz-korlátot (a legtöbb esetben 900 bájt).Index típusok
Amellett, hogy fürtözött vagy nem fürtözött, az index tovább konfigurálható összetett indexként, egyedi indexként vagy lefedő indexként.Összetett index
Egy ilyen index egynél több oszlopot is tartalmazhat. Egy indexben legfeljebb 16 oszlop szerepelhet, de ezek teljes hossza 900 bájt lehet. A fürtözött és a nem fürtözött indexek is lehetnek összetettek.Egyedi index
Egy ilyen index biztosítja, hogy az indexelt oszlop minden értéke egyedi legyen. Ha az index összetett, akkor az egyediség az index összes oszlopára vonatkozik, de nem az egyes oszlopokra. Például, ha egyedi indexet hoz létre az oszlopokon NÉVÉs VEZETÉKNÉV, akkor a teljes névnek egyedinek kell lennie, de az utó- vagy vezetéknévben külön-külön is előfordulhatnak ismétlődések.Egy egyedi index automatikusan létrejön, amikor megadja az oszlopkényszereket: elsődleges kulcs vagy egyedi értékkényszer:
- elsődleges kulcs
Amikor egy vagy több oszlopban meghatároz egy elsődleges kulcs kényszert, akkor SQL szerver automatikusan létrehoz egy egyedi fürtözött indexet, ha még nem hoztak létre fürtözött indexet (ebben az esetben egyedi, nem fürtözött indexet hoz létre az elsődleges kulcs) - Az értékek egyedisége
Amikor korlátozza az értékek egyediségét, akkor SQL szerver automatikusan létrehoz egy egyedi, nem fürtözött indexet. Megadhatja, hogy egyedi fürtözött index jöjjön létre, ha még nem jött létre fürtözött index a táblában
Borító index
Egy ilyen index lehetővé teszi, hogy egy adott lekérdezés azonnal megkapja az összes szükséges adatot az index leveleiből anélkül, hogy magának a tábla rekordjainak további hívása lenne.Index tervezés
Bármennyire is hasznosak az indexek, gondosan kell megtervezni őket. Mivel az indexek sok lemezterületet foglalhatnak el, nem kíván több indexet létrehozni, mint amennyire szüksége van. Ezenkívül az indexek automatikusan frissülnek, amikor magának az adatsornak a frissítése megtörténik, ami további erőforrás-ráfordításhoz és teljesítményromláshoz vezethet. Az indexek tervezésekor számos szempontot figyelembe kell venni az adatbázissal és a lekérdezésekkel kapcsolatban.Adatbázis
Ahogy korábban megjegyeztük, az indexek javíthatják a rendszer teljesítményét, mivel gyors adatkeresési módot biztosítanak a lekérdezőmotornak. Ugyanakkor azt is figyelembe kell vennie, hogy milyen gyakran fog adatokat beszúrni, frissíteni vagy törölni. Az adatok módosításakor az indexeket is módosítani kell, hogy tükrözzék az adatokon végrehajtott megfelelő műveleteket, amelyek jelentősen ronthatják a rendszer teljesítményét. Az indexelési stratégia tervezésekor vegye figyelembe a következő irányelveket:- A gyakran frissített táblákhoz használjon a lehető legkevesebb indexet.
- Ha a tábla nagy mennyiségű adatot tartalmaz, de azok változásai jelentéktelenek, akkor használjon annyi indexet, amennyi szükséges a lekérdezések teljesítményének javításához. Azonban alaposan gondolja át, mielőtt indexeket használna kis táblákon, pl talán az indexkeresés használata tovább tart, mint az összes sor átvizsgálása.
- A fürtözött indexeknél próbálja meg a mezőket a lehető legrövidebbre tartani. A legjobb gyakorlat az lenne, ha fürtözött indexet használna azokon az oszlopokon, amelyek egyedi értékekkel rendelkeznek, és nem engedélyezik a nullákat. Ez az oka annak, hogy az elsődleges kulcsot gyakran használják fürtözött indexként.
- Az oszlopban lévő értékek egyedisége befolyásolja az index teljesítményét. Általában minél több ismétlődés van egy oszlopban, annál rosszabbul teljesít az index. Másrészt minél egyedibb az érték, annál jobb az index állapota. Lehetőség szerint használjon egyedi indexet.
- Összetett index esetén vegye figyelembe az index oszlopainak sorrendjét. Kifejezésekben használt oszlopok AHOL(Például, WHERE Keresztnév = "Charlie") legyen az első az indexben. A következő oszlopokat értékük egyedisége szerint kell felsorolni (a legtöbb egyedi értéket tartalmazó oszlopok az elsők).
- A számított oszlopokon indexet is megadhat, ha megfelelnek bizonyos követelményeknek. Például az oszlop értékének lekérésére használt kifejezéseknek determinisztikusnak kell lenniük (mindig ugyanazt az eredményt adják vissza egy adott bemeneti paraméterkészlethez).
Adatbázis lekérdezések
Egy másik szempont az indexek tervezésekor, hogy milyen lekérdezéseket hajtanak végre az adatbázisban. Mint korábban említettük, figyelembe kell vennie, hogy az adatok milyen gyakran változnak. Ezenkívül a következő elveket kell alkalmazni:- Próbálja meg a lehető legtöbb sort beszúrni vagy módosítani egyetlen lekérdezésben, ahelyett, hogy több lekérdezésben tenné.
- Hozzon létre egy nem fürtözött indexet azokon az oszlopokon, amelyeket gyakran használ a lekérdezésekben keresési kifejezésként AHOLés csatlakozások benne CSATLAKOZIK.
- Fontolja meg a sorkeresési lekérdezésekben használt oszlopok indexelését a pontos értékegyeztetés érdekében.
És most valójában:
14 SQL Server indexkérdés, amelyet túlságosan zavarban volt feltenni
Miért nem lehet egy táblának két fürtözött indexe?
Rövid választ szeretne? A fürtözött index a táblázat. Ha fürtözött indexet hoz létre egy táblán, a tárolási alrendszer a tábla összes sorát növekvő vagy csökkenő sorrendbe rendezi, az index meghatározása szerint. A fürtözött index nem egy különálló entitás, mint más indexek, hanem egy mechanizmus az adatok táblában való rendezésére és megkönnyítésére gyors hozzáférés adatvonalakhoz.Képzeljük el, hogy van egy táblázata, amely az értékesítési tranzakciók előzményeit tartalmazza. Az Értékesítési táblázat olyan információkat tartalmaz, mint a rendelésazonosító, a cikk pozíciója a rendelésben, a cikkszám, a cikk mennyisége, a rendelés száma és dátuma stb. Egy fürtözött indexet hoz létre az oszlopokon Rendelés azonosítóÉs LineID, növekvő sorrendbe rendezve az alábbiak szerint T-SQL kód:
EGYEDI KLUSTERES INDEX LÉTREHOZÁSA ix_oriderid_lineid ON dbo.Sales(Rendelésazonosító, Sorazonosító);
A szkript futtatásakor a tábla összes sora fizikailag először az OrderID oszlop, majd a LineID alapján lesz rendezve, de az adatok egyetlen logikai blokkban, a táblázatban maradnak. Emiatt nem hozhat létre két fürtözött indexet. Csak egy tábla lehet ugyanazokkal az adatokkal, és ez a tábla csak egyszer rendezhető egy adott sorrendben.
