Selection of keywords in Yandex Wordstat. Yandex, Google and Rambler search query statistics, how and why to work with Wordstat
Read also
Hello, dear readers of the blog site. Today I will try to tell you about such a concept as a semantic core, in any case, I will try, because the topic is quite specific and is unlikely to be of interest to everyone, although ...
And the internal pages of the site, the static weight of which is not very high, can be optimized for low-frequency queries (LF), which, as I have already mentioned more than once, with good luck, can be promoted with little or no external optimization (buying backlinks to these articles).
But since we're on the subject frequency of requests, without taking into account which we are unlikely to be able to compose a semantic core, then I will allow myself to remind you a little about this and how to determine their frequency. So, all the queries that users type in the search bar of Yandex, Google or any other search engine can be fairly roughly divided into three groups:
- high frequency (HF)
- mid-frequency (MF)
- low frequency (LF)
Attribute key phrase to this or that group it will be possible by the number of such requests made by users during the month. But for different topics boundaries can be quite different. The point here is that we, in fact, when selecting keywords is not interested in the frequency of input by their users, but in how difficult it will be to advance on them (how many optimizers are trying to do the same thing as you).
Therefore, it will be possible to introduce three more gradations, which, for compiling semantic core will be of great importance:
- highly competitive (VC)
- mid-competitive (SC)
- low competitive (NC)
But it is not always easy to determine the competitiveness of a particular keyword or phrase. Therefore, for simplicity, parallels are often drawn and VC is identified with HF, MF with SC, and LF with NC. In most cases, such a generalization will be justified, but, as you know, there are exceptions to any rule, and in some topics, NPs can turn out to be highly competitive, and you will immediately see this by how difficult it will be to move to the TOP for these keywords.
Such collisions are possible in topics where there is ultra-high competition and there is a struggle for each individual visitor, pulling them out even completely. low frequency requests. Although this may be inherent in not only commercial topics. For example, information sites on the subject of "WordPress" when compiling the semantic core should take into account that even requests with a frequency below 100 (one hundred impressions per month) can be highly competitive for the simple reason that sites on this topic are dark, because even such "stupid uncles" as I try to write something on this topic.
But we will not go into details so deeply and will assume when compiling the semantic core that competitiveness (how many optimizers try to promote their projects for this key) and frequency (how often users enter them in the search box) are directly related to each other. Well, we can somehow determine the frequency of certain keywords, right?
You can use several for this, but I like the Yandex tool the most. Previously, it was intended only so that advertisers could correctly compose the texts of their contextual ads, taking into account which words users most often ask from this search engine.
But then access to online keyword research service under the name Yandex Wordstat (Wordstat.Yandex.ru) was open to everyone, and these same people did not fail to take advantage of it. Well, what are we worse?
Yandex Wordstat - what to consider when collecting seed
So, let's go to this wonderful service from Yandex, which is called "keyword statistics" and is located at Wordstat.Yandex.ru. This service was created and is positioned as an indispensable tool for working with Yandex Direct, as well as for SEO promotion of your site for this search engine. But in fact, it has become the most powerful tool for analyzing keywords in Runet.
Therefore, in addition to its direct purpose Yandex Wordstat can also be successfully used:
- Working with Google Adwords
- To search for popular hashtags in social networks
- To obtain data on the demand for a particular product
- To build the site structure
- To search for similar words
- To test the demand for goods or services in another region when looking for new markets
- To analyze the success of offline advertising by analyzing the frequency of mentions of brand words
With all this, the Wordstat interface can be said to be Spartan, but this is perhaps only for the better. If you want more, you can use various programs to work remotely with this service, or install a plug-in like Yandex Wordstat Assistant in your browser.
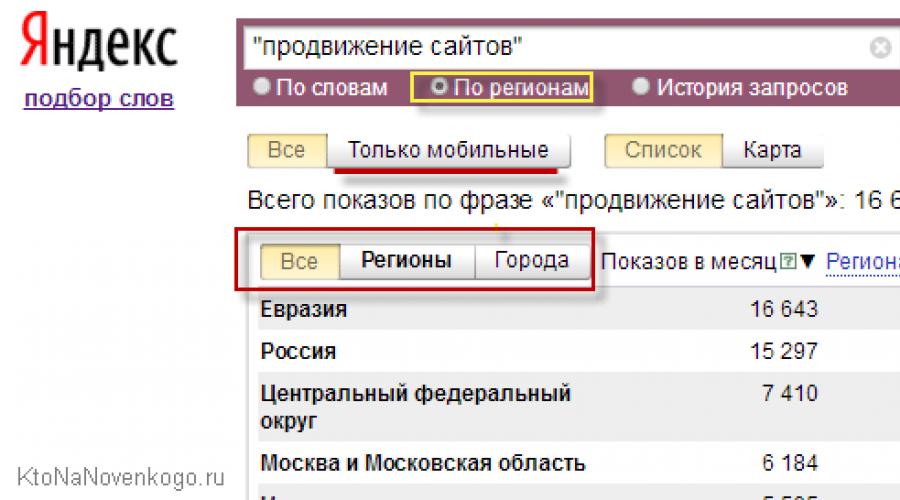
After Yandex introduced the division of search results depending on the region, you have the opportunity to see the frequency of entering certain search queries for each region separately (for this you will need select region by clicking on the appropriate tab).

