1s skd dina resultat. Datasammansättningssystem samlade funktioner
Artikeln beskriver ett exempel på den praktiska användningen av det vägda genomsnittet i rapportens summor. Några metoder för att arbeta med ACS visas. Artikeln är avsedd för en förberedd läsare som har minst grundläggande färdigheter i att arbeta med ACS och frågebyggaren.
Beräkningen av det vägda genomsnittet används aktivt i uppgifter relaterade till management accounting och andra affärsberäkningar.
A-priory, - VÄGT GENOMSNITT(vägt medelvärde) är det aritmetiska medelvärdet, som tar hänsyn till vikten av var och en av de termer för vilka detta medelvärde beräknas.
I nästan alla läroböcker om management accounting, för att illustrera det vägda genomsnittet, ger de ett exempel med köp av tre partier av samma produkt - varje parti av varor har ett annat inköpspris och en annan kvantitet. Det är klart att om vi i en sådan situation tar det aritmetiska genomsnittet av inköpspriserna, så får vi medeltemperaturen på sjukhuset - en siffra som inte har någon praktisk betydelse. I en sådan situation är det det vägda genomsnittet som är vettigt.
Samma läroboksexempel: varor köptes i tre partier, varav en var 100 ton på 70l. Konst. per ton, den andra - 300 ton vid 80l. Konst. per ton och den tredje - 50 ton vid 95 lbs. Konst. per ton, då köper han totalt 450 ton varor; vanlig genomsnittspris inköp blir (70 + 80 + 95): 3 = 81,7l. Konst. Det vägda genomsnittspriset, med hänsyn tagen till volymerna för var och en av delarna, är (100 × 70) + (300 × 80) + (50 × 95): 450 = 79,4 £. Konst. per ton.
Formel:
Där X är värdena vill vi väga medelvärde och W är vikterna.
Det är här teorin slutar.
Jag fick ta itu med detta när jag visade upp data om försäljning av varor i en rapport, grupperad efter chefer, där det var nödvändigt för att få lönsamhet i resultatet. Raderna i rapporten visade lönsamheten för varje produkt i rean, i slutändan var det nödvändigt att se med vilken lönsamhet chefen arbetade. Följaktligen är lönsamhet ett "värde", och "vikten" av detta värde är intäkter. Ett antal förtydliganden för att komplettera bilden. Intäkt (försäljningsvolym) är produkten av varans försäljningspris och kvantitet. Bruttovinst är intäkter minus kostnad (hur exakt kostnaden beräknades i samband med denna artikel är inte viktigt). Och slutligen är vår lönsamhet förhållandet mellan bruttovinst och omsättning, uttryckt i procent.
Frågan uppstår – med vilken lönsamhet arbetade chefen under rapportperioden. För att svara korrekt på denna fråga måste du beräkna det vägda genomsnittliga värdet av lönsamhet.
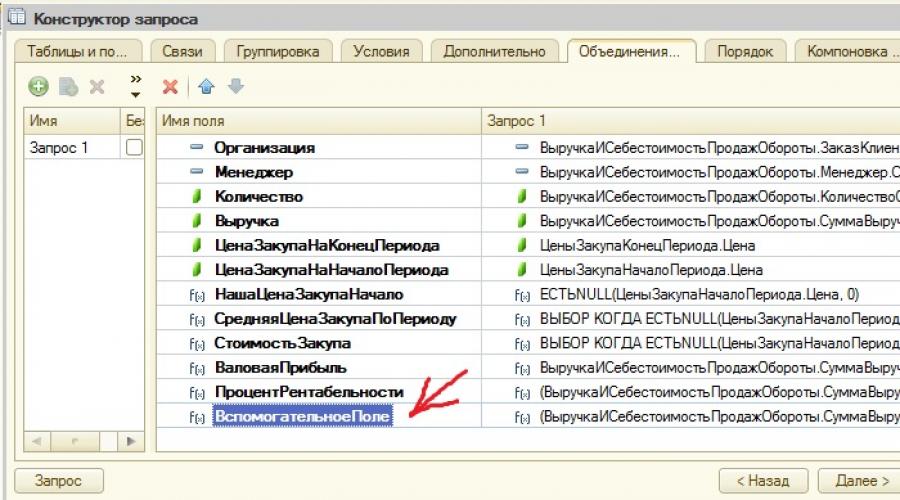
För att få det viktade genomsnittet av lönsamhet i ACS skapar vi i frågekonstruktorn ett hjälpfält av formuläretgodtyckligt uttryck, där vi skriver produkten av lönsamhet till intäkter. Tilldela ett alias till det här fältet -Hjälpfält. Se bilden nedan.

