Символьные функции sql. О строковых функциях SQL или как манипулировать текстом в базе данных MySQL
Читайте также
Вот полный перечень функций работы со строками, взятый из BOL:
| ASCII | NCHAR | SOUNDEX |
| CHAR | PATINDEX | SPACE |
| CHARINDEX | REPLACE | STR |
| DIFFERENCE | QUOTENAME | STUFF |
| LEFT | REPLICATE | SUBSTRING |
| LEN | REVERSE | UNICODE |
| LOWER | RIGHT | UPPER |
| LTRIM | RTRIM |
Начнем с двух взаимно обратных функций - ASCII и CHAR .
Функция ASCII возвращает ASCII-код крайнего левого символа строкового выражения, являющегося аргументом функции.
Вот, например, как можно определить, сколько имеется разных букв, с которых начинаются названия кораблей в таблице Ships:
Следует отметить, что аналогичный результат можно получить проще с помощью еще одной функции - LEFT , которая имеет следующий синтаксис:
LEFT (<строковое выражение >, <целочисленное выражение >)
и вырезает заданное вторым аргументом число символов слева из строки, являющейся первым аргументом. Итак,
| SELECT DISTINCT LEFT(name, 1) FROM Ships ORDER BY 1 |
А вот как, например, можно получить таблицу кодов всех алфавитных символов:
|
SELECT CHAR(ASCII("a")+ num-1) letter, ASCII("a")+ num - 1 FROM (SELECT 5*5*(a-1)+5*(b-1) + c AS num FROM (SELECT 1 a UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4 UNION ALL SELECT 5) x CROSS JOIN (SELECT 1 b UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4 UNION ALL SELECT 5) y CROSS JOIN (SELECT 1 c UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4 UNION ALL SELECT 5) z ) x WHERE ASCII("a")+ num -1 BETWEEN ASCII("a") AND ASCII("z") |
Тех, кто еще не в курсе генерации числовой последовательности, отсылаю к соответствующей статье .
Как известно, коды строчных и прописных букв отличаются. Поэтому чтобы получить полный набор без переписывания запроса, достаточно просто дописать к вышеприведенному коду аналогичный:
Я полагаю, что не будет сложным добавить эту букву в таблицу, если потребуется.
Рассмотрим теперь задачу определения нахождения искомой подстроки в строковом выражении. Для этого могут использоваться две функции - CHARINDEX и PATINDEX . Обе они возвращают начальную позицию (позицию первого символа подстроки) подстроки в строке. Функция CHARINDEX имеет синтаксис:
CHARINDEX (искомое_выражение , строковое_выражение [, стартовая_позиция ])
Здесь необязательный целочисленный параметр стартовая_позиция определяет позицию в строковом выражении, начиная с которой выполняется поиск искомого_выражения . Если этот параметр опущен, поиск выполняется от начала строкового_выражения . Например, запрос
Следует отметить, что если искомая подстрока либо строковое выражение есть NULL, то результатом функции тоже будет NULL.
Следующий пример определяет позиции первого и второго вхождения символа "a" в имени корабля "California"
|
SELECT CHARINDEX("a",name) first_a, CHARINDEX("a", name, CHARINDEX("a", name)+1) second_a FROM Ships WHERE name="California" |
Обратите внимание, что при определении второго символа в функции используется стартовая позиция, которой является позиция следующего за первой буквой "a" символа - CHARINDEX("a", name)+1. Правильность результата - 2 и 10 - легко проверить:-).
Функция PATINDEX имеет синтаксис:
PATINDEX ("%образец %" , строковое_выражение )
Главное отличие этой функции от CHARINDEX заключается в том, что поисковая строка может содержать подстановочные знаки - % и _. При этом концевые знаки "%" являются обязательными. Например, использование этой функции в первом примере будет иметь вид
Результат выполнения этого запроса выглядит следующим образом:
То, что в результате мы получим пустой результирующий набор, означает, что таких кораблей в базе данных нет. Давайте возьмем комбинацию значений - класс и имя корабля.
Соединение двух строковых значений в одно называется конкатенацией , и в SQL Server для этой операции используется знак "+" (в стандарте "||"). Итак,
А если строковое выражение будет содержать лишь одну букву? Запрос выведет ее. В этом легко убедиться, написав
Мы продолжаем изучение языка запросов SQL, и сегодня мы с Вами будем разговаривать о строковых функциях SQL . Мы рассмотрим основные и часто используемые строковые функции, такие как: LOWER, LTRIM, REPLACE и другие, все рассматривать мы будем, конечно же, на примерах.
SELECT name || surname AS FIO FROM table
Или чтобы отделить пробелом введите
SELECT name || " " || surname AS FIO FROM tableт.е. две вертикальные черты объединяют два столбца в один, а чтобы отделить их пробелом я поставил между ними пробел (можно использовать любой символ, например тире или двоеточие ) в апострофах и объединил также двумя вертикальными чертами (в Transact-SQL вместо двух вертикальных черточек используется знак + ).
Функция INITCAP
Дальше идет также очень полезная функция, INITCAP – которая возвращает значение в строке, в которой каждое слово начинается с заглавной буквы, а продолжается маленькими. Это нужно для того, если у Вас в той или иной колонке не соблюдают правила заполнения и для того чтобы вывести все это дело в красивом виде можно использовать данную функцию, например, у Вас в таблице записи в колонке name следующего вида: ИВАН иванов или петр петров, Вы применяете данную функцию.
SELECT INITCAP (name) AS FIO FROM table
И у Вас получится вот так.
Функция UPPER
Похожая функция, только возвращает все символы с заглавной буквы, это UPPER .
SELECT UPPER (name) AS FIO FROM table
- name – название колонки;
- 20 – количество знаков (длина поля );
- ‘-‘ – символ, которым нужно дополнить до необходимого количества знаков.
Функция RPAD
Сразу рассмотрим обратную функцию. RPAD – действие и синтаксис тот же что и у LPAD, только дополняются символы справа (в LPAD слева ).
SELECT RPAD (name, 20, "-") AS name FROM table
| Иван—————- |
| Сергей————— |
Функция LTRIM
Далее идет тоже в некоторых случаях полезная функция, LTRIM – эта функция удаляет крайние левые символы, которые Вы укажите. Например, у Вас в базе есть колонка «город», в которой город указан в виде «г.Москва», а также есть города которые указанны в виде просто «Москва». Но Вам нужно вывести отчет только в виде «Москва» без «г.», но как это сделать, если есть и такие и такие? Вы просто указываете своего рода шаблон «г.» и если крайние левые символы начинаются с «г.», то эти символы просто не будут выводиться.
SELECT LTRIM (city, "г.") AS gorod FROM table
Данная функция просматривает символы слева, если символов по шаблону нет в начале строки, то она возвращает исходное значение ячейки, а если есть, то удаляет их.
Функция RTRIM
Также давайте сразу рассмотрим обратную функцию. RTRIM – то же самое что и LTRIM только символы ищутся справа.
Примечание! В Transact-SQL функции RTRIM и LTRIM удаляют пробелы справа и слева соответственно.
Функция REPLACE
Теперь рассмотрим такую интересную функцию как REPLACE – она возвращает строку, в которой все совпадения символов, заменяются на Ваши символы, которые Вы укажите. Для чего ее можно использовать, например, у Вас в базе есть колонки, в которых встречаются некие разделительные символы, допустим «/». Например, Иван/Иванов, а Вам хотелось бы вывести Иван-Иванов, то напишите
SELECT REPLACE (name, "/", "-") FROM table
и у Вас произойдет замена символов.
Данная функция заменяет только полное совпадение символов, если например Вы укажите «—» т.е. три тире она и будет искать только три тире, а каждое отдельное тире заменять не будет, в отличие от следующей функции.
Функция TRANSLATE
TRANSLATE – строковая функция, которая заменяет все символы в строке, на те символы, которые Вы укажите. Исходя из названия функции, можно догадаться, что это полный перевод строки. Отличие данной функции от REPLACE в том, что она заменяет каждый символ, который Вы укажите, т.е. у Вас есть три символа, допустим абв и с помощью TRANSLATE Вы его можете заменить на abc таким образом у Вас а=a, б=b, в=c и по такому принципу будут заменяться все совпадения символов. А если Вы заменяли с помощью REPLACE, то у Вас искалось только полное совпадение символов абв расположенных подряд.
Функция SUBSTR
SUBSTR – данная функция, возвращает только тот диапазон символов, который Вы укажите. Другими словами, допустим, строка из 10 символов, а Вам все десять не нужны, а допустим, нужны только 3-8 (с третьего по восьмой ). С помощью данной функции Вы легко можете это сделать. Например, у Вас в базе есть какой-нибудь идентификатор, фиксированной длинны (типа: AA-BB-55-66-CC) и каждая комбинация символов что-то означает. И в один прекрасный момент Вам сказали вывести только 2 и 3 комбинацию символов, для этого вы пишите запрос следующего вида.