If regionality does not bother you, then it makes sense to look at the statistics on the first tab without taking into account geodependence. In principle, this is not so important at the stage of studying the principles of compiling a semantic core for a site. As well as the recently appeared opportunity to view statistics separately only for mobile users (using tablets and smartphones). This may be relevant in light of the avalanche growth of mobile traffic.
In any case, first you will need to select for yourself a number of basic keywords (masks) on the subject of your future project, from which we will already begin to dance further and select all other key keywords using the Yandex wordstat. Where to get them? Well, just think or look at the competitors you know in your niche (there is a Serpstat service that can help with this).
Yes, and simple logic is often very useful. For example, if your future site will be on the subject of "Joomla", then to compile the semantic core, it would be quite logical to enter this keyword into Yandex.Wordstat to begin with. The logic is simple. If the site is based on SEO, then there can be a lot of initial keys (SEO, website promotion, promotion, optimization, etc.).
Well, as an example, we will take another phrase: “wordstat”. Let's see what this online service tells us about itself. Here it is worth making a few remarks.
What you need to know and understand to successfully use WordStat
- First, in order to start getting a significant influx of visitors for your chosen key, your site must be in the top 10(for the first ten lives, alas, there is practically no) search results (sickle - see). And imagine that there are hundreds, if not thousands, of those who want (competitors). Therefore, the seed is only a necessary condition for the success of the site, but not at all sufficient.
- Secondly, besides this, now almost every user has their own issue, which is somewhat different from what even their neighbor on the floor sees. The preferences and desires of this particular user are taken into account if Yandex was able to identify them earlier (well, and the region, of course, if the request is geo-dependent - for example, “pizza delivery”). The positions in this plan are the “average temperature for the hospital” and will not always lead to the expected influx of visitors. Want to see the true picture? Use .
- Thirdly, even if you rank in the Top 10 SERPs (shown to most of your target users), then the number of clicks to your site will greatly depend on two things: the position (the first and tenth positions can differ in clickability by dozens of times) and the attractiveness of your site (information about the page of your site displayed in the search results for this particular request).
- The queries you have chosen to promote and form the semantic core are simply may be empty. Although dummies can be identified and weeded out, beginners quite often fall for this bait. How to see and fix it, read a little lower.
- There is such a thing as wrapping search queries. It personally does not occur to me who and why this is needed, but such requests do occur. Starting promotion on them, you will not get the traffic that you could count on based on Yandex Wordstat data. Read more about cheat detection methods below.
- Specify your region (if you have a regional business or regional queries) when viewing statistics, otherwise you may get a completely untrue picture.
- Be sure to take into account the seasonality of your requests (if any) when analyzing promotion results. In Wordstat, seasonality is clearly visible on the "Query History" tab. Do not take into account seasonal ups and downs as a factor in your failures or success in promotion.
- It is convenient to work directly with the service interface with a small number of requests, but then it already becomes "torture". Therefore, the main issue of successful use of Wordstat is the automation of routine operations. How and with what to automate will be described below.
- If you learn how to use Wordstat operators correctly, then the return on it can be increased significantly. These are quotes, and a plus sign, and an understanding of what this service gives out when entering not quite ordinary requests. Read about it below and in the section "Secrets of YanVo"
Scared? I even got scared myself, despite the fact that for hundreds of requests (quite frequent) my blog is in the Top (and not least due to the fact that I almost immediately started working based on the semantic core, albeit in a somewhat truncated version - selecting keys for a future article just before writing it). But if I started now (even with current experience), I would not believe that I would “manage to break through”. Is it true! I think for the most part I'm lucky.
Wordstat operators in examples
So, let's take a closer look at the last two points - requests with dummy and cheat. Ready? Well, then off we go. Let's start with dummy requests. Remember the example we used just above? Enter the word WORDSTAT in the line of this service and click on the "Select" button.

So, you need to understand that the figure displayed for this word (or any other phrase) does not at all reflect the actual number of requests for this key. Displayed (attention!) is the total number of phrases requested per month in which the word "Wordstat" was found, and not the number of queries that include this single word (or phrase, if you enter a key phrase in the Wordstat form). Actually, this is clear from the screenshot - "What they were looking for with the word ...".
But Yandex Wordstat has the appropriate toolkit that allows you to separate the wheat from the chaff (to identify dummies or get information about the frequency that is adequate to reality) and get the data we need. These are various operators, which you can add to your query and get a refined result.

Quote Operators and Exclamation Mark - Elimination of Blanks in Wordstat
As you can see, there are few basic operators and the main ones, in my opinion, are enclosing the key phrase in quotation marks and putting an exclamation point before a word. Although for highly competitive topics it may be relevant and new operator Wordstat in the form of square quotes. Sometimes it is important to know how most often users place the words in the query you need (for example, “buy an apartment” or still “buy an apartment”). However, I am not using it yet.
So, wordstat operator "quotes" will allow you to count the number of entries in the Yandex search string of this particular phrase during the month, but at the same time, all its possible word forms will be taken into account and calculated - another number, case, etc. (for example, Yandex Wordstat requests will not be taken into account, but only Wordstat in our example). In fact, this is the same thing that we considered in the article about. Frequency digit after such the simplest operation will be significantly reduced:

Those. such a number of times per month users entered one single word WORDSTAT in all its word forms (if they exist at all) in the Yandex search string. Of course, given request not a dummy at all, but a full-fledged HF, but there are times when simply enclosing a phrase in quotes reduces the frequency from several thousand to several tens or even units (for example, punch the phrase “earnings 100” in quotes and without). This was really empty.
The second important statement in Wordstat is Exclamation point before a word, which will oblige this service to count only words in exactly the spelling in which you entered them (without taking into account word forms). As I expected, for the word "Joomla" the installation of the exclamation mark operator did not add any adjustments, but this is only because of the specifics of this particular keyword.
Well, for the key phrase “website promotion”, the difference will be obvious and striking:

And add "!" before each word without adding a space:

Where did such a difference in numbers come from? Obviously, there is a request (s) with the same keywords, but in a different word form, which eats off the remaining numbers. For our example, it is easy to guess that this will be the plural:

Thus, by using quotes around the phrase and placing an exclamation point in front of each of the words, you can get completely different frequency values. Thus, you can not only weed out dummies, but also get ideas about the word forms of the phrase, which it would be desirable to use in the text more often, and which less often (although do not forget about synonyms). Although, personally, I don’t see a strong difference when adding exclamation marks, so I’m content with simple quotes.
How to quickly remove garbage and leave only targeted queries
There is another operator that allows you to cut off all unnecessary and see the real frequency of the phrase. This "+" in front of a word. It means that the given word must be present in the phrase. Why might this be necessary? Well, it's all about the features of the Yandex search engine.
By default, the ranking (and hence the Wordstat statistics) does not take into account conjunctions, prepositions, interjections, etc. words. This is done to simplify, but often we are interested in the prospect of moving exactly under the phrase with a preposition or union. This is where the plus sign comes in handy.
By the way, minus operator will allow you to immediately clean the keywords from those that are non-target for you. For example, such a query to WordStat will immediately give the required result:
Smartphones (+to|+from|+to) -download -games -internet -mts-photo