Ha egy fürtözött tábla számos előnnyel jár, miért használjunk kupacot?
Igazad van. A fürtözött táblák eltérőek, és a legtöbb lekérdezés jobban teljesít a fürtözött indexszel rendelkező táblákon. De bizonyos esetekben érdemes lehet hagyni a táblázatokat a természetes állapotukban, pl. kupacként, és csak nem fürtözött indexeket hozzon létre, hogy a lekérdezések futhassanak.Ne feledje, a kupac véletlenszerű sorrendben tárolja az adatokat. Általában a tárolási alrendszer a beillesztés sorrendjében adja hozzá az adatokat egy táblához, de a tárolási alrendszer is szeret sorokat mozgatni a hatékonyabb tárolás érdekében. Ennek eredményeként esélye sincs megjósolni az adatok tárolási sorrendjét.
Ha a lekérdezőmotornak a nem fürtözött index előnyei nélkül kell adatokat találnia, akkor teljes táblázatvizsgálatot végez, hogy megtalálja a szükséges sorokat. Nagyon kis asztalokon ez általában nem jelent problémát, de ahogy a kupac mérete nő, a teljesítmény gyorsan csökken. Természetesen egy nem fürtözött index segíthet, ha egy mutatót használ arra a fájlra, oldalra és sorra, ahol a szükséges adatok tárolódnak - általában sok. legjobb alternatíva táblázat szkennelés. Még így is nehéz összehasonlítani a fürtözött index előnyeivel, ha figyelembe vesszük a lekérdezés teljesítményét.
A kupac azonban bizonyos helyzetekben segíthet a teljesítmény javításában. Vegyünk egy táblázatot sok beszúrással, de kevés frissítéssel vagy törléssel. Például egy naplótáblázat elsősorban értékek beszúrására szolgál, amíg archiválásra nem kerül. Egy kupacban nem látja az oldalszámozást és az adatok töredezettségét, mint a fürtözött indexeknél, mivel a sorok egyszerűen hozzáadódnak a kupac végéhez. A túl nagy oldalválasztás jelentős hatással lehet a teljesítményre, és nem a legjobb módon. Általában véve a kupac viszonylag fájdalommentessé teszi az adatok beszúrását, és nem kell foglalkoznia a fürtözött indexek tárolási és karbantartási költségeivel.
De nem az adatok frissítésének és törlésének hiánya tekinthető az egyetlen oknak. Az adatok mintavételének módja szintén fontos tényező. Például ne használjon kupacot, ha gyakran kérdez le adattartományokat, vagy ha a kért adatokat gyakran kell rendezni vagy csoportosítani.
Mindez azt jelenti, hogy csak akkor érdemes fontolóra vennie a kupac használatát, ha rendkívül kis táblákkal dolgozik, különben a táblával való teljes interakció az adatok beszúrására korlátozódik, és a lekérdezések rendkívül egyszerűek (és továbbra is nem fürtözött indexeket használ). Ellenkező esetben maradjon egy jól megtervezett fürtözött indexnél, például egy egyszerű növekvő kulcsmezőben definiáltnál, mint egy széles körben használt oszlopot. IDENTITÁS.
Hogyan módosítható az alapértelmezett indexkitöltési tényező értéke?
Az alapértelmezett indexkitöltési tényező megváltoztatása egy dolog. Az alapértelmezett arány működésének megértése egy másik kérdés. De először pár lépést hátra. Az index kitöltési tényezője határozza meg, hogy oldalanként mekkora területet kell tárolni az index legalacsonyabb szintjén (levélszinten), mielőtt elkezdené a feltöltést. új oldal. Például, ha az együttható 90-re van állítva, akkor az index növekedésével az oldal 90%-át fogja elfoglalni, majd a következő oldalra lép.Alapértelmezés szerint az indexkitöltés értéke beleszámít SQL szerver 0, ami egyenlő 100-zal. Ennek eredményeként minden új index automatikusan örökli ezt a beállítást, hacsak nem ad meg kifejezetten a rendszer alapértelmezésétől eltérő értéket a kódban, vagy nem módosítja az alapértelmezett viselkedést. Te tudod használni SQL Server Management Studio az alapértelmezett érték módosításához, vagy futtasson egy rendszerben tárolt eljárást sp_configure. Például a következő készlet T-SQL parancs az együttható értékét 90-re állítja (először át kell váltani a speciális beállítások módba):
EXEC sp_configure "show speciális beállítások", 1; GO RECONFIGURE; GO EXEC sp_configure "kitöltési tényező", 90; GO RECONFIGURE; MEGY
Az indexkitöltési tényező értékének módosítása után újra kell indítani a szolgáltatást SQL szerver. Most ellenőrizheti a beállított értéket az sp_configure futtatásával a második argumentum megadása nélkül:
EXEC sp_configure "kitöltési tényező" GO
Ennek a parancsnak 90 értéket kell visszaadnia. Ennek eredményeként az összes újonnan létrehozott index ezt az értéket fogja használni. Ezt úgy tesztelheti, hogy létrehoz egy indexet, és lekérdezi a kitöltési tényező értékét:
HASZNÁLATA AdventureWorks2012; -- az adatbázisod GO CREATE NONCLUSTERED INDEX ix_people_lastname ON Person.Person(LastName); GO SELECT fill_factor FROM sys.indexes WHERE objektum_azonosító = objektum_azonosító("Személy.Személy") AND name="ix_people_lastname";
BAN BEN ezt a példát létrehoztunk egy nem fürtözött indexet a táblán személy az adatbázisban AdventureWorks2012. Az index létrehozása után a sys.indexes rendszertáblákból megkaphatjuk a kitöltési tényező értékét. A kérésnek 90-et kell visszaadnia.
Képzeljük el azonban, hogy eldobtuk az indexet, és újra létrehoztuk, de most megadtunk egy konkrét kitöltési tényező értéket:
CREATE NONCLUSTERED INDEX ix_people_lastname ON Személy.Személy(Vezetéknév) WITH (fillfactor=80); GO SELECT fill_factor FROM sys.indexes WHERE objektum_azonosító = objektum_azonosító("Személy.Személy") AND name="ix_people_lastname";
Ezúttal utasításokat adtunk hozzá VAL VELés opció kitöltési tényező indexkészítési műveletünkhöz INDEX LÉTREHOZÁSAés 80 értéket adott meg. Operátor KIVÁLASZTÁS most a megfelelő értéket adja vissza.