SELECT SUBSTR (ident, "4", "8") FROM table
т.е. мы выводим все символы, начиная с 4 и заканчивая 8, и после этого запроса у Вас выведется вот это:
Функция LENGTH – длина строки
Следующая функция также может пригодиться, это LENGTH – которая просто на всего считает количество символов в строке. Например, Вам нужно узнать, сколько символов в каждой ячейки столбца допустим «name», таблица следующего вида.
SELECT LENGTH (name) FROM tableпосле этого запроса Вы получите вот это.
| 4 |
| 6 |
| 7 |
Вот мы с Вами и рассмотрели основные строковые функции SQL. В следующих статьях мы продолжим изучение SQL.
Последнее обновление: 29.07.2017
Для работы со строками в T-SQL можно применять следующие функции:
LEN : возвращает количество символов в строке. В качестве параметра в функцию передается строка, для которой надо найти длину:
SELECT LEN("Apple") -- 5
LTRIM : удаляет начальные пробелы из строки. В качестве параметра принимает строку:
SELECT LTRIM(" Apple")
RTRIM : удаляет конечные пробелы из строки. В качестве параметра принимает строку:
SELECT RTRIM(" Apple ")
CHARINDEX : возвращает индекс, по которому находится первое вхождение подстроки в строке. В качестве первого параметра передается подстрока, а в качестве второго - строка, в которой надо вести поиск:
SELECT CHARINDEX("pl", "Apple") -- 3
PATINDEX : возвращает индекс, по которому находится первое вхождение определенного шаблона в строке:
SELECT PATINDEX("%p_e%", "Apple") -- 3
LEFT : вырезает с начала строки определенное количество символов. Первый параметр функции - строка, а второй - количество символов, которые надо вырезать сначала строки:
SELECT LEFT("Apple", 3) -- App
RIGHT : вырезает с конца строки определенное количество символов. Первый параметр функции - строка, а второй - количество символов, которые надо вырезать сначала строки:
SELECT RIGHT("Apple", 3) -- ple
SUBSTRING : вырезает из строки подстроку определенной длиной, начиная с определенного индекса. Певый параметр функции - строка, второй - начальный индекс для вырезки, и третий параметр - количество вырезаемых символов:
SELECT SUBSTRING("Galaxy S8 Plus", 8, 2) -- S8
REPLACE : заменяет одну подстроку другой в рамках строки. Первый параметр функции - строка, второй - подстрока, которую надо заменить, а третий - подстрока, на которую надо заменить:
SELECT REPLACE("Galaxy S8 Plus", "S8 Plus", "Note 8") -- Galaxy Note 8
REVERSE : переворачивает строку наоборот:
SELECT REVERSE("123456789") -- 987654321
CONCAT : объединяет две строки в одну. В качестве параметра принимает от 2-х и более строк, которые надо соединить:
SELECT CONCAT("Tom", " ", "Smith") -- Tom Smith
LOWER : переводит строку в нижний регистр:
SELECT LOWER("Apple") -- apple
UPPER : переводит строку в верхний регистр
SELECT UPPER("Apple") -- APPLE
SPACE : возвращает строку, которая содержит определенное количество пробелов
Например, возьмем таблицу:
CREATE TABLE Products (Id INT IDENTITY PRIMARY KEY, ProductName NVARCHAR(30) NOT NULL, Manufacturer NVARCHAR(20) NOT NULL, ProductCount INT DEFAULT 0, Price MONEY NOT NULL);
И при извлечении данных применим строковые функции:
SELECT UPPER(LEFT(Manufacturer,2)) AS Abbreviation, CONCAT(ProductName, " - ", Manufacturer) AS FullProdName FROM Products ORDER BY Abbreviation
Строковые функции Sql
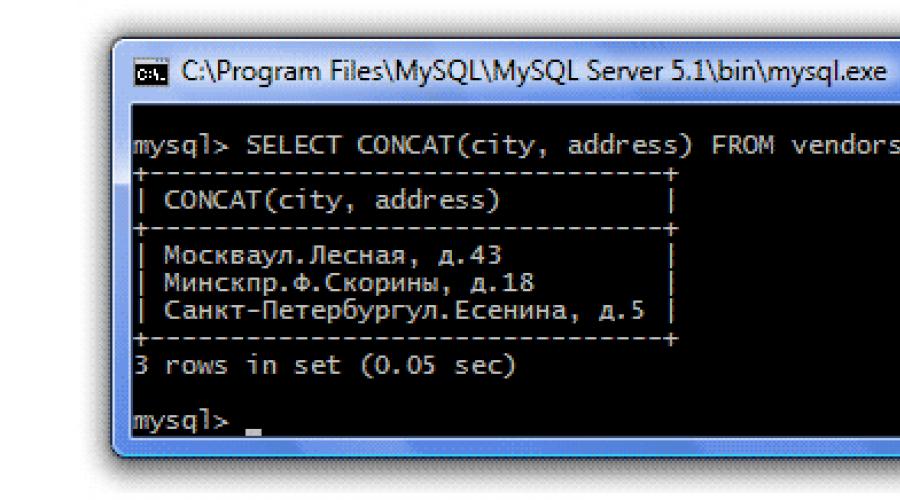
Эта группа функций позволяет манипулировать текстом. Строковых функций много, мы рассмотрим наиболее употребительные.- CONCAT(str1,str2...)
Возвращает строку, созданную путем объединения аргументов (аргументы указываются
в скобках - str1,str2...). Например, в нашей таблице Поставщики (vendors) есть столбец Город (city) и столбец Адрес (address).
Предположим, мы хотим, чтобы в результирующей таблице Адрес и Город указывались в одном столбце, т.е. мы хотим
объединить данные из двух столбцов в один. Для этого мы будем использовать строковую функцию CONCAT(), а в качестве
аргументов укажем названия объединяемых столбцов - city и address:
SELECT CONCAT(city, address) FROM vendors;