Here, in order not to repeat this request three times, the operator is applied "vertical bar", which allows you to collect phrases with three prepositions at once (to, from, to). Well, words with a minus (stop words) are needed to clear phrases from garbage.
Here is another example of using operators for the same purpose:
Washing machines (cars | machines) (samsung | samsung)
It is very convenient and quickly cut off unnecessary and save time.
Selection of keywords in Yandex Wordstat
Probably, it is already becoming clear to you that those basic key phrases (masks) that you are able to formulate yourself, based on the future topic of your project, will need to be expanded with the help of Wordstat. And here, too, there is, as it were, two directions in obtaining new keywords to compose a full-fledged semantic core.
- First, you can take advantage of those advanced options that Wordstat gives out. in the left column your window. There will be queries that contain words from your mask (for example, “construction”, if your project has a corresponding topic). They will be sorted in descending order by the frequency of their use by users in the Yandex search line per month.
What is important here? It is important to immediately highlight those extended key options that will be targeted for your project. Target- these are such requests, according to the content of which it immediately becomes clear that the user entering it is looking for exactly what you can offer him on your site that you plan to promote.
For example, the query “core” is extremely high-frequency, but I don’t need it at all, because this is absolutely not the target keyword for this publication. You never know what users are looking for when entering it in the Yandex search bar, well, certainly not “semantic”, which, by the way, will be a vivid example of a target query in relation to this article.
But you need to choose target keys in relation to the entire future site, although it is sometimes useful to move on general queries, but this is rather an exception to the rule.
Target phrases will be lower-frequency and users who come from them from the search results will be able to find at least something similar to what they wanted to find, which means they will not immediately leave your project, thereby worsening the . Yes, and such visitors are very important to you, because they can perform the action you need (make a purchase or order a service).
I think that there is no need to talk further about the selection of just such keywords from Yandex statistics - you already understand everything. The only "but". All the phrases from the right column of Wordstat to you again need to check for bugs, namely, enclose them in quotes (statistics with exclamation points can be viewed and analyzed later. If the frequency does not tend to zero, then add it to the stash.

You probably noticed that for many phrases the list in the left column is not limited to one page (there is a “next” button at the bottom). The maximum that Wordstat gives is, in my opinion, 2000 requests. And all of them will need to be checked for dummies. Can you handle it? But this is only one of many "masks" ( initial keys) of your semantic core. After all, you can “move horses” there.
But don't worry, there is a way. At the link you will find a detailed article, and if after that something else remains unclear, then throw a stone at me.
- The second nuance in the selection of phrases for the semantic core is the possibility of using the so-called associations from Yandex Wordstat statistics. These very associative queries are given in the right column its main window.

Here, it is probably important to understand how these very associative queries in Yandex statistics are formed and where they come from. The fact is that the search engine analyzes the behavior of the user who is looking for something from him.
For example, if the user, after (or before) typing our key phrase “semantic core”, entered some other query into the search string (this is called in one search session), then Yandex can make an assumption that these queries somehow interconnected.
If the same associative relationship is observed among some other users, then this query, set along with the main query, will be shown in the right column of Wordstat. Well, you just have to use this data to expand the semantic core of your site.
All associations will have an indication of the frequency of their request during the month. But, of course, it will be general, i.e. you still have to identify dummies again by checking all these phrases in quotation marks (Slovoeb or Key Collector will help you - read about them at the link above).
Some of the association queries have probably crossed your mind, but there will always be others that you have overlooked. Well, the more target keywords your semantic core will include, the large quantity You can attract the right visitors to your site with proper internal and external optimization.
So, we will assume that based on the basic masks (keywords that clearly define the subject of your future project) and the capabilities of Yandex Wordstat, you were able to type a sufficient number of phrases for the semantic core. Now you will need to clearly separate them by frequency of use.
Secret techniques for working with WordStat
Of course, this title is somewhat bright, but still, it is the “secrets” described below that can help you use this tool at 200%. Simply, if this is not taken into account, then you can spend time, money and effort in vain.
How to see search query boost in Wordstat
However, it is obvious that for some keywords Wordstat gives incorrect information. Is this related to any cheating options and how to determine such pacifiers I will try to explain. Of course, checking all the phrases in this way can be tedious and probably just needs experience (feel), but it works quite well.
Personally, I proceed from the premise that they cheat, as a rule, not for years on end, which means that the deviation from the average frequency value can be tracked on the graph "Request History"(the switch is hidden under the service request input line Yandex Wordstat). For example, I recently ran queries related to " affiliate program” and just ran into cheating (almost all keys related to the topic).

It’s just that I’ve been working with these requests for a long time and I roughly know the “layout”. There, the HF one or two miscalculated, and then what is not the key, then the HF. But just look at the history of the frequency of this query in Wordstat (don't forget to remove the quotes beforehand) and everything becomes clear (they started spinning since the beginning of summer):

Moreover, the frequency of the request has grown almost by two orders of magnitude in a few months, and a couple of years before that it was stable and did not even undergo special seasonal fluctuations. Explicit cheating - I don’t know why, but they twist all the accompanying keys.
How to automate the collection of keywords in the Yandex service
In principle, you can work through the web interface, but it's very dreary. There are programs (paid and free) suitable for this purpose. There are even browser extensions that allow you to beat the routine a bit. Let's just list them:
Why is there such a high frequency of queries with repeated words?
If you have already more or less immersed yourself in the issues of compiling a seed and parsing a lot of queries in Wordestat, then you probably met strange queries with repeated words, which for some reason have a high frequency even when they are enclosed in quotes and exclamation marks are placed before words.

Even if you add “watch” a few more times, the frequency will still remain almost the same high. So what, believe Yandex and optimize articles for such nonsense? Not on your nelly. This is another kind of "dummy". In fact, Wordstat perceives only one of the repeated words, but “mentally” replaces the rest with other possible words with the same number of characters. In general, despite the large numbers, you should not pay attention to requests with repeated words. This is a phantom.
Completing the compilation of the semantic core
As I said a little higher, we will consider the default HF and VC, which means that in order to move through them, you need to choose those pages of your site that will have the highest static weight. This one is recruited by incoming links to this page.
It is important to understand that when it is calculated, the content of the link anchor is not taken into account and it does not matter whether it is external or internal. Read more about the given link.
That. for advancement on the highest frequencies requests (from the compiled semantic core) are most suitable for the main page, because, as a rule, links will lead to it from all other pages of your resource (with a normal structure), as well as most external links especially those obtained naturally. So the static weight of the main resource for most resources will be the highest (previously it could be understood by the indication of the Google PageRank toolbar value, which for it will always be higher than for internal ones, but now Google has decided to stop sharing this information with us).
With all other things being equal (the same quality of internal and external optimization), search engines will rank higher the page whose static weight is higher. Therefore, if you choose to advance on treble inner page(with obviously lower stat weight), then competitors will have an advantage over you if they promote by the same keywords, but already home page your site. Although, the best way there will be an analysis of the Top 10 for the keyword you need in terms of the number of main ones that are involved in the ranking (this, by the way, indirectly indicates the competitiveness of the request).
If the structure of the internal linking of your future project includes other pages with a large static weight (sections, categories, etc.), then in the semantic core you will need to mark them as potential candidates for optimization for more or less high- and medium-frequency queries from the ones you have selected.
In this way, you will be able to use the features of the distribution of static weight on your site to good use and, in accordance with this, select the most suitable queries in terms of frequency for each of the pages, i.e. compose a fully semantic core: match pairs query - page.
However, when optimizing a page for promotion by a HF or MF key phrase, you can add a lower frequency keyword, which will be obtained by diluting the main key. But again, not all keys can be made neighbors on the same landing page . To understand which ones can and cannot be used together, you can analyze your direct competitors in the Top 10 for the main keyword. If they are in the Top, it means that the search for their version of the seed is to their liking.
However, easy to say and hard to do. Try to search the output for hundreds (thousands) of queries from your preliminary semantic core regarding their compatibility or incompatibility. Here, for sure, "horses can be moved." However, I will come to your aid here too by giving a link to a detailed publication about. In reality, everything is simplified by a small program.