Eddig elég egyenesen ment. Ebben az egész folyamatban igazán megéghet, ha az alapértelmezett faktorértékkel indexet hoz létre, feltételezve, hogy ismeri az értéket. Például valaki elrontja a szerver beállításait, és annyira makacs, hogy az indexkitöltési tényező értékét 20-ra állítja. Addig is folytatja az indexek létrehozását, 0 alapértelmezett értéket feltételezve. Sajnos addig nincs módod kideríteni az együttható értékét, amíg nem hoz létre indexet, majd ellenőrzi az értéket, ahogy a példákban is tettük. Ellenkező esetben meg kell várnia, amíg a lekérdezés teljesítménye annyira leesik, hogy gyanakodni kezd valamire.
Egy másik probléma, amellyel tisztában kell lennie, az index-újraépítés. Az index létrehozásához hasonlóan az index újraépítésekor megadhatja az index kitöltési tényezőjének értékét. Az index létrehozása paranccsal ellentétben azonban az újraépítés nem használja az alapértelmezett kiszolgálóbeállításokat, bár úgy tűnhet. Még inkább, ha nem ad meg konkrétan egy indexkitöltési tényező értéket, akkor SQL szerver annak az együtthatónak az értékét fogja használni, amellyel az index az újjáépítése előtt létezett. Például a következő művelet ALTER INDEXújraépíti az imént létrehozott indexet:
ALTER INDEX ix_people_lastname ON Személy.Személy REBUILD; GO SELECT fill_factor FROM sys.indexes WHERE objektum_azonosító = objektum_azonosító("Személy.Személy") AND name="ix_people_lastname";
A kitöltési tényező értékének ellenőrzésekor 80-as értéket kapunk, mert ezt adtuk meg az index utolsó létrehozásakor. Az alapértelmezett értéket figyelmen kívül hagyja.
Mint látható, az indexkitöltési tényező értékének megváltoztatása nem olyan nehéz dolog. Sokkal nehezebb tudni jelenlegi értékés megérti, mikor érvényes. Ha az indexek létrehozásakor és újraépítésekor mindig megad egy adott arányt, akkor mindig ismeri a konkrét eredményt. Hacsak nem kell megbizonyosodnod arról, hogy valaki más ne csavarja el újra a szerver beállításait, ami miatt az összes index nevetségesen alacsony indexkitöltési tényezővel újjáépül.
Lehetséges-e fürtözött indexet létrehozni egy duplikátumokat tartalmazó oszlopon?
Igen és nem. Igen, létrehozhat fürtözött indexet egy ismétlődő értékeket tartalmazó kulcsoszlopon. Nem, a kulcsoszlop értéke nem maradhat nem egyedi állapotban. Hadd magyarázzam. Ha nem egyedi fürtözött indexet hoz létre egy oszlopon, akkor a tárolási alrendszer egész számot (egyediséget) ad az ismétlődő értékhez, hogy biztosítsa az egyediséget, és ennek megfelelően a fürtözött tábla minden sorát azonosítani lehessen.Dönthet például úgy, hogy fürtözött indexet hoz létre az oszlop ügyféladattáblázatában vezetéknév tartja a vezetéknevet. Az oszlop olyan értékeket tartalmaz, mint Franklin, Hancock, Washington és Smith. Ezután ismét beilleszti az Adams, Hancock, Smith és Smith értékeket. De a kulcsoszlop értékének egyedinek kell lennie, ezért a tárolási alrendszer megváltoztatja a duplikátumok értékét, hogy azok valahogy így nézzenek ki: Adams, Franklin, Hancock, Hancock1234, Washington, Smith, Smith4567 és Smith5678.
Első pillantásra ez a megközelítés normálisnak tűnik, de az egész érték növeli a kulcs méretét, ami nagyszámú ismétlődés esetén problémát jelenthet, és ezek az értékek egy nem fürtözött index vagy referencia alapjává válnak. idegen kulcs. Ezen okok miatt, amikor csak lehetséges, próbáljon meg egyedi fürtözött indexeket létrehozni. Ha ez nem lehetséges, akkor legalább próbáljon meg olyan oszlopokat használni, amelyekben nagyon magas az egyedi értékek tartalma.
Hogyan kerül tárolásra a tábla, ha nincs fürtözött index?
SQL szerver kétféle táblát támogat: a fürtözött táblákat, amelyek fürtözött indexel rendelkeznek, és a kupactáblákat vagy csak kupacokat. A fürtözött táblákkal ellentétben a kupacban lévő adatok semmilyen módon nincsenek rendezve. Valójában ez egy halom (halom) adat. Ha egy sort ad hozzá egy ilyen táblázathoz, a tároló alrendszer egyszerűen hozzáadja azt az oldal végéhez. Ha az oldal tele van adatokkal, akkor az új oldalra kerül. A legtöbb esetben érdemes fürtözött indexet létrehozni egy táblán, hogy kihasználja a rendezési és lekérdezési sebességet (próbáld elképzelni, hogy telefonszám V címjegyzék, semmilyen elv szerint nem rendezve). Ha azonban úgy dönt, hogy nem hoz létre fürtözött indexet, akkor is létrehozhat egy nem fürtözött indexet a kupacban. Ebben az esetben minden indexsornak egy kupacsorra mutató mutatója lesz. Az index tartalmazza a fájlazonosítót, az oldalszámot és az adatsorszámot.Mi a kapcsolat az egyedi értékmegszorítások és az elsődleges kulcs között a táblaindexekkel?
Az elsődleges kulcs és az egyedi megszorítás biztosítja, hogy az oszlopban lévő értékek egyediek legyenek. Táblánként csak egy elsődleges kulcs hozható létre, és nem tartalmazhat értékeket. NULLA. Több megszorítást is létrehozhat egy tábla egyedi értékére vonatkozóan, és mindegyikhez egyetlen bejegyzés tartozhat NULLA.Az elsődleges kulcs létrehozásakor a tárolási alrendszer egyedi fürtözött indexet is létrehoz, ha még nem jött létre fürtözött index. Azonban felülbírálhatja az alapértelmezett viselkedést, és akkor létrejön egy nem fürtözött index. Ha az elsődleges kulcs létrehozásakor létezik fürtözött index, akkor egy egyedi, nem fürtözött index jön létre.
Egyedi megszorítás létrehozásakor a tárolómotor egyedi, nem fürtözött indexet hoz létre. Dönthet azonban úgy, hogy létrehoz egy egyedi fürtözött indexet, ha még nem jött létre.
Általánosságban elmondható, hogy az egyedi értékkényszer és az egyedi index ugyanaz.
Miért nevezik a fürtözött és nem fürtözött indexeket B-Tree-nek az SQL Serverben?
Az SQL Server alapvető indexei, akár fürtözöttek, akár nem fürtözöttek, az indexcsomópontoknak nevezett oldalkészletek között vannak elosztva. Ezek az oldalak egy meghatározott hierarchiába vannak rendezve egy kiegyensúlyozott fának nevezett fastruktúrával. Tovább felső szint a gyökércsomópont az alján, a levél csomópontjai, közbenső csomópontokkal a felső és alsó szint között, amint az az ábrán látható:A gyökércsomópont biztosítja a fő belépési pontot azokhoz a lekérdezésekhez, amelyek egy indexen keresztül próbálnak lekérni adatokat. Ebből a csomópontból kiindulva a lekérdezőmotor hierarchikus bejárást kezdeményez az adatokat tartalmazó megfelelő végcsomópontig.