Vi kommer inte att visa detta fält i rapporten, vi behöver data för att beräkna totalsummorna. Vi kommer att beräkna resultaten redan i ACS på flikenResurser.
Ett annat sätt att arbeta med ACS på fliken "Resurser", där beräkningen av totalsummor anges, är möjligheten att använda uttryck i fältet "Uttryck", med data från fältet "Tillgängliga fält". Se bilden nedan.

För kolumnen i rapporten "Procentandel av lönsamhet" skriver vi uttrycket Belopp(AuxiliaryField)/Amount(Revenue).

För att sammanfatta, först och främst, är det viktigt att förstå vad ett viktat medelvärde är, och var du behöver använda bara det aritmetiska medelvärdet, och var - det viktade medelvärdet. Ur teknisk synvinkel kan två punkter utgöra en viss svårighet - skapandet av ett hjälpfält i rapporten och möjligheten att använda ett godtyckligt uttryck i ACS-resurserna för att beräkna de totaler vi behöver.
Jag hoppas att den här artikeln kommer att vara användbar för någon.
Logga in som student
Logga in som elev för att få tillgång till skolinnehåll
1C 8.3 datasammansättningssystem för nybörjare: räkna resultaten (resurser)
Målet med denna lektion kommer att vara:
- Skriv en rapport som visar en lista över produkter (matkatalog), deras kaloriinnehåll och smak.
- Gruppera produkter efter färg.
- Bekanta dig med summeringsfunktionen (resurser) och beräknade fält.
Skapar en ny rapport
Som i tidigare lektioner, öppna databasen " Deli" i konfiguratorn och skapa en ny rapport via menyn " Fil"->"Ny...":
Dokumenttyp - extern rapport:

I formuläret för rapportinställningar skriver du namnet " Lektion 3"och tryck på knappen" Öppna datasammansättningsdiagrammet":

Lämna standardschemanamnet och klicka på " Redo":

Lägga till en fråga via konstruktorn
På fliken " Datauppsättning"klick grön plustecken och välj " Lägg till datauppsättning - Fråga":

Istället för att skriva texten i begäran manuellt, kör igen frågekonstruktör:

På fliken " tabeller"dra bordet" Mat" från den första kolumnen till den andra:

Välj från tabell Mat" fälten som vi kommer att begära. För att göra detta, dra fälten " namn", "Smak", "Färg"och" kalorier"från den andra kolumnen till den tredje:

Det blev så här:

Tryck på knappen " OK" - förfrågningstexten genererades automatiskt:

Inställningar för presentation av rapport
Gå till bokmärke inställningar"och klicka på trollspö, att ringa inställningskonstruktör:

Välj typ av rapport Lista..." och tryck på knappen " Ytterligare":

Dra och släpp från vänster kolumn till höger fälten som kommer att visas i listan och klicka på " Ytterligare":

Dra från vänster kolumn till höger fält " Färg"- enligt det kommer att hända gruppering rader i rapporten. Tryck " OK":

Och här är resultatet av konstruktören. Hierarki i vår rapport:
- rapportera som helhet
- gruppering "Färg"
- detaljerade register - rader med livsmedelsnamn

Spara rapporten (knapp diskett) Och utan att stänga konfigurator, kommer vi omedelbart att öppna den i användarläge. Det blev så här:

Ändra kolumnordningen
Men låt oss ändra ordningen kolumner (pilar upp och ner) så att det ser ut som på bilden nedan:

Spara rapporten och öppna den igen i användarläge:

Bra, det är mycket bättre.
Summering (summa) efter kaloriinnehåll
Det skulle vara trevligt att visa det totala kaloriinnehållet i livsmedel per grupp. För att se summan av kaloriinnehållet i alla produkter, säg vit eller gul. Eller ta reda på det totala kaloriinnehållet i alla livsmedel i databasen.
Det finns en resursberäkningsmekanism för detta.
Gå till fliken " Resurser"och dra fältet" kalorier"(vi ska sammanfatta det) från den vänstra kolumnen till höger.
Samtidigt, i uttrycksfältet, välj från rullgardinsmenyn " Mängd (kalorier)", eftersom summan kommer att vara summan av alla element som ingår i summan:

Spara och generera en rapport:

Vi har resultaten för var och en av grupperna och för rapporten som helhet.
Sammanfattning (genomsnitt) efter kaloriinnehåll
Låt oss nu göra det så att en annan kolumn visas genomsnitt kaloriinnehåll i produkter efter grupper och i allmänhet för rapporten.
Det är omöjligt att röra den redan befintliga kolumnen "Kaloriinnehåll" - totalsumman visas redan i den, därför låt oss lägga till ett annat fält, vilket kommer bli en exakt kopia kalorifält.
För att skapa ett sådant "virtuellt" fält använder vi mekanismen beräknade fält.
Gå till bokmärke Beräknade fält"och tryck grön plustecken:

I en kolumn" Dataväg"skriv namnet på det nya fältet ( tillsammans, utan mellanslag). Låt det kallas Genomsnittliga kalorier" och i kolumnen " Uttryck" vi skriver namnet på ett redan befintligt fält, utifrån vilket det nya fältet kommer att beräknas. Vi skriver där " kalorier". Kolumn" rubrik" kommer att fyllas i automatiskt.