With external optimization (purchasing and placing links with the necessary anchors), you must again take into account the created semantic core and put down backlinks taking into account those keywords for which it was optimized this page your site. Do not forget that in the era of Minusinsk and Penguin, it is better to put a backlink with a direct entry, but from a very bold and thematic site, and “dilution” with anchors, article titles, etc. worth doing more.
In practice, your semantic core will probably represent a fairly branched scheme of pages with keywords selected for them, for which they will be optimized and promoted. The scheme of internal linking for pumping will also be drawn there. desired pages static weight.
In general, everything that is possible will be included and considered, all that remains is to start building (or redoing) the site according to this project(semantic core). Personally, lately I have always followed the rule of pre-compiling it, because working blindly may not be a profitable occupation - I will spend my energy, and those who find the material interesting and useful will not find it either in Yandex or Google ...
If we talk about this blog, then before writing an article, I will definitely go to Wordstat and see how users formulate their questions on the topic I plan to write about. Thus, I more likely I will find my reader, who, with successful publication, can become permanent. This is not bad for anyone, except that you just have to spend a little time.
Well, in the case of a project on a new topic for you, and especially if you are a novice optimizer, compiling such a core and selecting suitable keywords can help you a lot and help you avoid unnecessary mistakes. However, not everyone has the time and energy to carry out such work, but do it anyway a must. However, if there is demand, then there will be supply. There will always be people who will be ready to do it for you, another thing is that they may not always be honest and efficient.
Good luck to you! See you soon on the blog pages site
You can watch more videos by going to");">

You may be interested
 Yandex, Google and Rambler search query statistics, how and why to work with Wordstat
Yandex, Google and Rambler search query statistics, how and why to work with Wordstat  Accounting for the morphology of the language and other problems solved by search engines, as well as the difference between HF, MF and LF queries
Accounting for the morphology of the language and other problems solved by search engines, as well as the difference between HF, MF and LF queries
Hi all! Today I want to talk about the rules for working with the wordstat.yandex.ru service, which provides statistics on Yandex search queries. I use this service very often. Mandatory before writing each article.
The fact is that it is important not just to write an article, but to do it right from the point of view of search engine optimization. Each article should be tailored to a specific word or phrase, which is called a key or just a key. These keywords are how users find your site using search engines.
In fact, the key is the search term you are promoting in search engines ah in the hope that people will come to your site using it. Of course, in order to decide on them, you just need to have an idea of how many people use it in a certain period of time. After all, if the frequency of use is small, then it is completely pointless to promote it.
Note that it is not always worth choosing the most frequently used search query, because the competition for them is very high. Be sure to read about - this information will allow you to choose the right keywords for your site.
As you know, in Russia there are two flagship search engines - Yandex and Google. Each of them provides its own service for viewing the frequency of search queries. Today we’ll talk about Yandex keyword statistics -.
Rules for working with wordstat.yandex.ru
The wordstat.yandex service supports five filters that allow you to get comprehensive statistics for the desired keyword.
1. By words (used by default). On the left, we indicate the region in which we want to see the statistics of impressions of this search query in Yandex.
Enter right word or a phrase and click "Select". If you do not use additional operators, which I will discuss below, wordstat.yandex will return the result in the form of two lists. The list on the left shows statistics on queries containing the word under study. The list on the right will show you what else people were looking for using the query you entered.

The main mistake is that in the absence of additional operators, wordstat.yandex will give the number of impressions per month, which corresponds to all search queries that contain the entered phrase in different word forms. Be sure to use operators to be specific.
Word form - the form of a word obtained from the main part of the word by conjugation or declension.
2. By regions. Shows keyword statistics by region and city. You can select statistics separately for cities and separately for regions. In addition to displaying the number of impressions per month, another value is indicated - regional popularity.

The name speaks for itself: regional popularity is a conditional value, measured as a percentage, showing the popularity of this request in a certain region/city.
- 100% - the request is nothing remarkable.
- More than 100% - there is an increased interest.
- Less than 100% - reduced interest.
- 0% - not used at all in this region.
3. On the map. Keyword statistics from Yandex by region, presented no longer in the form of a table, but visually on the Mira cart. Hover your mouse over the desired region and see the number of impressions per month and regional popularity. To zoom in, click on the country and go to its subjects.

4. By months. Monthly statistics. Just do not forget to specify the region for which it will be displayed. Information is given in the form of a graph, both in absolute and relative values (you can choose). The graph is a broken line. The coordinates of each vertex are the number of impressions (by Y) and the month (by X). It all sounds a little abstruse, but in practice everything is very simple. Just take a look at the picture.

5. Weekly. Identical to the previous filter, only now the time interval is not a month, but a week.
Yandex.WordStat operators
Additional operators are designed to customize the statistics received. Let's look at them with examples, so that everything has become very clear.
1. - (minus operator). The "-" operator is placed before the word to be excluded. The operator is preceded by a space.
Example. If you specify in the search games - computer, then get statistics for all queries containing "games" except for those containing "computer". You can exclude several words at once by putting a "-" operator in front of each of them (just remember to separate them with spaces). For example, games - computer - board. All queries containing "computer" or "desktop" will be excluded from the results.
2. () (grouping operator "brackets"), | (logical operator "or"). At sharing allow you to create very complex queries.
Example. Request server (dedicated | local) equivalent server remote And server local.
3. "" (quotation mark operator). A very important operator that allows you to specify the query. Only impressions of the given word and its word forms will be taken into account. All requests that include additional words will be filtered out.
Example. Query "table". The number of impressions of the words "tables", "tables", "table" will be given, but excluded with an additional word - "tennis table", "computer table" and others.
4. + (plus operator). Placed before prepositions so that they are taken into account.
Example. Installing wordpress + on denwer the preposition "on" will be taken into account.
5. ! (exclamation point operator). The word preceded by the "!" operator is taken into account in its exact spelling. All word forms are eliminated.
Of all these operators, "" and! are most often used, allowing you to specify the statistics received from Yandex. Let's say the result of input "!installing!wordpress" will be the number of impressions of the query wordpress installation and no other.
It would seem that at first glance the wordstat.yandex.ru service is very simple, but what great functionality is hidden in it! I strongly recommend to understand and master it.
Thank you for your attention. Take care of yourself!
What is Yandex.Wordstat
It provides monthly statistics of impressions of search queries that users set in the Yandex search engine. Let's say I wrote the phrase "2016 is a leap year or not" in the search bar. In Yandex.Wordstat, you can find out how many times during the month Yandex visitors were interested in the same thing.
Why you need Wordstat