Tegyük fel például, hogy van egy kérés a 82-es kulcsértéket tartalmazó sorok lekérésére. A lekérdezési alrendszer a gyökércsomópontnál kezdődik, amely egy megfelelő köztes csomópontra mutat, esetünkben 1-100. Az 1-100 közbülső csomópontból átmenet van az 51-100 csomópontba, onnan pedig a 76-100 végső csomópontba. Ha fürtözött indexről van szó, akkor a csomópont levele a 82-vel megegyező kulcshoz tartozó sor adatait tartalmazza. Ha nem fürtözött indexről van szó, akkor az index levele egy fürtözött táblára vagy a kupac egy adott sorára mutató mutatót tartalmaz.
Általában hogyan javíthatja egy index a lekérdezés teljesítményét, ha végig kell mennie ezeken az indexcsomópontokon?
Először is, az indexek nem mindig javítják a teljesítményt. A túl sok helytelenül létrehozott index ingoványsá teszi a rendszert, és rontja a lekérdezések teljesítményét. Helyesebb lenne azt mondani, hogy ha az indexeket körültekintően alkalmazzák, jelentős teljesítménynövekedést érhetnek el.Gondolj egy hatalmas könyvre, amely a teljesítményhangolásról szól SQL szerver(papír, nem az elektronikus változat). Képzelje el, hogy információkat szeretne találni az erőforrás-irányító konfigurálásával kapcsolatban. Laponként mozgathatja az ujját a teljes könyvben, vagy megnyithatja a tartalomjegyzéket, és megtudhatja a keresett információ pontos oldalszámát (feltételezve, hogy a könyv megfelelően indexelve van, és a tartalomjegyzékben a megfelelő indexek vannak). Ezzel persze rengeteg időt spórolhatunk meg, annak ellenére, hogy először egy teljesen más szerkezetre (indexre) kell hivatkozni ahhoz, hogy az elsődleges szerkezetből (könyvből) megkaphassuk a szükséges információkat.
Mint a könyvmutató, az index be SQL szerver lehetővé teszi az előadást pontos lekérdezések a kívánt adatokhoz, ahelyett, hogy a táblázatban szereplő összes adatot teljes körben átvizsgálná. Kis táblák esetén a teljes vizsgálat általában nem jelent problémát, de a nagy táblák sok oldalnyi adatot foglalnak el, ami jelentős lekérdezés-végrehajtási időket eredményezhet, ha nincs olyan index, amely lehetővé tenné a lekérdezőmotor számára, hogy azonnal megkapja a megfelelő adathelyet. Képzelje el, hogy térkép nélkül eltéved egy többszintű útkereszteződésben egy nagy metropolisz előtt, és rájön az ötlet.
Ha az indexek olyan nagyszerűek, miért nem hozza létre őket minden oszlopban?
Egyetlen jó cselekedet sem maradhat büntetlenül. Legalábbis az indexeknél ez a helyzet. Természetesen az indexek nagyszerűek mindaddig, amíg lekérdezéseket végez az operátorral KIVÁLASZTÁS, de amint az operátorok gyakori hívása BESZÁLLÍTÁS, FRISSÍTÉSÉs TÖRÖLígy a táj nagyon gyorsan változik.Amikor egy szolgáltató adatigénylését kezdeményezi KIVÁLASZTÁS, a lekérdezőmotor megkeresi az indexet, végigmegy a fastruktúráján, és megkeresi a keresett adatokat. Mi lehetne könnyebb? De a dolgok megváltoznak, ha változási nyilatkozatot adsz ki, mint pl FRISSÍTÉS. Igen, az utasítás első részében a lekérdezőmotor ismét az index segítségével keresheti meg a módosítandó sort – ez jó hír. És ha egy sorban egyszerű adatmódosítás történik, amely nem befolyásolja a kulcsoszlopok változását, akkor a változtatási folyamat teljesen fájdalommentes lesz. De mi van akkor, ha a változtatás eredményeképpen az adatokat tartalmazó oldalak kettéválnak, vagy ha egy kulcsoszlop értéke megváltozik, aminek következtében az átkerül egy másik indexcsomópontba – ez azt a tényt eredményezheti, hogy az indexet át kell szervezni, ami hatással lesz az összes kapcsolódó indexre és műveletre, aminek eredményeként széles körben csökken a teljesítmény.
Hasonló folyamatok fordulnak elő a kezelő hívásakor TÖRÖL. Az index segíthet a törlendő adatok megtalálásában, de maga az adatok törlése oldalcseréhez vezethet. Az üzemeltetővel kapcsolatban BESZÁLLÍTÁS, az összes index fő ellensége: elkezd sok adatot hozzáadni, ami az indexek megváltozásához, átszervezéséhez vezet, és mindenki szenved.
Tehát mérlegelje az adatbázis lekérdezésének típusait, amikor megfontolja, hogy milyen típusú indexeket és hányat kell létrehozni. A több nem jelent jobbat. Mielőtt új indexet adna egy táblához, ne csak az alapvető lekérdezések költségeit vegye figyelembe, hanem a lemezterület, a karbantartási költségek és az indexek költségeit is, amelyek dominóeffektushoz vezethetnek más műveleteknél. Az indextervezési stratégia a megvalósítás egyik legfontosabb szempontja, és számos szempontot kell magában foglalnia, az index méretétől, az egyedi értékek számától kezdve az index által támogatott lekérdezések típusáig.
Szükséges-e fürtözött indexet létrehozni egy elsődleges kulcs oszlopon?
Bármely oszlopon létrehozhat fürtözött indexet, amely megfelel a szükséges feltételeknek. Igaz, hogy a fürtözött index és az elsődleges kulcs megkötése egymásnak készült, és házasságuk a mennyben jön létre, ezért fogadja el azt a tényt, hogy amikor létrehoz egy elsődleges kulcsot, akkor automatikusan létrejön egy fürtözött index, ha még nem jött létre. Azonban dönthet úgy, hogy a fürtözött index máshol jobban működne, és döntése gyakran indokolt lesz.A fürtözött index fő célja, hogy a táblázat összes sorát az index meghatározásakor megadott kulcsoszlop alapján rendezze. Ez biztosítja gyors keresésÉs könnyű hozzáférés adatok táblázatához.
A tábla elsődleges kulcsa jó választás lehet, mert egyedileg azonosítja a táblázat minden sorát anélkül, hogy további adatokat kellene hozzáadnia. Egyes esetekben a legjobb választás lesz egy helyettesítő elsődleges kulcs, amely nem csak egyedi, de kis méretű is, és amelynek értékei szekvenciálisan nőnek, így az ezen az értéken alapuló, nem fürtözött indexek hatékonyabbak lesznek. A lekérdezésoptimalizáló is kedveli a fürtözött index és az elsődleges kulcs kombinációját, mert a táblák összekapcsolása gyorsabb, mint bármely más módon történő összekapcsolás, amely nem használja az elsődleges kulcsot és a kapcsolódó fürtözött indexet. Mint mondtam, ez egy mennyországban kötött házasság.