Vi har lagt till ett nytt fält (" Genomsnittliga kalorier"), men det kommer inte att visas i rapporten av sig självt - du måste antingen ringa upp det igen inställningskonstruktör("trollspö") eller lägg till det här fältet manuellt.
Låt oss agera andra sätt. För att göra detta, gå till fliken " inställningar", välj" Rapportera" (Vi vill trots allt lägga till fältet som en helhet i rapporten), välj fliken nedan " Valda fält"och dra fältet" Genomsnittliga kalorier" från vänster kolumn till höger:

Det blev så här:

Spara och generera en rapport:

Fältet har dykt upp och vi ser att dess värden är värdena i fältet "Kalori". Bra!
För att göra detta använder vi återigen den mekanism som redan är bekant för oss. Resurser(sammanfattande). Gå till bokmärke Resurser"och dra fältet" Genomsnittliga kalorier" från vänster kolumn till höger:

Samtidigt i kolumnen Uttryck"välja" Average (Average Calorie)":

Spara och generera en rapport:

Vi ser att för grupperna, det vill säga för varje färg, och för rapporten som helhet, beräknades medelvärdet helt korrekt. Men närvarande extra poster för enskilda produkter (inte för grupper) som du vill ta bort från rapporten.
Vet du varför de dök upp (betydelser inte i grupper)? För när vi lade till fältet " Genomsnittliga kalorier" i rapportinställningarna, i det andra steget vi valde hela rapporten och detta nya fält träffade elementet " Detaljerad uppgifter".
Låt oss åtgärda felet. För att göra detta, gå tillbaka till fliken " inställningar", välj" Detaljposter"top först (steg 2) och sedan" Detaljposter"underifrån (steg 3), gå till bokmärke" Vald fält" och se elementet i dess högra kolumn " Bil".
Element " Bil" - detta är inte ett fält. Det här är flera fält som automatiskt kommer hit baserat på högre inställningar.
För att se vad dessa fält är - klicka på elementet " Bil" höger knappen och välj " Bygga ut":

Element " Bil" expanderat till följande fält:

Här är vårt fält Genomsnittliga kalorier"som kom hit från stycket" Rapportera"när vi släpade dit den. Bara låt oss lyfta bocka bredvid detta fält för att ta bort dess utdata.
I datalayout ställa in totaler ser lite annorlunda ut än i förfrågningar. Låt oss definiera datasetet "Fråga" i datasammansättningssystemet.
I själva frågan ställer vi inte upp totaler, utan går till fliken "Resurser" i datasammansättningen. På datasammansättningsschemanivån har vi definiera resurser. Det är dessa fält som behöver beräknas på grupperingsnivå. Klicka på knappen ">>" så kommer systemet självt att överföra alla numeriska fält och definiera dem som resurser.
Resurser kan också innehålla icke-numeriska fält. Om du till exempel väljer attributet "Länk" kommer systemet att räkna antalet dokument i våra grupperingar. Denna information kan också vara till hjälp. Så, i layoutschemat definierar vi bara resurser, och själva grupperingarna konfigureras på nivån för rapportvarianten. Dessutom kan användaren själv skapa grupperingar som han vill se i sina rapportvariantinställningar.
Låt oss skapa standardinställning datalayout.
Klicka på knappen "Öppna Inställningsdesigner".

Låt oss välja rapporttyp - lista. Låt oss trycka på knappen "Nästa".

Markera alla fält och flytta motpartsfältet till det mesta topposition. Låt oss trycka på knappen "Nästa".

Markera alla fält och flytta motpartsfältet till den översta positionen. Låt oss trycka på knappen "OK".

Fick följande inställning:

Som du kan se, i rapportvariantinställningarna, är resurser markerade med en grön ikon så att de snabbt kan särskiljas från andra fält.

Om vi öppnar vår rapport i 1C:Enterprise-läge och genererar den kommer vi att se att slutdata genereras på grupperingsnivå. Resultat efter nomenklatur och efter motparter.

Ställa in resurser i 1C-datasammansättningsschemat
Låt oss nu rikta uppmärksamheten mot inställningar som finns för resurser. I fältet "Uttryck" kan vi ange en aggregerad funktion genom vilken vi kan få värdet på resursen. I rullgardinsmenyn kan du se ett antal standardfunktioner, men inte alla. Det finns till exempel inga funktioner.

Här i fältet "Uttryck" kan vi skriva ett eget uttryck.