How wordstat works
A simplified example of how words are sorted in Wordstat:
news Russia 4
news Russia Ukraine 1
Russian business news 1
Russian football news 1
news Russia Ukraine 1
business news of Ukraine 1
Ukrainian football news 1
news 8
news Ukraine 4
green numbers is the number of impressions. Each phrase was asked word for word once. They asked “news” once, they asked “Russia news” once, they asked “Russia news Ukraine”, “Russian business news”, “Russian football news” once each. Total together 2 words "news Russia" occur 4 times. It does not matter in what word form (“Russia”, “Russia”) and in what sequence (“news Russia”, “Russia news”). The word "news" - 8 times, since "news Russia Ukraine" is given once, and is mentioned in two groups "news Russia" and "news Ukraine".
Instructions for using Wordstat
In the search box, you need to enter the desired key phrase, for example, "2016 is a leap year or not" 
Impressions: 50,741. This figure includes all queries listed below: and "leap year" whether 2016" and "leap year 2016 signs", And " can get married leap year 2016”, etc. If you click on "leap year 2016", then there will be 4 or more word queries.
“Leap year 2016” has the same number of impressions. These phrases are identical, since in Yandex.Wordstat:

Operators Yandex.Wordstat
Plus operator + : take into account specified pronouns, prepositions, conjunctions, particles


Vertical bar operators | "or" and parentheses () "grouping": take into account the listed synonyms




exclamation point operator ! : search for a word only in the given word form


Not all queries are shown by default, for example "no leap years" appears when searching for "leap! years".
Minus operator - : remove certain additional words


Quote operator " " : limit query length (number of words)
1 word. The query ""year"" is used less frequently than ""leap year"". It's clear. What do people expect to see? What is the year now? What is a year? 
2 dictionaries 
3 dictionaries: here again it seemed “no leap years” 
4 dictionaries 
12 dictionaries. I don’t even want to think how they can be formulated. 
Notes:
- Identical words are combined, quotes limit the number of words, as a result, any other words are substituted for the second and subsequent identical words.
- Do not be surprised that there are no 5 dictionaries, but there are 6 dictionaries.
- Pronouns, prepositions, conjunctions, particles are included in the query in quotation marks. It is not necessary to write a plus in front of them.
- You cannot combine quotation marks with minus, vertical bar, brackets operators.
Square bracket operator : respect word order


Notes:

Official explanations: Yandex.Help, AdWords blog
Region in Wordstat: how to view keyword statistics only within one region or one city

How to find out in Wordstat how many views an exact entry has
An exact match is needed to formulate phrases:
- For contextual advertising(for example, Yandex.Direct, Google AdWords),
- For ,
- for headers.

Number of impressions: 6
- for commercial sites, in most cases, you need to remember to set the region.
- the entire phrase should be enclosed in quotation marks and square brackets.
- prescribe an exclamation mark before all words (you can not put it before prepositions, conjunctions and particles).
It is worth remembering that 5000 impressions in Yandex.Worstat will not bring 5000 people to the site page, because:

How to Collect All Wordstat Queries
For the initial query "how to choose a plot for building a house" from both columns, you should select words suitable for the topic 
Expand the search by first removing the word "construction", then "select", etc. 
Rare phrases can be collected from search suggestions, including using special programs 
You will get approximately such a table where you can combine cells. For example, “choosing a place for a house”, “how to choose the right site for construction”, etc.
| choose | plot | For | |||||||
| How | Right | pick up | good | land plot | under | construction | apartment building | house | in the country |
| Which | choice | suitable | place | the buildings | multi-storey | izhs | in the village | ||
| selection | place on the lot | summer cottage | cottage | in the city | |||||
| earth | private | house | |||||||
| country |
Hello guys! All of you know very well that I have been selling keywords for a long time. I mean, I've been doing this on a commercial basis for a long time.
All those services that I have described have been expanded many times by me for a long time. Various perverts come in who come up with such tasks that I would not have thought of before. Well, I’m gradually mothering due to the fact that they force me to complete their difficult tasks.
Probably everyone remembers that I wrote many times about Pastukhov's databases: a long time ago I told what this awesome software is, then I told that Maxim Pastukhova (the author of the software) announced the release of the 180 millionth Russian database of keywords. This .
But recently I did a project for the site of a respectable person. The project was exclusively for Yandex. I parsed his site, found the keys for which he already occupies normal positions in the search results, evaluated these keys using wordstat, rambler, Rookee ... that's it, we slow down.
The result is a list of good keys. But! They produce many ambiguous keys. Here they are

That is, we take for example the key " radio radio listen online". We look at the frequency according to wordstat. Here is a screenshot showing the exact frequency. That is, the operator "! word! word" was used. And what do we see? That this key has a frequency of 563141 for my region, for which the analysis was made.
The client immediately asks me: “Sergei, what the hell? Where did the unfortunate radio radio listen online"563141 impressions per month?" And Rookee's click prediction shows -1 clicks on that key, which means xs how many clicks there will be. That is, it says that there will be 0 of them.
And then I just doper, that epta, because it is great idea for the post - to paint this zalepa, which is in the wordstat, especially since Maul recently wrote about it. Only I will tell about it from my bell tower, and I will show in addition how this problem is solved.
And what's stuck, then stuck. Here's how to understand what it really is? The first thing that comes to mind is to go to the help of Wordstat itself, and read what they themselves write about it. But no, the only thing we see:
And what is the result? And nothing! From what is written here, not a damn thing is clear why blah at the request " radio radio listen online» such a large number of impressions.
And in fact, this zalepka has a simple explanation. We open fresh databases of Pastukhov for 180 million kei, we make a selection from the database for the keyword "listen to radio online"

I think those who often delve into the wordstat are well aware that pulling out such keywords from there is almost unrealistic.
By the way, these are not the longest keywords. IN pastukhov's bases I added a display of the frequency according to wordstat.yandex. Look, there are cooler, or rather, more authentic keys