A végén azonban érdemes megjegyezni, hogy a fürtözött index létrehozásakor több szempontot is figyelembe kell venni: hány nem fürtözött index lesz az alapján, milyen gyakran változik az indexkulcs oszlop értéke, és mekkora. Ha a fürtözött index oszlopaiban lévő érték megváltozik, vagy az index nem a várt módon teljesít, akkor a tábla összes többi indexe is hatással lehet. A fürtözött indexnek a legstabilabb oszlopon kell alapulnia, amelynek értékei egy bizonyos sorrendben nőnek, de nem változnak véletlenszerűen. Az indexnek támogatnia kell a tábla leggyakrabban használt adataira vonatkozó lekérdezéseket, így a lekérdezések teljes mértékben kihasználják az adatok rendezettségét és elérhetőségét a gyökércsomópontokon, az index levelein. Ha az elsődleges kulcs megfelel ennek a forgatókönyvnek, akkor használja. Ha nem, válasszon másik oszlopkészletet.
De mi van, ha indexel egy nézetet, akkor is nézet marad?
A prezentáció az virtuális asztal A, amely egy vagy több táblából állít elő adatokat. Ez lényegében egy elnevezett lekérdezés, amely adatokat kér le az alapul szolgáló táblákból, amikor lekérdezi az adott nézetet. Javíthatja a lekérdezés teljesítményét, ha ebben a nézetben fürtözött indexet és nem fürtözött indexeket hoz létre, hasonlóan ahhoz, ahogyan indexeket hoz létre egy táblán, de a fő figyelmeztetés az, hogy először fürtözött indexet kell létrehoznia, majd létrehozhat egy nem fürtözött indexet.Ha indexelt nézetet (materializált nézetet) hoz létre, akkor maga a nézetdefiníció különálló entitás marad. Végül is ez csak egy keményen kódolt kijelentés KIVÁLASZTÁS Az adatbázisban tárolt. De az index egy teljesen más történet. Ha fürtözött vagy nem fürtözött indexet hoz létre egy nézeten, az adatok fizikailag a lemezen tárolódnak, akárcsak egy normál index. Ezenkívül, ha az alapul szolgáló táblákban megváltoznak az adatok, a nézet indexe automatikusan megváltozik (ez azt jelenti, hogy érdemes elkerülni a gyakran változó táblák nézeteinek indexelését). Mindenesetre a nézet nézet marad - egy pillantás a táblázatokra, de csak kész Ebben a pillanatban, a hozzá tartozó indexekkel.
Mielőtt indexet hozhatna létre egy nézeten, annak meg kell felelnie néhány korlátozásnak. Például egy nézet csak alaptáblákra hivatkozhat, más nézetekre nem, és ezeknek a tábláknak ugyanabban az adatbázisban kell lenniük. Valójában sok más korlátozás is létezik, ezért feltétlenül olvassa el a dokumentációt SQL szerver minden piszkos részletért.
Miért használjunk lefedő indexet az összetett index helyett?
Először is győződjünk meg arról, hogy megértjük a köztük lévő különbséget. Az összetett index csak egy normál index, amely egynél több oszlopot tartalmaz. Több kulcsoszlop használható az egyes táblasorok egyediségének biztosítására, az is előfordulhat, hogy az elsődleges kulcs több oszlopból áll az egyediség biztosítása érdekében, vagy a gyakran hívott lekérdezések több oszlopon történő végrehajtását próbálja optimalizálni. Általában azonban minél több kulcsoszlopot tartalmaz egy index, annál kevésbé hatékony az index, ezért az összetett indexeket megfontoltan kell használni.Mint már említettük, egy lekérdezés óriási előnyökkel járhat, ha minden szükséges adat azonnal megtalálható az index lapjain, akárcsak maga az index. Ez nem jelent problémát a fürtözött indexeknél, mint pl minden adat már megvan (ezért olyan fontos, hogy alaposan átgondolja, amikor fürtözött indexet hoz létre). A levelek nem fürtözött indexe azonban csak a kulcsoszlopokat tartalmazza. A lekérdezésoptimalizálónak további lépésekre van szüksége az összes többi adat eléréséhez, ami jelentős többletköltséget okozhat a lekérdezések futtatásához.
Itt jön segítségül a fedezeti index. Ha nem fürtözött indexet definiál, a kulcsfontosságú oszlopok mellett további oszlopokat is megadhat. Tegyük fel például, hogy az alkalmazás gyakran kér oszlopadatokat. Rendelés azonosítóÉs Rendelés dátuma az asztalban Értékesítés:
SELECT OrderID, OrderDate FROM Sales WHERE OrderID = 12345;
Létrehozhat egy összetett, nem fürtözött indexet mindkét oszlopban, de a Rendelés dátuma oszlop csak növeli az index karbantartásának költségeit, és nem szolgál különösen hasznos kulcsoszlopként. A legjobb megoldás egy lefedő index létrehozása kulcsoszloppal Rendelés azonosítóés egy további mellékelt oszlop Rendelés dátuma:
CREATE NONCLUSTERED INDEX ix_orderid ON dbo.Sales(Rendelésazonosító) INCLUDE(Rendelés dátuma);
Ezzel elkerülheti a redundáns oszlopok indexelésének hátrányait, miközben a lekérdezések futtatásakor megőrzi az adatok leveleken való tárolásának előnyeit. A benne lévő oszlop nem része a kulcsnak, de az adatok pontosan a végcsomóponton, az indexlevélen tárolódnak. Ez további költségek nélkül javíthatja a lekérdezés teljesítményét. Ezenkívül kevesebb korlátozás vonatkozik a lefedő indexben szereplő oszlopokra, mint az index kulcsoszlopaira.
Számít-e az ismétlődések száma egy kulcsoszlopban?
Index létrehozásakor meg kell próbálnia csökkenteni a duplikációk számát a kulcsoszlopokban. Vagy pontosabban: próbálja meg a duplikált érték arányát a lehető legalacsonyabb szinten tartani.Ha összetett indexszel dolgozik, akkor a duplikáció az összes kulcsoszlop egészére vonatkozik. Egyetlen oszlop sok ismétlődő értéket tartalmazhat, de az index összes oszlopában az ismétlődést minimálisra kell csökkenteni. Például létrehozhat egy összetett, nem fürtözött indexet az oszlopokon KeresztnévÉs vezetéknév, sok John Does és sok Does lehet, de azt szeretné, hogy a lehető legkevesebb John Doe legyen, vagy még jobb, ha csak egy John Doe.