I fältet "Uttryck" kan vi även hänvisa till funktionerna i vanliga moduler.
Dessutom kan du ange i fältet "Beräkna efter ..." för vilka grupperingar du behöver för att beräkna resursen. Om fältet "Beräkna efter..." inte är ifyllt, kommer resursens totala värde att beräknas på alla grupperingsnivåer, som definieras i inställningarna för rapportvarianten. I vårt fall måste du fylla i fältet "Beräkna med ..." i resursen "Mängd", eftersom vi kan sälja varor med olika enheter mätningar. Till exempel: olja i liter och hjul i bitar. Skulle det inte vara ologiskt att räkna ihop mängden av dessa varor? Därför måste vi lämna summan av kvantiteten på artikelnivå och på motpartsnivå
ta bort summeringen.

Om vi genererar en rapport kommer vi att se att totalsummorna per kvantitet endast beräknas av nomenklaturen, och av motparter är summan av kvantiteten tomma.

Möjligheter att beskriva resurser i 1C-datalayoutschemat
låt oss överväga ett antal icke uppenbara särdrag förknippade med beskrivningen av resurser.
- Varje resurs kan definiera flera gånger. Men detta är bara vettigt om
resursen kommer att beräknas på olika nivåer av grupperingar. Till exempel, om kvantiteten, i ett fall
sammanfattas för posten, och för motparter får vi minimivärdet.

Om vi genererar en rapport kommer vi att se att för Deria-motparten är minimiköpet fem enheter av självhäftande papper.

- I fältet "Uttryck" kan du förutom att skriva en formel använda en speciell datasammansättningsfunktion som kallas "beräkna". Denna funktion låter dig beräkna ett slutvärde med hjälp av en viss formel. Till exempel, för varje motpart måste du veta procentandelen av inköp i naturliga enheter i förhållande till den totala volymen. Men hur får man totala inköp efter kvantitet? För att göra detta, använd funktionen "Beräkna" och skriv följande uttryck i fältet "Uttryck":
Som sett, alla parametrar för funktionen "Beräkna" är strängar. För att kvantitetsfältet ska visas vackert i rapporten konfigurerar vi det på fliken "Datauppsättningar". I kvantitetsraden hittar du fältet "Redigeringsalternativ". Låt oss öppna dialogrutan, hitta raden "Format" och redigera formatsträngen i den och ställa in "Precision"-värdet till två på fliken "Number".

Låt oss köra rapporten och se resultatet av att beräkna andelen köp för motparten "AUPP KOS LLP" i förhållande till
total volym:
I slutet av artikeln vill jag råda dig fri från Anatoly Sotnikov. Detta är en kurs från en erfaren programmerare. Han kommer att visa dig på separat basis hur du bygger rapporter i ACS. Du behöver bara lyssna noga och komma ihåg! Du får svar på frågor som:Du kanske inte ska försöka surfa på Internet själv på jakt efter den nödvändiga informationen? Dessutom är allt klart för användning. Bara att börja! Alla detaljer om vad som finns i de kostnadsfria videohandledningarna
- Hur skapar man en enkel listrapport?
- Vad är kolumnerna Fält, Sökväg och Titel på fliken Fält till för?
- Vilka är begränsningarna för layoutfält?
- Hur ställer man in roller korrekt?
- Vilka är rollerna för layoutfält?
- Var hittar jag datalayoutfliken i en fråga?
- Hur konfigurerar man parametrar i SKD?
- Mer intressant...
Här är en av lärdomarna om fliken datasammansättning i en fråga:
I denna korta notering vill jag visa hur du kan summera värden på olika grupperingsnivåer i en rapport med hjälp av ett datasammansättningssystem.
Som visas i bilden, endast på grupperingsnivån "Artikelgrupper", beräknas resursen "Beställning", den visar hur mycket som ska beställas för den aktuella varugruppen baserat på vissa villkor:
Detta värde kan endast beräknas för given nivå gruppering eftersom, över eller under, det inte finns några värden att beräkna. Till exempel, på nivån för detaljerade poster, finns det inga uppgifter om det maximala antalet i en grupp, eftersom dessa data endast är sanna för gruppen som helhet och inte för dess individuella komponenter.
Följaktligen är det nu nödvändigt att beräkna summorna för de högre grupperingarna ("Lager", "Lagertyper") och totalen.
För detta används funktionen Beräkna uttryck med grupperad matris:
UTVÄRDERA UTTRYCK FÖR ARRAYGRUPPER (EVALEXPRESSIONWITHGROUPARRAY)
Syntax:
ComputeExpressionGroupedArray(,)
Beskrivning:
Funktionen returnerar en array, vars varje element innehåller resultatet av att utvärdera uttrycket för gruppering efter det angivna fältet.
Layoutbyggaren, när den genererar en layout, konverterar funktionsparametrar till termer av datalayoutlayoutfält. Till exempel kommer fältet Konto att konverteras till Dataset. Konto.
Layoutbyggare vid generering av uttryck för utdata anpassat fält, vars uttryck endast innehåller funktionen CalculateArrayWithGroupArray(), genererar ett utmatningsuttryck på ett sådant sätt att utdatainformationen ordnas. Till exempel, för ett anpassat fält med ett uttryck:
Beräkna ExpressionWith GroupingArray("Amount(AmountTurnover)", "Motpart")
Layoutbyggaren kommer att generera följande uttryck för utdata:
ConcatenateStrings(Array(Order(CalculateGroup ExpressionValueTable("View(Amount(DataSet.AmountTurnover)),Amount(DataSet.AmountTurnover)","DataSet.Counterparty"),"2")))
Alternativ:
Typ: Sträng. Uttrycket som ska utvärderas. En sträng, till exempel Amount(AmountTurnover).
Typ: Sträng. Gruppering av fältuttryck – gruppering av fältuttryck separerade med kommatecken. Till exempel Entreprenör, Part.
Typ: Sträng. Ett uttryck som beskriver filtret som tillämpas på detaljerade poster. Aggregatfunktioner stöds inte i ett uttryck. Till exempel, DeletionMark = False.
Typ: Sträng. Ett uttryck som beskriver filtret som tillämpas på gruppposter. Till exempel, Amount(AmountTurnover) > &Parameter1.
Exempel:
Maximum(Beräkna uttryckMed GroupingArray("Amount(AmountOmsättning)", "Motpart"));
En detaljerad beskrivning av funktionssyntaxen finns på http://its.1c.ru/db/v837doc#bookmark:dev:TI000000582
Nu för beräkningen kommer vi att duplicera fältet "Order", med olika värden för "Beräkna med ...", med hjälp av följande uttryck, notera att på varje högre nivå, värdena för nivåerna på den lägre grupperingar används.
Som ett resultat får vi följande konstruktion:

Viktig! Om funktionsparametern är av typen String och den anger ett fältnamn som innehåller mellanslag, måste ett sådant fältnamn omges av hakparenteser.
Till exempel: "[Nummeromsättning]".
1. Totalt- beräknar summan av värdena för uttrycken som skickas till den som ett argument för alla detaljerade poster. Du kan skicka en Array som en parameter. I det här fallet kommer funktionen att tillämpas på innehållet i arrayen.
Exempel:
Belopp (försäljning. belopp omsättning)
2. Antal (antal) - räknar antalet icke-nullvärden. Du kan skicka en Array som en parameter. I det här fallet kommer funktionen att tillämpas på innehållet i arrayen.
Syntax :
Kvantitet ([Various] Parameter)
I kvittot instruktionerna olika betydelser föregå parametern Kvantitetsmetod med Distinct.
Exempel:
Kvantitet (försäljning. entreprenör)
Kvantitet (Olika försäljningar. Entreprenör)
3. Maximum (Maximum)
- får maxvärdet. Du kan skicka en Array som en parameter. I det här fallet kommer funktionen att tillämpas på innehållet i arrayen.
Exempel:
Maximum(Återstoden. Kvantitet)
4. Minimum - får minimivärdet. Du kan skicka en Array som en parameter. I det här fallet kommer funktionen att tillämpas på innehållet i arrayen.
Exempel:
Minsta (saldo. kvantitet)
5. Genomsnitt - får medelvärdet för icke-nullvärden. Du kan skicka en Array som en parameter. I det här fallet kommer funktionen att tillämpas på innehållet i arrayen.
Exempel:
Genomsnitt (Återstoden. Kvantitet)
6. Array - bildar en array som innehåller värdet på parametern för varje detaljerad post.
Syntax :
Array([Various] Expression)
Du kan använda en värdetabell som parameter. I det här fallet kommer resultatet av funktionen att vara en array som innehåller värdena i den första kolumnen i värdetabellen, skickad som en parameter. Om uttrycket innehåller Array-funktionen anses det vara det givet uttryckär aggregerad. Om nyckelordet Variant anges, kommer den resulterande arrayen inte att innehålla dubbletter av värden.
Exempel:
Array (konto)
7. Värdetabell - genererar en värdetabell som innehåller lika många kolumner som det finns parametrar för funktionen. Detaljerade poster erhålls från de datauppsättningar som behövs för att få alla fält som är involverade i funktionsparameteruttrycken.
Syntax :
Värdetabell([Olika] Uttryck1 [AS kolumnnamn1][, uttryck2 [AS kolumnnamn2],...])
Om funktionsparametrarna är restfält, kommer den resulterande värdetabellen att inkludera värden för poster för unika kombinationer av mätningar från andra perioder. I det här fallet erhålls värden endast för saldofält, dimensioner, konton, periodfält och deras detaljer. Värdena för andra fält i poster från andra perioder anses vara NULL. Om ett uttryck innehåller funktionen ValueTable, anses uttrycket vara ett aggregerat uttryck. Om nyckelordet Different anges, kommer den resulterande värdetabellen inte att innehålla rader som innehåller samma data. Varje parameter kan följas av ett valfritt AS-nyckelord och ett namn som kommer att tilldelas värdetabellkolumnen.
Exempel:
Värdetabell (Various Nomenclature, Feature Nomenclature AS Feature)
8. Komprimera (GroupBy) - utformad för att ta bort dubbletter från en array.
Syntax :
Komprimera (uttryck, kolumnnummer)
Alternativ :
- Uttryck- ett uttryck av typen Array eller ValueTable, vars värden för elementen måste komprimeras;
- Siffror Kolumner- (om uttrycket är av typen ValueTable) av typen String. Siffror eller namn (avgränsade med kommatecken) på kolumnerna i värdetabellen, bland vilka du måste söka efter dubbletter. Standard är alla kolumner.
Collapse(ValueTable(PhoneNumber, Address), "Phone Number");
9. GetPart (GetPart) - får en värdetabell som innehåller vissa kolumner från den ursprungliga värdetabellen.
Syntax :
GetPart(Expression, ColumnNumbers)
Alternativ :
- Uttryck- typValueTable. Tabell över värden som du kan hämta kolumnerna från;
- Siffror Kolumner- typ String. Siffror eller namn (avgränsade med kommatecken) på kolumnerna i värdetabellen som ska erhållas.
Exempel:
GetPart(Collapse(ValueTable(PhoneNumber, Address) ,"PhoneNumber"),"PhoneNumber");
10. Beställning - är avsedd för ordning av elementen i arrayen och värdetabellen.
Syntax :
Ordning (uttryck, kolumnnummer)
Alternativ :
- Uttryck- Matris eller värdetabell för att hämta kolumner;
- Siffror Kolumner- (om uttrycket är av typen ValueTable) nummer eller namn (avgränsade med kommatecken) på kolumnerna i värdetabellen som ska sorteras efter. Kan innehålla beställningsriktning och behov av autobeställning: Fallande/Stigande + Autobeställning.
Exempel:
Sort(ValueTable(Telefonnummer, Adress, Samtalsdatum),"Samtalsdatum fallande");
11. ConnectStrings (JoinStrings) - utformad för att sammanfoga strängar till en enda sträng.
Syntax :
ConcatenateStrings(Value, Element Separator, Column Separatorer)
Alternativ :
- Menande- uttryck som ska kombineras till en rad. Om det är en array kommer elementen i arrayen att kombineras till en sträng. Om är en ValueTable, kommer alla kolumner och rader i tabellen att kombineras till en rad;
- Elementseparator- en sträng som innehåller texten som ska användas som avgränsare mellan arrayelement och värdetabellsrader. Standard är ett nyradstecken;
- Kolumnavskiljare- en sträng som innehåller texten som ska användas som avgränsare mellan kolumnerna i värdetabellen. Standard "; ".
ConnectStrings(ValueTable(PhoneNumber, Address));
12. Gruppbearbetning - returnerar DataCompositionGroupProcessingData-objektet. I objektet, i egenskapen Data, placeras grupperingsvärdena i form av en värdetabell för varje uttryck som anges i funktionsparametern Expressions. Vid användning av hierarkisk gruppering bearbetas varje nivå i hierarkin separat. Värden för hierarkiska poster placeras också i datan. Objektets CurrentElement-egenskap är inställd på värdetabellsträngen för vilken funktionen för närvarande utvärderas.
Syntax :
GroupProcessing(Expressions, ExpressionsHierarchy, GroupName)
Alternativ :
- Uttryck. Uttryck som ska utvärderas. En sträng som innehåller en kommaseparerad lista med uttryck som ska utvärderas. Efter varje uttryck kan det finnas ett valfritt nyckelord AS och kolumnnamn för den resulterande värdetabellen. Varje uttryck bildar en kolumn i värdetabellen för dataegenskapen för DataCompositionGroupProcessingData-objektet.
- UttryckHierarkier. Uttryck som ska utvärderas för hierarkiska poster. Liknar parametern Expressions, med skillnaden att parametern Hierarchy Expressions används för hierarkiska poster. Om parametern inte är specificerad, används uttrycken som anges i parametern Expression för att beräkna värden för hierarkiska poster.
- Grupperingsnamn. Namnet på den gruppering i vilken bearbetningsgrupperingen ska beräknas. Linje. Om inte specificerat, så sker beräkningen i den aktuella grupperingen. Om beräkningen finns i tabellen och parametern innehåller en tom sträng, eller inte är specificerad, beräknas värdet för gruppering - strängen. Layoutbyggaren, när den genererar en datalayoutlayout, ersätter det angivna namnet med namnet på grupperingen i den resulterande layouten. Om grupperingen inte är tillgänglig kommer funktionen att ersättas med ett NULL-värde.
Syntax :
Varje (uttryck)
Parameter:
- Uttryck- Boolesk typ.
Varje()
14. Alla (alla)- om minst en post är True, är resultatet True, annars False
Syntax :
Alla (uttryck)
Parameter:
- Uttryck- Boolesk typ.
Några()