Or here's another
It's clear, 10 vocabulary " internet radio online listen free europe plus mediaplayer classic» cannot have a frequency, and if it can, it is so insignificant that it is not displayed in wordstat. But the fact is that such verbose people create this slap with keywords. See for yourself

What do we see here? We see that the ten words ” has a frequency of 5967, which in itself seems to be some kind of utopia.
So why is it so?
There is one feature in wordstat - in it don't give a fuck the order of keywords, in connection with which if you do not understand this whole mechanism, then you can stupidly squander the bablos, moving in the future keywords that do not give traffic at the output.
All this is very clearly visible when we add a column with query statistics to Rambler in Pastukhov's databases, in which the word order don't give a fuck. Then the picture becomes immediately clear, and we see for which requests there is a system, and for which it is not. That is, which requests are entered regularly, which ones can really be promoted, and which ones simply create statistics for such zalep that I showed above. Here in Pastukhov's databases, it is especially amazing that you can immediately estimate the frequencies of Yandex and Rambler for a single keyword

I have specifically grouped the requests here to make it clear. That is, ideally, if you promote, then take such keys, where there will be a frequency for both Rambler and Yandex. But this is ideal.
And yet, how is it that a 10-word query with repeated words can have a frequency of 5967?
I xs to be honest, why didn’t they write it down in the Wordstat help, why can this be. But here's the point.
As already mentioned above, in Yandex they enter a lot of queries, among which there are many ten-word ones. And even more. Often this information cannot be pulled out from the wordstat, but all these keys show Pastukhov's bases well (note - now a closed project). And the clue itself lies in the fact that duplicate words are not taken into account directly in the query.
That is, the request "!radio!radio!radio!radio!radio!radio!radio!radio!listen!online”, which has a frequency of 5967, in fact, in exactly the same form, it is not shown as much as it displays the wordstat. Only the phrase “listen to radio online” is taken into account here. That is, the last three words. And instead of the previous 7 words “radio”, completely different words can be used. And all this creates statistics for this ten words. I specifically made a selection of the results obtained from the “radio listen online” in Pastukhov's databases. There you can sort by the length of search queries, and by the number of words.

And as a result, we get all (or almost all) ten-word keywords, which make statistics for our "!radio!radio!radio!radio!radio!radio!radio!radio!listen!online". Here they are:

And there are more than enough such ten words. That is, I repeat once again that instead of the word "radio" there can be any other word, as long as it is included in the ten words, which contains the phrase "listen to radio online."
The situation would not be so ambiguous if the wordstat showed the keywords in exactly the same order as they are requested. But no. In our ten words, instead of the word "radio" there can be any other words, and all of them can be interchanged within this ten word list, thereby winding up its indicator in the wordstat.
That is why it turns out that the request " radio radio listen online' actually in exactly the same sequence and with exactly the same words as indicated here, does not have a frequency of 563141 and never has. And such a figure is obtained, because instead of the first word "radio" there can be any other, and it can stand in any place within this four-word list, which ultimately forms such a large figure in 563141. And there are a great many such four-words of different interpretations
Hello, dear readers of the blog site. I want to once again touch on the topic of selecting keywords for individual articles and the entire site as a whole. This will allow you to more accurately reach the audience that may be interested in your publication.
Potentially. Those. this does not guarantee success, but it allows you to hope for it. In other words, this is a necessary condition for the successful development of the site, but not sufficient at all.
The most popular tool that allows you to analyze the statistics of the use of various words and phrases in queries of search engine users is the tool "Selecting words" from Yandex(famous WordStat). It is intended for advertisers who advertise in, but this is not the essence of it, because the statistics it produces can also be useful for optimizing your own site.
You can work with Wordstat both manually and with the help of special programs. If you need to break through one or two key phrases according to Yandex query statistics, then it will be easier to go to the site indicated just above, but if you want to collect a database of keywords for yourself on the topic you need, then automation will be indispensable.
Online service "Select words" from Yandex
I understand that there are more than enough publications on the topic of compiling a semantic core on the Internet. But, it seems to me, they were written mainly by those who deal with this matter professionally, i.e. SEO optimizers or freelancers. The methods they describe are quite interesting, because they allow you to automate and simplify the process of building the kernel, but for me personally, they make me bored when reading.
The little things and nuances they describe help save time with a large stream of projects that pass through their hands, but if you have a task choosing keywords for your own website, then in most cases, excessive automation can even interfere, because something can be missed or not taken into account.
Here, it seems to me, there is no need to rush. For example, I once bought a wonderful program with Profit Partner bonuses Key Collector. Here. He twisted it, turned it, and put it on the far shelf. Why? Yes, it’s just not for me - it’s difficult to master and understand the usefulness of all the richest functionality available in it. For the same reason, I use Yandex Metrica, not Google Analytics.
Of course, I'm wrong and it was necessary to rest against the horn and achieve an understanding of all the chips available in the Key Collector (unconditionally useful). But in reality, I downloaded from the site of the same developer a light version of this word selection program, though under an unpresentable name Slovoeb(written in Russian letters, it is not very printed).
That's it, now I work exclusively with him, and the Key Collector has once again blocked me after updating the system (it has a link to the computer configuration) and I'm too lazy to write off the author again to revive him.
Therefore, today I will only talk about the manual use of the “Word Selection” tool from Yandex, about using Slovoeb in order to quickly obtain statistics on thousands of key phrases at once and screen out dummies. There are other tools like Wordstat (you can read about them in the article about), but they have not gained such wide popularity.
In general, of course, working with Wordstat is outrageously simple in terms of theory, but rather dreary in terms of practice. By the way, not so long ago they changed the design, but not only. According to subjective feelings, the speed of parsing new version online tool the choice of words has increased significantly.
Where to begin? From calmly thinking about the current situation and what you would like to get as a result. You have the subject of your resource (future or existing). Under this topic, you can immediately pick up a dozen or two phrases or words that may be related to it. How to understand which of the phrases spinning in your head have a perspective?
You need to look at the statistics of their use when accessing the Yandex search engine. For this purpose, Wordstat is needed. True, recently it has been available only to registered users, so you will first have to, and also add to it.
If you already have all this goodness, then it will not hurt to remember your authorization data, because they will have to be entered into Slovoeb to make it work. Then enter your first request in the appropriate form on the service page Word choice :
Oh, how much has happened. Wordstat provides keyword statistics for the last calendar month. This means that in a year it will be possible to get a number even an order of magnitude larger. Although this is not entirely true. One of the reasons may be the fluctuation in the frequency of the request from the time of year (i.e. seasonality).
You can check this by checking the box "History of Requests". For clarity, let's take, indeed, something with a pronounced seasonality, where the frequency of entering a given keyword in the Yandex search string, depending on the time of year, can change six times.