A kulcsoszlop értékeinek egyediségi együtthatóját az index szelektivitásának nevezik. Minél több egyedi érték, annál nagyobb a szelektivitás: az egyedi index a lehető legmagasabb szelektivitással rendelkezik. A lekérdezőmotor nagyon szereti a magas szelektivitási értékű oszlopokat, különösen, ha ezek az oszlopok a leggyakrabban végrehajtott lekérdezések WHERE záradékaiban jelennek meg. Minél nagyobb az indexszelektivitás, a lekérdezőmotor annál gyorsabban tudja csökkenteni az eredményül kapott adatkészlet méretét. A hátránya természetesen az, hogy a viszonylag kevés egyedi értékkel rendelkező oszlopok ritkán alkalmasak az indexelésre.
Létrehozható-e nem fürtözött index egy kulcsoszlop adatainak csak egy meghatározott részhalmazán?
Alapértelmezés szerint a nem fürtözött index minden táblázatsorhoz egy sort tartalmaz. Természetesen ugyanezt elmondhatjuk a fürtözött indexről is, mivel az index a táblázat. De ami a nem klaszterezett indexet illeti, az egy az egyhez kapcsolat fontos fogalom, mert mivel a verzió SQL Server 2008, lehetősége van szűrhető index létrehozására, amely korlátozza a benne szereplő sorokat. A szűrt index javíthatja a lekérdezés teljesítményét, mert kisebb, és szűrt, pontosabb statisztikákat tartalmaz, mint az összes táblázatos – ez jobb végrehajtási terveket eredményez. A szűrt index kevesebb tárhelyet és alacsonyabb karbantartási költségeket is igényel. Az index csak akkor frissül, ha a szűrőnek megfelelő adatok megváltoznak.Ezenkívül könnyen létrehozható egy szűrhető index. Az operátorban INDEX LÉTREHOZÁSA csak meg kell adni AHOL szűrési állapot. Például kiszűrheti az összes NULL-t tartalmazó sort az indexből, ahogy az a kódban is látható:
CREATE NONCLUSTERED INDEX ix_trackingnumber ON Sales.SalesOrderDetail(CarrierTrackingNumber) WHERE CarrierTrackingNumber NEM NULL;
Valójában minden olyan adatot kiszűrhetünk, amely nem fontos a kritikus lekérdezésekben. De légy óvatos, mert. SQL szerver számos korlátozást szab a szűrhető indexekre, például nem hozható létre szűrhető index egy nézeten, ezért figyelmesen olvassa el a dokumentációt.
Az is előfordulhat, hogy hasonló eredményeket érhet el egy indexelt nézet létrehozásával. A szűrt indexnek azonban számos előnye van, például csökkentheti a karbantartási költségeket és javíthatja a végrehajtási tervek minőségét. A szűrt indexek online is újraépíthetők. Próbálja ki indexelt nézetben.
És megint egy kicsit a fordítótól
Ennek a fordításnak a Habrahabr oldalain való megjelenésének célja az volt, hogy elmesélje vagy emlékeztesse Önt a SimpleTalk blogra redgate.
Sok szórakoztató és érdekes bejegyzést közöl.
Nem vagyok kapcsolatban a cég termékeivel redgate, sem az eladásukkal.
Ahogy ígértem, könyvek azoknak, akik többet szeretnének tudni
Három nagyon jó könyvet ajánlok magamtól (a linkek ide vezetnek meggyújt verziók a boltban amazon):
 |
Microsoft SQL Server 2012 T-SQL Fundamentals (Fejlesztői referencia) Szerző: Itzik Ben-Gan Megjelenés dátuma: 2012. július 15 A szerző, a maga mestere, alapvető ismereteket ad az adatbázisokkal való munkáról. Ha mindent elfelejtett, vagy soha nem tudta, akkor mindenképpen érdemes elolvasni. | Elvileg meg lehet nyitni egyszerű indexeket
BAN BEN ezt az anyagot adatbázis-objektumok kerülnek figyelembevételre Microsoft SQL Server Hogyan indexek, Megtanulja, hogy mik az indexek, milyen típusúak az indexek, hogyan kell létrehozni, optimalizálni és törölni őket.
Mik azok az indexek az adatbázisban?
Index egy adatbázis-objektum, amely egy táblázat vagy nézet egy vagy több oszlopán alapuló kulcsokból és mutatókból álló adatstruktúra, amely az adott adatok tárolási helyére van leképezve. Az indexeket úgy tervezték, hogy gyorsabban lekérjék a sorokat egy táblázatból, más szóval az indexek gyors adatkeresést tesznek lehetővé egy táblában, ami nagymértékben javítja a lekérdezések és az alkalmazások teljesítményét. Az indexek a tábla sorainak egyediségének biztosítására is használhatók, ezzel garantálva az adatok integritását.
Indextípusok a Microsoft SQL Serverben
A következő típusú indexek léteznek a Microsoft SQL Serverben:
- fürtözött (fürtözött) egy olyan index, amely az indexkulcs értéke szerint rendezett táblázatadatokat tárol. Egy táblának csak egy fürtözött indexe lehet, mivel az adatok csak egy sorrendben rendezhetők. Lehetőség szerint minden táblának legyen fürtözött indexe, ha egy táblának nincs fürtözött indexe, akkor az ilyen táblát " csokor". A fürtözött index automatikusan létrejön az ELSŐDLEGES KULCS kényszerek létrehozásakor ( elsődleges kulcs) és EGYEDI, ha a táblán lévő fürtözött index még nincs meghatározva. Ha fürtözött indexet hoz létre egy táblán ( halmok), amely nem fürtözött indexekkel rendelkezik, mindegyiket újra kell építeni a létrehozás után.
- nem klaszterezett (nem klaszterezett) egy olyan index, amely tartalmazza a kulcs értékét és egy mutatót a kulcs értékét tartalmazó adatkarakterláncra. Egy táblának több, nem fürtözött indexe is lehet. Nem fürtözött indexek hozhatók létre fürtözött indexszel rendelkező vagy anélküli táblákon. Ezt az indextípust használják a gyakran használt lekérdezések teljesítményének javítására, mivel a nem fürtözött indexek gyors keresést és kulcsértékek szerinti hozzáférést biztosítanak az adatokhoz;
- szűrhető (szűrt) egy optimalizált, nem fürtözött index, amely szűrőpredikátumot használ a táblázat sorainak egy részének indexelésére. Ha jól van megtervezve, az ilyen típusú index javíthatja a lekérdezés teljesítményét, és csökkentheti az index karbantartási és tárolási költségeit a teljes táblás indexekhez képest;
- Egyedi (Egyedi) egy olyan index, amely biztosítja, hogy ne legyenek ismétlődések ( azonos) indexkulcsértékeket, ezzel garantálva a sorok egyediségét adott kulcs. Mind a fürtözött, mind a nem fürtözött indexek egyediek lehetnek. Ha több oszlopon egyedi indexet hoz létre, az index garantálja, hogy a kulcsban szereplő értékek minden kombinációja egyedi legyen. Az ELSŐDLEGES KULCS vagy EGYEDI megszorítások létrehozásakor az SQL Server automatikusan létrehoz egy egyedi indexet a kulcsoszlopokon. Egyedi index csak akkor hozható létre, ha a táblában jelenleg nincsenek ismétlődő értékek a kulcsoszlopokhoz;
- oszlopos (oszlopos bolt) oszlopos adattárolási technológián alapuló index. Ez a típus Az index hatékony a nagy adattárházakban, mert akár 10-szeresére növelheti a tárolási lekérdezések teljesítményét, és akár 10-szeresére csökkentheti az adatméretet, mivel az oszloptár-indexben lévő adatok tömörítettek. Vannak fürtözött oszlopos indexek és nem fürtözöttek is;
- teljes szöveg (teljes szöveg) egy speciális típusú index, amely hatékonyan támogatja a karakterlánc-adatok összetett szókeresését. A teljes szövegű index létrehozásának és karbantartásának folyamatát " töltő". Léteznek ilyen típusú töltések: teljes kitöltés és változáskövetés alapján történő kitöltés. Az SQL Server alapértelmezés szerint teljesen feltölti az új teljes szövegű indexet, amint létrejön, de ez a tábla méretétől függően meglehetősen erőforrásigényes lehet, így lehetséges a teljes populáció késleltetése. A változáskövető vetés a teljes szövegű index fenntartására szolgál, miután az eredetileg teljes kitöltésre került;
- Térbeli (Térbeli) egy olyan index, amely lehetővé teszi a geometriai vagy földrajzi adattípusú oszlopok jellemzőivel kapcsolatos konkrét műveletek hatékonyabb használatát. Ez a típusú index csak térbeli oszlopon hozható létre, és a táblának, amelyhez térindex van meghatározva, tartalmaznia kell egy elsődleges kulcsot ( ELSŐDLEGES KULCS);
- XML egy másik speciális indextípus, amelyet a típussal rendelkező oszlopokhoz terveztek XML adatok. Az XML index javítja az XML oszlopok lekérdezésének hatékonyságát. Kétféle XML-index létezik: elsődleges és másodlagos. Az elsődleges XML index az XML oszlopban tárolt összes címkét, értéket és elérési utat indexeli. Csak akkor hozható létre, ha a tábla elsődleges kulcsán fürtözött index található. Másodlagos XML-index csak akkor hozható létre, ha a tábla rendelkezik elsődleges XML-indexszel, és a lekérdezés teljesítményének javítására szolgál egy adott típusú XML-oszlop-hozzáférés esetén, ezért többféle másodlagos index létezik: PATH, VALUE és TULAJDON;
- Vannak speciális indexek is a memóriára optimalizált táblákhoz ( In-Memory OLTP) például: Hash ( Hash) indexek és a memóriára optimalizált, nem fürtözött indexek, amelyek tartomány- és rendezett vizsgálatokhoz jönnek létre.
Indexek létrehozása és eldobása a Microsoft SQL Serverben
Mielőtt elkezdené az index létrehozását, jól meg kell tervezni az index hatékony felhasználása érdekében, mivel a rosszul megtervezett indexek nem növelhetik, hanem csökkenthetik a teljesítményt. Például egy táblában lévő nagyszámú index csökkenti az INSERT, UPDATE, DELETE és MERGE utasítások teljesítményét, mivel amikor a tábla adatai megváltoznak, az összes indexet ennek megfelelően módosítani kell. Általános ajánlások az indextervezést egy külön cikkben tárgyaljuk, de most térjünk át az indexek létrehozásának és törlésének folyamatára.
Jegyzet! Az SQL szerverem a Microsoft SQL Server 2016 Express.
Indexek létrehozása
A Microsoft SQL Serverben kétféleképpen hozhat létre indexeket: az első az SQL Server Management Studio (SSMS) környezet grafikus felülete, a másik pedig a Transact-SQL nyelv használata, mindkét módszert elemezzük Önnel.
Kiindulási adatok példákhoz
Képzeljük el, hogy van egy TestTable nevű terméktáblázatunk, amely három oszlopból áll:
- ProductId - termékazonosító;
- ProductName - termék neve;
- CategoryID - termékkategória.
Példa fürtözött index létrehozására
Mint mondtam, a fürtözött index automatikusan létrejön, ha például egy tábla létrehozásakor egy adott oszlopot adunk meg elsődleges kulcsként ( ELSŐDLEGES KULCS), de mivel nem tettük meg, nézzünk egy példát egy fürtözött index létrehozására.
A fürtözött index létrehozásához megadhatunk egy táblához egy elsődleges kulcsot, és így automatikusan létrejön a fürtözött index, vagy külön is létrehozhatunk fürtözött indexet.
Például hozzunk létre egy fürtözött indexet elsődleges kulcs létrehozása nélkül. Először csináljuk meg vele Menedzsment stúdió.
Nyissa meg az SSMS-t, és az objektumkezelőben keresse meg a kívánt táblát, és kattintson a jobb gombbal az elemre " Indexek", választ " Index létrehozása" és index típusa, esetünkben " fürtözött».

Megnyílik az űrlap Új index”, ahol meg kell adnunk az új index nevét ( a táblázaton belül egyedinek kell lennie), azt is jelezzük, hogy ez az index egyedi lesz-e, ha a terméktáblázatban szereplő termékazonosítóról beszélünk, akkor természetesen egyedinek kell lennie. Ezután válassza ki az oszlopot index kulcs), amely alapján fürtözött indexet készítünk, azaz. a táblázat adatsorai a " gomb segítségével lesznek rendezve Hozzáadás».

Az összes szükséges paraméter megadása után kattintson a " rendben”, ennek eredményeként fürtözött index jön létre.

Hasonlóképpen lehet fürtözött indexet létrehozni a használatával T-SQL utasítás LÉTREHOZÓ INDEX például így
EGYEDI KLUSTERES INDEX LÉTREHOZÁSA IX_Clustered ON TestTable (ProductId ASC) GO
Vagy, ahogy már mondtuk, az utasítást használhatjuk például egy elsődleges kulcs létrehozására is
TÁBLÁZAT MÓDOSÍTÁSA TesztTable ADD CONSTRAINT PK_TestTable PRIMARY KEY CLUSTERED (ProductId ASC) GO
Példa egy nem fürtözött index létrehozására, benne oszlopokkal
Most nézzünk egy példát egy nem fürtözött index létrehozására, miközben megadjuk azokat az oszlopokat, amelyek nem kulcsfontosságúak, de szerepelni fognak az indexben. Ez akkor hasznos, ha indexet hoz létre a számára konkrét kérés, például azért, hogy az index teljesen lefedje a lekérdezést, pl. minden oszlopot tartalmazott ( ezt hívják "lefedettség igénylése"). A lekérdezés lefedettsége javítja a teljesítményt, mivel a lekérdezésoptimalizáló az index összes oszlopértékét megtalálja anélkül, hogy hozzá kellene férnie a táblaadatokhoz, ami kevesebb lemez I/O-t eredményez. De ne feledje, hogy a nem kulcsfontosságú oszlopok indexbe foglalása az index méretének növekedését eredményezi, pl. Az indextárolás több lemezterületet igényel, és az INSERT, UPDATE, DELETE és MERGE műveletek teljesítményének csökkenését is eredményezheti az alaptáblázaton.
A Management Studio grafikus felületével nem fürtözött index létrehozásához megtaláljuk a kívánt tábla és indexek elemet is, csak ebben az esetben a " Létrehozás -> Nem csoportosított index».

Az űrlap kinyitása után Új index» megadjuk az index nevét, hozzáadunk egy kulcsoszlopot vagy oszlopokat a « gombbal Hozzáadás”, például tesztesetünkhöz adjuk meg a CategoryID-t.

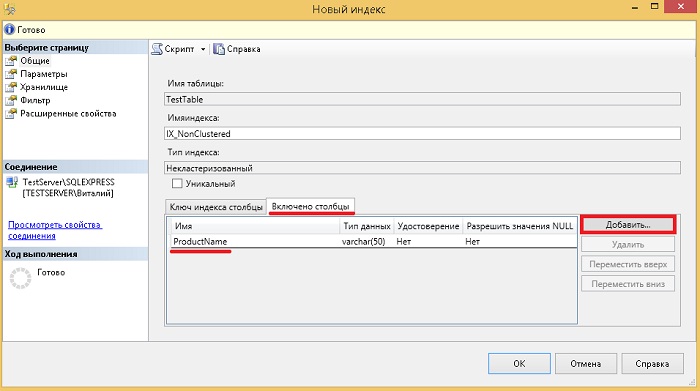
A Transact-SQL-ben ez így nézne ki.
NEM CLUSTERED INDEX LÉTREHOZÁSA IX_NonClustered ON TestTable (CategoryID ASC) INCLUDE (ProductName) GO
Példa egy index törlésére a Microsoft SQL Serverben
Az index eltávolításához kattintson a jobb gombbal a kívánt indexre, majd kattintson a " Töröl", majd erősítse meg a műveletet a " rendben».

vagy használhatod az állítást is DROP INDEX, Például
Drop INDEX IX_NonClustered ON TestTable
Vegye figyelembe, hogy a DROP INDEX utasítás nem vonatkozik azokra az indexekre, amelyeket az ELSŐDLEGES KULCS és az EGYEDI megszorítások létrehozásával hoztak létre. Ebben az esetben az ALTER TABLE utasítást kell használnia a DROP CONSTRAINT záradékkal az index eldobásához.
Indexek optimalizálása a Microsoft SQL Serverben
A táblákban lévő adatok frissítése, hozzáadása vagy törlése következtében az SQL Server automatikusan végrehajtja a megfelelő változtatásokat az indexeken, de idővel mindezek a változtatások az indexben az adatok töredezettségét okozhatják, pl. szétszórva lesznek az adatbázisban. Az indexek töredezettsége a lekérdezési teljesítmény csökkenésével jár, ezért időnként szükség van indexkarbantartási műveletekre, nevezetesen töredezettségmentesítésre, például index-újraszervezési és újraépítési műveletekre.
Mikor kell használni az index átszervezését és mikor kell újraépíteni?
A kérdés megválaszolásához először meg kell határoznia az index töredezettségének mértékét, mivel az index töredezettségétől függően az egyik vagy másik töredezettségmentesítési módszer előnyösebb és hatékonyabb. Az index töredezettségének meghatározásához használhatja a rendszertábla függvényt sys.dm_db_index_physical_stats Ez részletes információkat ad vissza az index méretéről és a töredezettségről. Például a következő lekérdezés segítségével megtudhatja az index töredezettségének mértékét az aktuális adatbázis összes táblájára vonatkozóan.
SELECT OBJECT_NAME(T1.object_id) AS NameTable, T1.index_id AS IndexId, T2.name AS IndexName, T1.avg_fragmentation_in_percent AS Fragmentation FROM sys.dm_db_index_physical_stats (DB_ID(), LENULLIN, ASNULL)in, ASNULLin. AS T2 ON T1. object_id = T2.object_id ÉS T1.index_id = T2.index_id
Ebben az esetben a rovat érdekel bennünket avg_fragmentation_in_percent, azaz százalékos logikai töredezettség.
- Ha a töredezettség mértéke 5%-nál kisebb, akkor az index átszervezését vagy újraépítését egyáltalán nem szabad lefuttatni;
- Ha a töredezettség mértéke 5-30%, akkor érdemes index-átszervezést futtatni, mivel ezt a műveletet minimális rendszererőforrást használ, és nem igényel hosszú távú zárolást;
- Ha a töredezettség mértéke meghaladja a 30%-ot, akkor újra kell építeni az indexet, mivel ez a művelet jelentős töredezettséggel nagyobb hatást fejt ki, mint az index átszervezése.
Személy szerint a következőket tudom hozzátenni, ha kis céged van és az adatbázis nem igényel maximális hatékonyságot 24/7 módban, pl. Mivel nem szuperaktív adatbázisról van szó, biztonságosan végrehajthat időközönként egy index-újraépítési műveletet anélkül, hogy a töredezettség mértékét meghatározná.
Index átszervezés
Index átszervezés egy index töredezettségmentesítési folyamat, amely töredezettségmentesíti a fürtözött és nem fürtözött indexek levélszintjét táblákon és nézeteken, fizikailag átrendezve a levélszintű oldalakat a logikai sorrendnek megfelelően ( balról jobbra) végcsomópontok.
Grafikus SSMS-eszközt vagy Transact-SQL utasítást használhat az index átszervezéséhez.
Index átszervezése a Management Studio segítségével

Index átszervezés a Transact-SQL-lel
ALTER INDEX IX_NonClustered ON TestTable REORGANIZE GO
Indexek újjáépítése
Index átépítése Az a folyamat, amelynek során a régi indexet eldobják, és újat hoznak létre, ami a töredezettség megszüntetését eredményezi.
Az indexek újjáépítésének két módja van.
Első. Az ALTER INDEX utasítás és a REBUILD záradék használatával. Ez az utasítás a DBCC DBREINDEX utasítást váltja fel. Általában ezt a módszert használják a tömeges index-újraépítésekhez.
Példa
ALTER INDEX IX_NonClustered ON TestTable REBUILD GO
A második pedig a CREATE INDEX utasítás használatával a DROP_EXISTING záradékkal. Használható például egy index újraépítésére a definíciójának megváltoztatásával, pl. kulcsoszlopok hozzáadása vagy eltávolítása.
Példa
NONCLUSTERED INDEX LÉTREHOZÁSA IX_NonClustered ON TestTable (CategoryID ASC) WITH(DROP_EXISTING = ON) GO
Az újraépítési funkció a Management Studioban is elérhető. Jobb klikk a kívánt indexen Újjáépíteni».

Ezzel zárjuk a Microsoft SQL Server indexelési alapjairól szóló anyagot, ha érdekel T-SQL nyelv Könyvem elolvasását ajánlom