Обратите внимание, объединение произошло без разделения, что не очень читабельно. Давайте подправим наш запрос, чтобы между объединяемыми столбцами был пробел:
SELECT CONCAT(city, " ", address) FROM vendors;

Как видите, пробел считается тоже аргументом и указывается через запятую. Если объединяемых столбцов было бы больше, то указывать каждый раз пробелы было бы нерационально. В этом случае можно было бы использовать строковую функцию CONCAT_WS(разделитель, str1,str2...) , которая помещает разделитель между объединяемыми строками (разделитель указывается, как первый аргумент). Наш запрос тогда будет выглядеть так:
SELECT CONCAT_WS(" ", city, address) FROM vendors;
Результат внешне не изменился, но если бы мы объединяли 3 или 4 столбца, то код значительно бы сократился.
- INSERT(str, pos, len, new_str)
Возвращает строку str, в которой подстрока, начинающаяся
с позиции pos и имеющая длину len символов, заменена подстрокой new_str. Предположим, мы решили в столбце Адрес (address)
не отображать первые 3 символа (сокращения ул., пр., и т.д.), тогда мы заменим их на пробелы:
SELECT INSERT(address, 1, 3, " ") FROM vendors;

То есть три символа, начиная с первого, заменены тремя пробелами.
- LPAD(str, len, dop_str)
Возвращает строку str, дополненную слева строкой dop_str до длины len.
Предположим, мы хотим, чтобы при выводе городов поставщиков они располагались бы справа, а пустое пространство заполнялось бы
точками:
SELECT LPAD(city, 15, ".") FROM vendors;

- RPAD(str, len, dop_str)
Возвращает строку str, дополненную справа строкой dop_str до длины len.
Предположим, мы хотим, чтобы при выводе городов поставщиков они располагались бы слева, а пустое пространство заполнялось бы
точками:
SELECT RPAD(city, 15, ".") FROM vendors;

Обратите внимание, значение len ограничивает количество выводимых символов, т.е. если название города будет длиннее 15 символов, то оно будет обрезано.
- LTRIM(str)
Возвращает строку str, в которой удалены все начальные пробелы. Эта строковая
функция удобна для корректного отображения информации в случаях, когда при вводе данных допускаются случайные пробелы:
SELECT LTRIM(city) FROM vendors;
- RTRIM(str)
Возвращает строку str, в которой удалены все конечные пробелы:
SELECT RTRIM(city) FROM vendors;
В нашем случае лишних пробелов не было, поэтому и результат внешне мы не увидим.
- TRIM(str)
Возвращает строку str, в которой удалены все начальные и конечные пробелы:
SELECT TRIM(city) FROM vendors;
- LOWER(str)
Возвращает строку str, в которой все символы переведены в нижний регистр.
С русскими буквами работает некорректно, поэтому лучше не применять. Например, давайте
применим эту функцию к столбцу city:
SELECT city, LOWER(city) FROM vendors;
 Видите, какая абракадабра получилась. А вот с латиницей все в порядке:
Видите, какая абракадабра получилась. А вот с латиницей все в порядке:
SELECT LOWER("CITY");

- UPPER(str)
Возвращает строку str, в которой все символы переведены в верхний регистр.
С русскими буквами так же лучше не применять. А вот с латиницей все в порядке:
SELECT UPPER(email) FROM customers;

- LENGTH(str)
Возвращает длину строки str. Например, давайте узнаем сколько символов в наших
адресах поставщиков:
SELECT address, LENGTH(address) FROM vendors;

- LEFT(str, len)
Возвращает len левых символов строки str. Например, пусть в городах поставщиков
выводится только первые три символа:
SELECT name, LEFT(city, 3) FROM vendors;

- RIGHT(str, len)
Возвращает len правых символов строки str. Например, пусть в городах поставщиков
выводится только последние три символа:
SELECT LOAD_FILE("C:/proverka");
 Обратите внимание, необходимо указывать абсолютный путь к файлу .
Обратите внимание, необходимо указывать абсолютный путь к файлу .