If the query you are interested in has a regional reference, then this will also significantly affect the frequency of its entry into Yandex. In order to understand this, just click on the link "All regions" and choose the location you want.
For example, this is how statistics on the Yandex audience that is interested in pizza delivery in a small town will look like.

In addition, many SEOs and site owners check) for all kinds of keywords, and do not always use their own for this. And this means that cheating is happening(not special) frequencies. Therefore, one should not recklessly believe the figures of this statistics and should not take it literally.
And without it, everything is not so simple. If it were statistics solely on the use of this one word (phrase) that you entered, then everything would be great. But the Yandex word selection service, when entering a query into it without any additional operators, takes into account in the figure shown all the phrases in which this phrase was used (in any word form).
For example, if we return to the first screenshot, we can say with confidence that almost 900,000 times a month, Yandex users entered queries in which the word Joomla was found (for example, “templates for Joomla” or “the most popular sites in the world on the content management system Joomla").
This statistics will help you assess the prospect creating a site or a separate section on this topic, but when writing specific articles, you will need to use other figures that have more specifics. Where to get them? Good question which we will now try to answer.
How to collect statistics on the actual frequency of queries (Wordstat operators)
Before proceeding to practice, I want to dwell on those Wordstat operators, which can be used in the Yandex keyword selection service. Actually, there are very few of them. I think that no one can tell about them better than this service's own help.
Personally, I only use two of them - quotes and an exclamation point. You are free to do as you see fit.
So, quotes force the search engine to share statistics on entering only this phrase. However, this will take into account all possible word forms of the words contained in it (cases, numbers). For example, like this:
Strange, isn't it? The figure has decreased three times. How else can you formulate this query to a search engine? Well, if you think about it, it’s most likely in the plural, especially since the remaining numbers can immediately be seen where they have gone:
Well, with the theory, consider it over, it's time to start practicing. All my projects are informational in nature and therefore seasonality and regionality of requests do not bother me much. If you have a different situation, then you will also have to take into account these data in order to understand the prospects.
What you need to consider when assembling the semantic core of the site
When it comes to perspective. Assembly consists of several stages:

When developing a semantic core, it is very important to start somewhere (to cling to something). A few key phrases taken from your competitors, taken from your head or obviously suggestive, will be your starting point. But be sure to continue the search process and always have a piece of paper handy so that you can write down the idea that has arisen and then look at the statistics in the Yandex word selection service to make sure it is valid.
From any high-frequency query, you can use Wordstat or Slovoeb to get dozens or even hundreds of keywords for your future articles. How to do it? First you need to find such high-frequency speakers. These are the most obvious phrases that users use when contacting Yandex when they want to get an answer to a question on the topic in which you want to get involved in creating a site.
For example, for my blog, these could be the words Joomla, WordPress, website promotion, website promotion, earnings, etc. You can start with them. But many people do this, so it would not be bad if you tried to put all the ideas for future articles that come to you into those requests by which Yandex users could find them. We must try to think like an ordinary Internet user asking a question to a search engine.
Selection of words for the seed directly in Yandex Wordstat
OK. Water can be poured for a long time. Let's type the query "Website promotion" in Wordstat and see what it can pick up for you and me.

Amazing. We received a lot of information, which now we will need to try to process somehow. Yandex picked up the words for us based on the phrase we entered and distributed them into two columns. Both are very important.
In the left column of Wordstat all phrases where the entered keywords directly occur are collected. To the right of them, the frequency of their request from Yandex by its users is displayed. But do not rush to rejoice, because this frequency is fake in most cases (). Those. the numbers written there may actually be fiction.
How to check it? Well, the first thing that comes to mind is to open another Wordstat window on a new browser tab and enter all these phrases from the left column in turn into it, enclosing them in quotes.

That's when you get real statistics (well, or closer to real). You can copy these phrases into a Word or Excel document and add the frequencies calculated in this way.
Just? Theoretically, yes, but in practice, after checking a dozen phrases from the left column (from the above screenshot) in Wordstat, opened in a new tab, you will want to score all this and go get drunk (well, or hang yourself).
Routine, it does not please everyone. But the left column of the "Word Selection" service window also has pagination. Imagine, there can be up to 50 pages, which in total will give 2000 selected key phrases. And all of them will need to be checked manually by enclosing them in quotes. Perhaps what is within the power of units.
And that is not all. We forgot about right column of Yandex Wordstat. And it's just amazing stuff. It displays requests from the same users who entered the phrase from the right column, made by them in the same search session. This will allow you to significantly expand the semantic core of the site and sometimes even in a very unexpected direction.
What to do with all this wealth from the right column? View its content and all the phrases that are related to your topic, and then punch them in again open tab browser with Wordstat. In our example, the phrase “website optimization” is striking with a high (potentially) frequency.

And what do we see here? And again, a lot of interesting things. From the left column, you will need to check all the phrases for fake by enclosing the phrase in quotation marks. And the contents of the right column can be checked for finding something new there that you have not yet added to your semantic core.
And so for many hours you can sit with the pages of the Yandex Word Selection service open in different browser tabs so as not to miss anything from potential keys and at the same time weed out all the dummies. After a while, however, you will want to give up all this, because the efforts and perseverance here are needed in truth, not human.
It is precisely against the background of such torments of manual selection of keywords that you will feel the beauty of Key Collector, or its lightweight version called Slovoeb. What a thrill it is (without exaggeration) to drive into the program some one that comes to your mind high frequency request, parse automatically all pages from the left column of Wordstat, after which also automatically weed out pacifiers.
The resulting list of actually requested keys can be sorted in descending order of frequency and stored in CSV format for further analysis and breakdown by articles. By the way, the process of distributing keywords among articles can also be automated. I learned about this quite recently from the mailing list of the exchange ContentMonster(I buy articles recently mostly only from them).
It turns out that there is online service KeyAssistant under the auspices of this exchange (it's free, as I understand it), which allows you to scatter keys across pages, and pages into sections. It is quite a long time to explain its functionality, so I suggest watching a “movie” on the topic and, perhaps, it will interest you:
Okay, we digress, but in the meantime it's time to get acquainted with our today's hero with an extremely unassuming name.
How to automate the selection of words from Yandex in Slovoeb
Download Slovoeb you can follow the link provided. It does not require installation - just unzip the downloaded archive and run the Slovoeb.exe file
Immediately after launch, it makes sense to go to the program settings, where on the tabs "Parsing" - "Yandex Wordstat" in the area "Yandex account settings" you will need to enter at least one login-password pair (separated by a colon and without spaces) to access the services of this search engine. For what? I have already mentioned that recently Wordstat allows only authorized users to use it.

note that it would be better to create new accounts in Yandex(fake ones, i.e. not the main ones, where, for example, you work with YAN or money). Why? The search engine does not allow parsing its output directly (instead, it provides limits for the work of XML output), so you can grab an account ban for showing excessive impudence.
It also makes sense to set the maximum number of pages from the left column of Yandex's "Word Selection" service that will be parsed (50). This will come in handy when punching through high-frequency requests, because. there could be a lot of options out there. Sometimes even on last page the total frequency is several thousand, which means that not all keys can be collected using Wordstat (unfortunately).
If you don’t want to heavily load and anger Yandex, then on the first tab of the “General” settings, increase the range of timeouts (breaks between submitting requests to the search engine).