15. Populationsstandardavvikelse (Stddev_Pop) - Beräknar populationens standardavvikelse. Den beräknas med formeln: SQRT(Varians av den allmänna befolkningen (X)).
Syntax :
Populationsstandardavvikelse (uttryck)
Parameter:
- Uttryck- typ nummer.
Exempel:
| X | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| Y | 7 | 1 | 2 | 5 | 7 | 34 | 32 | 43 | 87 |
Resultat: 805,694444
16. Exempel på standardavvikelse (Stddev_Samp) - beräknar den kumulativa standardavvikelsen. Beräknas med formeln: SQRT(Sampling Variance(X)).
Syntax :
Exempel på standardavvikelse (uttryck)
Parameter:
- Uttryck- typ nummer.
Exempel:
| X | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| Y | 7 | 1 | 2 | 5 | 7 | 34 | 32 | 43 | 87 |
Resultat: 28,3847573
17. Varianssampling (Var_Samp) - beräknar den typiska skillnaden för en serie siffror utan att ta hänsyn till NULL-värden i denna uppsättning. Beräknas med formeln: (Sum(X^2) - Sum(X)^2 / Belopp(X)) / (Mängd(X) - 1). Om Kvantitet(X) = 1, returneras NULL.
Syntax :
Varianssampling (uttryck)
Parameter:
- Uttryck- typ nummer.
VÄLJ Populationsvarians(Y) FRÅN tabell
Resultat: 716,17284
19. Befolkningskovarians (Covar_Pop) - beräknar kovariansen för ett antal numeriska par. Beräknas med formeln: (Sum(Y * X) - Sum(X) * Sum(Y) / n) / n, där n är antalet par (Y, X) där varken Y eller X är NULL.
Syntax :
Befolkningskovarians(Y, X)
Alternativ :
- Y- typnummer;
- X- typ nummer.
| X | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| Y | 7 | 1 | 2 | 5 | 7 | 34 | 32 | 43 | 87 |
Resultat: 59,4444444
20. Sample Covariance (Covar_Samp) - beräknar den typiska skillnaden för en serie siffror utan att ta hänsyn till NULL-värden i denna uppsättning. Beräknas med formeln: (Sum(Y * X) - Sum(Y) * Sum(X) / n) / (n-1), där n är antalet par (Y, X) där varken Y eller X är NULL.
Syntax :
Exempel kovarians(Y, X)
Alternativ :
- Y- typnummer;
- X- typ nummer.
| X | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| Y | 7 | 1 | 2 | 5 | 7 | 34 | 32 | 43 | 87 |
Resultat: 66.875
21. Korrelation (Corr) - beräknar korrelationskoefficienten för ett antal numeriska par. Beräknas med formeln: Populationskovarians(Y, X) / (Standardavvikelse för population(Y) * Standardavvikelse för population(X)). Par där Y eller X är NULL beaktas inte.
Syntax :
Korrelation (Y, X)
Alternativ :
- Y- typnummer;
- X- typ nummer.
| X | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| Y | 7 | 1 | 2 | 5 | 7 | 34 | 32 | 43 | 87 |
Resultat: 0,860296149
22. Regression Slope (Regr_Slope) - beräknar linjens lutning. Beräknas med formeln: Population Covariance(Y, X) / Population Variance(X). Beräknas utan att ta hänsyn till par som innehåller NULL.
Syntax :
RegressionSlope(Y, X)
Alternativ :
- Y- typnummer;
- X- typ nummer.
| X | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| Y | 7 | 1 | 2 | 5 | 7 | 34 | 32 | 43 | 87 |
Resultat: 8,91666667
23. Regression Intercept (Regr_Intercept) - beräknar Y-punkten för skärningspunkten för regresslinjen. Beräknat med formeln: Medel(Y) - Regressionslutning(Y, X) * Medel(X). Beräknas utan att ta hänsyn till par som innehåller NULL.
Syntax :
RegressionSegment(Y, X)
Alternativ :
- Y- typnummer;
- X- typ nummer.
VÄLJ Regressionsräkning(Y, X) FRÅN tabell
Resultat: 9
25. RegressionR2 (Regr_R2) - beräknar bestämningskoefficienten. Beräknas utan att ta hänsyn till par som innehåller NULL.
Syntax :
RegressionR2(Y, X)
Alternativ :
- Y- typnummer;
- X- typ nummer.
- Null - om Varians av den allmänna populationen (X) = 0;
- 1 - om befolkningsvarians(Y)=0 OCH befolkningsvarians(X)<>0;
- POW(Korrelation(Y,X),2) - om befolkningsvarians(Y)>0 OCH befolkningsvarians(X)<>0.
| X | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| Y | 7 | 1 | 2 | 5 | 7 | 34 | 32 | 43 | 87 |
Resultat: 0,740109464
26. RegressionAverageX (Regr_AvgX) - Beräknar medelvärdet av X efter exkludering av X- och Y-par där antingen X eller Y är tomma. Mean(X) beräknas utan att ta hänsyn till par som innehåller NULL.
Syntax :
RegressionMeanX(Y, X)
Alternativ :
- Y- typnummer;
- X- typ nummer.
| X | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| Y | 7 | 1 | 2 | 5 | 7 | 34 | 32 | 43 | 87 |
Resultat: 5
27. RegressionAverageY (Regr_AvgY) - beräknar medelvärdet av Y efter exkludering av X- och Y-par, där antingen X eller Y är tomma. Medel(Y) beräknas utan att ta hänsyn till par som innehåller NULL.
Syntax :
RegressionMeanY(Y, X)
Alternativ :
- Y- typnummer;
- X- typ nummer.
| X | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| Y | 7 | 1 | 2 | 5 | 7 | 34 | 32 | 43 | 87 |
Resultat: 24,2222222
28. RegressionSXX (Regr_SXX) - beräknas med formeln: RegressionAmount(Y, X) * Varians av den allmänna populationen(X). Beräknas utan att ta hänsyn till par som innehåller NULL.
Syntax :
RegressionSXX(Y, X)
Alternativ :
- Y- typnummer;
- X- typ nummer.
Exempel:
VÄLJ RegressionSYY(Y, X) FRÅN tabell
Resultat: 6445.55556
30. RegressionSXY (Regr_SXY) - beräknas med formeln: RegressionAmount(Y, X) * Samvarians för den allmänna populationen(Y, X). Beräknas utan att ta hänsyn till par som innehåller NULL.
Syntax :
RegressionSXY(Y,X)
Alternativ :
- Y- typnummer;
- X- typ nummer.
| X | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| Y | 7 | 1 | 2 | 5 | 7 | 34 | 32 | 43 | 87 |
Resultat: 535
31. Rang
Syntax :
PlaceInOrder(Order, HierarchyOrder, GroupName)
Alternativ :
- Beställa– skriv String. Innehåller uttryck i vilka gruppposter ska placeras, separerade med kommatecken. Beställningsriktningen styrs av orden Asc, Desc. Fältet kan också följas av strängen AutoOrder, vilket innebär att ordningsföljden av länkar ska använda de beställningsfält som definierats för det refererade objektet. Om ingen sekvens anges, beräknas värdet i grupperingssekvensen;
- Hierarkins ordning– skriv String. Innehåller ordningsuttryck för hierarkiska poster;
- Grupperingsnamn– skriv String. Namnet på den gruppering i vilken bearbetningsgrupperingen ska beräknas. Om inte specificerat, så sker beräkningen i den aktuella grupperingen. Om beräkningen finns i tabellen och parametern innehåller en tom sträng, eller inte är specificerad, beräknas värdet för gruppering - strängen. Layoutbyggaren, när den genererar en datalayoutlayout, ersätter det angivna namnet med namnet på grupperingen i den resulterande layouten. Om grupperingen inte är tillgänglig kommer funktionen att ersättas med ett NULL-värde.
Exempel:
PlaceInOrder("[Antal Omsättning]")
32. Klassificering ABC (Klassificering ABC)
Syntax :
Klassificering ABC(Värde, Antal grupper, Procent för grupper, Gruppnamn)
Alternativ :
- Menande– skriv String. för att beräkna klassificeringen. Strängen som innehåller uttrycket;
- Antal grupper- typ nummer. Anger antalet grupper som ska delas upp i;
- InterestForGroups- typ String. Så många som antalet grupper du behöver för att dela minus 1. Separerade med kommatecken. Om inte inställt, då automatiskt;
- Grupperingsnamn- typ String. Namnet på den gruppering i vilken bearbetningsgrupperingen ska beräknas. Om inte specificerat, så sker beräkningen i den aktuella grupperingen. Om beräkningen finns i tabellen och parametern innehåller en tom sträng, eller inte är specificerad, beräknas värdet för gruppering - strängen. Layoutbyggaren, när den genererar en datalayoutlayout, ersätter det angivna namnet med namnet på grupperingen i den resulterande layouten. Om grupperingen inte är tillgänglig kommer funktionen att ersättas med ett NULL-värde.
Exempel:
KlassificeringABC("Belopp(bruttovinst)", 3, "60, 90")