Save the settings and click on the "Create Project" button, or on the "Open Project" if you have not completed some work before.

Give the project a name, and then enter the key phrase or word you are interested in in the line that appears. Entered? Okay, press Enter on your keyboard.
Yes, there is an alternative. Click on the button "Left column of Yandex Wordstat" and enter into the opened form several phrases at once (one per line), the statistics for which you want to parse. Then press the button located below and you get several lists merged together at a time.

In the modern version of Slovoeb, you will have to wait five minutes or a little less until it docks with Wordstat (this happens only after the program is launched, and in further work there will be no such delay.
After the parsing of the left column of the "Word Selection" service will start for this phrase to the depth (number of pages) that you set in the settings. I always have 50 installed there. As a result, you will get no more than 2000 keys including your original phrase.

For example, I took the super high-frequency request "work". As you can see, even on the last page of Wordstat, the total frequency of phrases exceeds ten thousand. Therefore, in this case we cannot this tool cover the entire pool of requests and much remains behind the scenes. Pulling out the "tail" is also probably possible, but this is already much more difficult and less reliable.
So, we just parsed the keys, but we still need to separate the wheat from the chaff, i.e. understand which of these keywords make sense to continue to use in the semantic core, and which ones to discard due to their extremely low real frequency. The latter is calculated by enclosing the phrase in quotation marks or even with the addition of exclamation marks.
In Slovoeb, all you need to do is select buttons from the drop-down menu "Frequencies Yandex.Wordstat" the last or penultimate paragraphs. You should already understand the difference between them, so choose what you see fit. For some reason, I prefer the latter option, but this may unnecessarily limit the results.
Punching the real frequency in Slovoeb is much slower than parsing, and what is important, do not go to Wordstat through the browser at this time, because, on which this program I'm stuck. It is possible that this problem occurs only on my computer, but still it is worth warning.
You can follow the process of checking the real frequency with your own eyes - new numbers will appear in the corresponding column in real time. Although it makes sense to let this matter take its course and go do something more useful, you can only periodically look into the program. At the end of the collection process, the red hexagon in the upper left corner will turn gray.

If you wish, you can stop the process yourself by selecting the appropriate item from context menu this button. The project can be saved and Slovoeb closed. And then open the program and the saved project again, and then continue collecting statistics using the method described above. Very convenient and, most importantly, just to disgrace.
Here. After finishing the process, you can sort the results in descending order of frequency by clicking on the heading of the column with statistics of phrases enclosed in quotes, or with them and exclamation marks in front of each word. It will turn out very clearly, because the most promising (albeit often not real due to high competition) requests will be at the top of the list.

I advise save all received as a result of the selection of keywords lists to file. This is done in Slovoeb using the icon shown in the screenshot, located at the top of the program window. Saving is in CSV format, which, if desired, can be opened with regular Excel, the main thing is to specify the correct column separator so that everything grows together.
If it does not work, then in the program settings on the "Interface" - "Export" tab, select a different save format (xlsx). You can also see the separator used when exporting to CSV.

Extra columns in Excel can be deleted (or removed in the same export settings by simply removing the checkmarks from the columns you don’t need - see the screenshot above), so that they do not reduce visibility. Personally, I leave only the key phrase itself and its real frequency, and everything else goes into the furnace.

Actually, you can already work with these lists, taking something from there directly, and punching something again through Wordstat in order to obtain new keys (for example, not a complete phrase, but a word or phrase found in it, which in itself can generate lots of options). In general, the process is very creative and, due to its strong automation, is not very tedious, especially in comparison with the manual method of using the Word Selection service described above.
Other features of Slovoeb for collecting statistics
Yes, I forgot to mention that Slovoeb can also collect search hints. This is what drops out when you enter a query in the Yandex or Google search box.

Among them, there may also be quite interesting variants of keywords, which can then be checked using the method described just above for their real frequency.
Previously, there was a separate utility for this (SlovoDer) from the same developer (Alexander Lyustik), and now this functionality is enclosed in one program. To collect search suggestions, just click the corresponding button on the Slovoeb toolbar.
In the window that opens, you need to check the boxes next to those search engines from where these tips will twitch.

Actually, you should also specify the keywords for which these tips will be collected and click the "Start collecting" button. The collected keys from the hints will be added to the general list, so that later you can check them all in a crowd and collect statistics on the frequency of use.
In the general list, they will be marked with a different icon so that you can work with them more clearly and distinguish between Wordstat parsing and search suggestions.

The same applies to collecting words from the right column of Wordstat(Slovoeb can parse it too).

A little higher in the text, I said that it is very important when assembling the semantic core to pay attention not only to the frequency of the selected words and phrases, but also to the fact how high is the competition exists in the issuance of Yandex and Google for these queries. The higher it is, the more difficult it will be for you to break into the TOP.
To evaluate it, many suggest using the number of search engine responses that they give to a given query. A little higher I wrote about this in more detail. So, our wonderful program can parse this very number of answers from Yandex and Google search results.
Those. for all the collected words, you can break through their competition with the help of a button KEI on the Slovoeb toolbar:

The KEI parameter is obtained and, in order to rely on it, it would be better to use the Key Collector ( paid version given free program with significantly more advanced functionality).
As you can see, even the simplified version of the program has quite rich functionality. What can we say about the Key Collector. Another thing - do you need this functionality? Personally, it turned out to be very difficult for me to find time to master it, especially since I did not see any special prospects in this. I am wrong? Dissuade me in the comments then.
Nevertheless, not everyone has the time and energy to carry out such work (collecting a complete seed), but do it anyway a must. However, if there is demand, then there will be supply. There will always be people who will be ready to do it for you, another thing is that they may not always be honest and efficient.
I’ll allow myself the impudence and end with a video taken from Maxim Dovzhenko’s blog, where he talks about the settings and selection of words in Slovoeb: