Olap куб содержащий временные ряды курса рубля. Olap в узком смысле слова трактуется как: олап кубы
Читайте также
07.04.2011 Дерек Комингор
Если вам приходилось иметь дело с какой-либо областью, связанной с технологией, вы слышали, вероятно, термин «куб»; однако большинство обычных администраторов и разработчиков баз данных с этими объектами не работали. Кубы представляют собой действенную архитектуру данных для быстрого агрегирования многомерной информации. Если вашей организации требуется выполнить анализ больших объемов данных, то идеальным решением будет именно куб
Что такое куб?
Реляционные базы данных были спроектированы для осуществления тысяч параллельных транзакций, с сохранением производительности и целостности данных. По своей конструкции реляционные базы данных не дают эффективности в агрегировании и поиске при больших объемах данных. Чтобы агрегировать и возвратить большие объемы данных, реляционная база данных должна получить основанный на наборе запрос, информация для которого будет собрана и агрегирована «на лету». Такие реляционные запросы - очень затратные, поскольку опираются на множественные соединения и агрегатные функции; особенно малоэффективны агрегатные реляционные запросы при работе с большими массивами данных.
Кубы - это многомерные сущности, предназначенные для устранения указанного недостатка в реляционных базах данных. Применяя куб, вы можете предоставить пользователям структуру данных, которая обеспечивает быстрый отклик на запросы с большими объемами агрегации. Кубы выполняют это «волшебство агрегирования» путем предварительного агрегирования данных (измерений) по нескольким измерениям. Предварительная агрегация куба обычно осуществляется во время его обработки. При обработке куба вы порождаете вычисленные предварительно агрегаты данных, которые хранятся в бинарной форме на диске.
Куб - центральная конструкция данных в оперативной системе анализа данных OLAP аналитических служб SQL Server (SSAS). Кубы обычно строятся из основной реляционной базы данных, называемой моделью размерностей, но представляют собой отдельные технические сущности. Логически куб является складом данных, который составлен из размерностей (dimensions) и измерений (measures). Размерности содержат описательные признаки и иерархии, в то время как измерения - это факты, которые вы описываете в размерностях. Измерения объединены в логические сочетания, которые называются группами измерений. Вы привязываете размерности к группам измерений на основе признака - степени детализации.
В файловой системе куб реализован как последовательность связанных бинарных файлов. Бинарная архитектура куба облегчает быстрое извлечение больших объемов многомерных данных.
Я упомянул о том, что кубы построены из основной реляционной базы данных, называемой моделью размерностей. Модель размерностей содержит реляционные таблицы (факт и размерность), что связывает ее с сущностями куба. Таблицы фактов содержат измерения, такие как количество проданного продукта. Таблицы размерностей хранят описательные признаки, такие как названия продукта, даты и имена служащих. Как правило, таблицы фактов и таблицы размерностей связаны через ограничения первичного внешнего ключа, при том что внешние ключи находятся в таблице фактических данных (эта реляционная связь имеет отношение к признаку степени детализации куба, о котором говорилось выше). Когда таблицы размерности связаны непосредственно с таблицей фактов, формируется схема звезды. Когда таблицы размерности непосредственно не связаны с таблицей фактов, получается схема снежинки.
Обратите внимание, что модели размерностей классифицированы в зависимости от сферы применения. Витрина данных является моделью размерностей, которая предназначена для единичного бизнес-процесса, такого как продажи или управление запасами. Хранилище данных - модель размерностей, разработанная для того, чтобы охватить составные бизнес-процессы, так что она способствует перекрестной аналитике бизнес-процессов.
Требования к программному обеспечению
Теперь, когда у вас есть базовое понимание того, что такое кубы и почему они важны, я включу приборы и приглашу вас на пошаговый тур: построить свой первый куб, используя SSAS. Существуют некоторые основные компоненты программного обеспечения, которые вам понадобятся, поэтому, прежде чем приступать к строительству первого куба, убедитесь, что ваша система соответствует требованиям.
Мой пример куба «Продажи через Интернет» будет построен на основе тестовой базы данных AdventureWorksDW 2005. Я буду строить тестовый куб из подмножества таблиц, найденных в тестовой базе данных, которые будут полезны для анализа данных о сбыте через Интернет. На рисунке 1 представлена основная схема таблиц базы данных. Поскольку я использую версию 2005, вы можете следовать моим указаниям, применяя либо SQL Server 2005, либо SQL Server 2008.
| Рисунок 1. Подмножество витрины данных Adventure Works Internet Sales |
Учебную базу данных Adventure WorksDW 2005 можно найти на сайте CodePlex: msftdbprodsamples.codeplex.com. Найдите ссылку «SQL Server 2005 product sample databases are still available» (http://codeplex.com/MSFTDBProdSamples/Release/ProjectReleases.aspx?ReleaseId=4004). Учебная база данных содержится в файле AdventureWorksBI.msi (http://msftdbprodsamples.codeplex.com/releases/view/4004#DownloadId=11755).
Как уже упоминалось, необходимо иметь доступ к экземпляру SQL Server 2008 или 2005, в том числе SSAS и к компонентам Business Intelligence Development Studio (BIDS). Я буду использовать SQL Server 2008, так что вы можете увидеть некоторые тонкие различия, если используете SQL Server 2005.
Создание проекта SSAS
Первое, что вы должны сделать, - это создать проект SSAS, используя BIDS. Найдите BIDS в меню Start и далее в меню Microsoft SQL Server 2008/2005 подпункт SQL Server Business Intelligence Development Studio. При нажатии на эту кнопку запустится BIDS c экраном заставки по умолчанию. Создайте новый проект SSAS, выбрав File, New, Project. Вы увидите диалоговое окно New Project (новый проект), которое показано на экране 1. Выберите папку проекта Analysis Services Project и задайте описание этому проекту «SQLMAG_MyFirstCube». Нажмите кнопку ОК.
Когда проект будет создан, щелкните по нему правой кнопкой мыши в Solution Explorer и выберите в контекстном меню пункт свойств Properties. Теперь выберите раздел Deployment в левой части диалогового окна SQLMAG_MyFirstCube: Property Pages и проверьте установки значений для параметров Target Server и Database settings, как показано на экране 2. Если вы работаете в распределенной среде SQL Server, вам необходимо уточнить значение свойства Target Server именем сервера, на который вы собираетесь производить развертывание. Щелкните OK, когда вас устроят установленные значения параметров развертывания для данного проекта SSAS.
Определение источника данных
Первый объект, который нужно создать, - это источник данных. Объект источника данных обеспечивает схему и данные, используемые при построении связанных с кубом и расположенных в его основании объектов. Чтобы создать объект источника данных в BIDS, задействуйте мастер источников данных Data Source Wizard.
Начните работу мастера источника данных щелчком правой кнопкой мыши по папке Data Source на панели Solution Explorer, с выбора пункта New Data Source. Вы обнаружите, что создание объектов SSAS в BIDS имеет характер разработки. Сначала мастер проводит вас через процесс создания объекта и общие настройки. А затем вы открываете полученный объект SSAS в проектировщике и детально подстраиваете его, если нужно. Как только вы проходите экран приглашения, определите новое соединение с данными, нажимая кнопку New. Выберите и создайте новое соединение на основе Native OLEDB\SQL Server Native Client 10, указывающее на желательный для вас сервер SQL Server, который владеет нужным экземпляром базы данных. Вы можете использовать либо аутентификацию Windows, либо SQL Server, в зависимости от настроек окружающей среды SQL Server. Нажмите кнопку Test Connection, чтобы удостовериться, что вы правильно определили соединение с базой данных, а затем кнопку OK.
Далее следует Impersonation Information (информация о настройке заимствования прав), которая, как и связь с данными, зависит от того, как устроена среда SQL Server. Заимствование прав - это контекст безопасности, на который полагается SSAS, обрабатывая свои объекты. Если вы управляете развертыванием на основном, единственном сервере (или ноутбуке), как, я полагаю, большинство читателей, вы можете просто выбрать вариант использования учетной записи службы Use the service account. Нажмите Next для завершения работы мастера источника данных и задайте AWDW2005 в качестве имени источника данных. Весьма удобно, что можно задействовать этот метод для целей тестирования, но в реальной производственной среде это не самая лучшая практика - использовать учетную запись службы. Лучше указать доменные учетные записи для заимствования прав подключения SSAS к источнику данных.
Представление источника данных
Для определенного вами источника данных на следующем шаге в процессе построения куба SSAS следует создать представление Data Source View (DSV). DSV обеспечивает возможность разделения схемы, которую ожидает ваш куб, от подобной схемы основной базы данных. В результате DSV можно использовать для того, чтобы расширить основную реляционную схему при построении куба. Некоторые из ключевых возможностей DSV для расширения схем источников данных включают именованные запросы, логические отношения между таблицами и именованные вычисляемые столбцы.
Пойдем дальше, щелкнем правой кнопкой мыши по папке DSV и выберем пункт New Data Source View, чтобы запустить мастер создания новых представлений DSV. В диалоговом окне, на шаге Select a Data Source, выберите соединение с реляционной базой данных и нажмите кнопку Next. Выберите таблицы FactInternetSales, DimProduct, DimTime, DimCustomer и щелкните кнопку с одиночной стрелкой направо, чтобы перенести эти таблицы в колонку Included. Наконец, кликните Next и завершите работу мастера, принимая имя по умолчанию и нажимая кнопку Finish.
На данном этапе у вас должно быть представление DSV, которое расположено под папкой Data Source Views в Solution Explorer. Выполните двойной щелчок по новому DSV, чтобы запустить конструктор DSV. Вы должны увидеть все четыре таблицы для данного DSV, как показано на рисунке 2.
Создание размерностей базы данных
Как я объяснил выше, размерности обеспечивают описательные признаки измерений и иерархий, которые используются для того, чтобы обеспечить агрегирование выше уровня деталей. Необходимо понять различие между размерностью базы данных и размерностью куба: размерности из базы данных предоставляют базовые объекты размерностей для нескольких размерностей куба, по которым его будут строить.
Размерности базы данных и куба обеспечивают изящное решение для концепции, известной как «ролевые размерности». Ролевые размерности применяются, когда вам необходимо использовать единственную размерность в кубе многократно. Дата - прекрасный пример в данном экземпляре куба: вы будете строить единственную размерность даты и ссылаться на нее один раз для каждой даты, для которой хотите анализировать продажи через Интернет. Календарная дата будет первой размерностью, которую вы создадите. Щелкните правой кнопкой мышки по папке Dimensions в Solution Explorer и выберите пункт New Dimension, чтобы запустить мастер размерностей Dimension Wizard. Выберите пункт Use an existing table и щелкните Next на шаге выбора метода создания Select Creation Method. На шаге определения источника информации Specify Source Information укажите таблицу DimTime в раскрывающемся списке Main table и нажмите кнопку Next. Теперь, на шаге выбора признака размерности Select Dimension Attributes, вам необходимо отобрать атрибуты размерности времени. Выберите каждый атрибут, как показано на экране 3.
Нажмите Next. На завершающем шаге введите Dim Date в поле Name и нажмите кнопку Finish для завершения работы мастера размерности. Теперь вы должны увидеть новую размерность даты Dim Date, расположенную под папкой Dimensions в Solution Explorer.
Затем используйте мастер размерности, чтобы создать размерности продукции и клиента. Выполните те же самые шаги для создания базовой размерности, что и прежде. Работая с мастером размерности, убедитесь, что вы выбираете все потенциальные признаки на шаге Select Dimension Attributes. Значения по умолчанию для других параметров настройки вполне подойдут для экземпляра тестового куба.
Создание куба продаж по Интернету
Теперь, подготовив размерности базы данных, вы можете приступить к строительству куба. В Solution Explorer щелкните правой кнопкой мыши на папке Cubes и выберите New Cube для запуска мастера создания кубов Cube Wizard. В окне Select Creation Method выберите вариант использования существующих таблиц Use existing tables. Выберите таблицу FactInternetSales для Measure Group на шаге выбора таблицы групп измерения Select Measure Group Tables. Удалите флажок рядом с измерениями Promotion Key, Currency Key, Sales Territory Key и Revision Number на шаге Select Measures и нажмите Next.
На экране Select Existing Dimensions убедитесь, что все существующие размерности базы данных выбраны, чтобы использовать их далее как размерности куба. Поскольку мне хотелось бы сделать данный куб настолько простым, насколько это возможно, отмените выбор размерности FactInternetSales на шаге Select New Dimensions. Оставляя размерность FactInternetSales выбранной, вы создали бы то, что называется размерностью факта или вырожденной размерностью. Размерности факта - это размерности, которые были созданы с использованием основной таблицы фактов в противоположность традиционной таблице размерностей.
Нажмите кнопку Next, чтобы перейти к шагу Completing the Wizard, и введите «Мой первый куб» в поле имени куба. Нажмите кнопку Finish, чтобы завершить процесс работы мастера создания куба.
Развертывание и обработка куба
Теперь все готово к развертыванию и обработке первого куба. Щелкните правой кнопкой мыши по значку нового куба в Solution Explorer и выберите пункт Process. Вы увидите окно с сообщением о том, что содержание представляется устаревшим. Щелкните Yes для развертывания нового куба на целевом сервере SSAS. При развертывании куба вы посылаете файл XML for Analisis (XMLA) на целевой сервер SSAS, который создает куб на самом сервере. Как уже упоминалось, обработка куба заполняет его двоичные файлы на диске данными из основного источника, а также дополнительными метаданными, которые вы добавили (размерности, измерения и настройки куба).
Как только процесс развертывания будет завершен, появляется новое диалоговое окно Process Cube. Нажмите кнопку Run, чтобы начать процесс обработки куба, который открывается окном Process Progress. При завершении обработки нажмите кнопку Close (два раза, чтобы закрыть оба диалоговых окна) для завершения процессов развертывания и обработки куба.
Теперь вы построили, развернули и обработали свой первый куб. Вы можете просматривать этот новый куб, щелкая по нему правой кнопкой мыши в окне Solution Explorer и выбирая пункт Browse. Перетащите измерения в центр сводной таблицы, а атрибуты размерностей на строки и столбцы, чтобы исследовать свой новый куб. Обратите внимание, как быстро куб отрабатывает различные запросы с агрегированием. Теперь вы можете оценить неограниченную мощь и, значит, ценность для бизнеса, куба OLAP.
Дерек Комингор ([email protected]) - старший архитектор в компании B. I. Voyage, имеющей статус Microsoft Partner в области бизнес-аналитики. Имеет звание SQL Server MVP и несколько сертификатов Microsoft
В предыдущей статье данного цикла (см. № 2’2005) мы рассказали об основных новшествах аналитических служб SQL Server 2005. Сегодня мы подробнее рассмотрим средства создания OLAP-решений, входящие в этот продукт.
Коротко об основах OLAP
режде чем начать разговор о средствах создания OLAP-решений, напомним, что OLAP (On-Line Analytical Processing) это технология комплексного многомерного анализа данных, концепция которой была описана в 1993 году Э.Ф.Коддом, знаменитым автором реляционной модели данных. В настоящее время поддержка OLAP реализована во многих СУБД и иных инструментах.
OLAP-кубы
Что представляют собой OLAP-данные? В качестве ответа на этот вопрос рассмотрим простейший пример. Предположим, в корпоративной базе данных некоего предприятия имеется набор таблиц, содержащих сведения о продажах товаров или услуг, и на их основе создано представление Invoices с полями Country (страна), City (город), CustomerName (название компании-клиента), Salesperson (менеджер по продажам), OrderDate (дата размещения заказа), CategoryName (категория товара), ProductName (наименование товара), ShipperName (компания-перевозчик), ExtendedPrice (оплата за товар), при этом последнее из перечисленных полей, собственно, и является объектом анализа.
Выбор данных из такого представления можно осуществить с помощью следующего запроса:
SELECT Country, City, CustomerName, Salesperson,
OrderDate, CategoryName, ProductName, ShipperName, ExtendedPrice
FROM Invoices
Предположим, нас интересует, какова суммарная стоимость заказов, сделанных клиентами из разных стран. Для получения ответа на этот вопрос необходимо сделать следующий запрос:
SELECT Country, SUM (ExtendedPrice) FROM Invoices
GROUP BY Country
Результатом этого запроса будет одномерный набор агрегатных данных (в данном случае сумм):
| Country | SUM (ExtendedPrice) |
| Argentina | 7327.3 |
| Austria | 110788.4 |
| Belgium | 28491.65 |
| Brazil | 97407.74 |
| Canada | 46190.1 |
| Denmark | 28392.32 |
| Finland | 15296.35 |
| France | 69185.48 |
| 209373.6 | |
| ... |
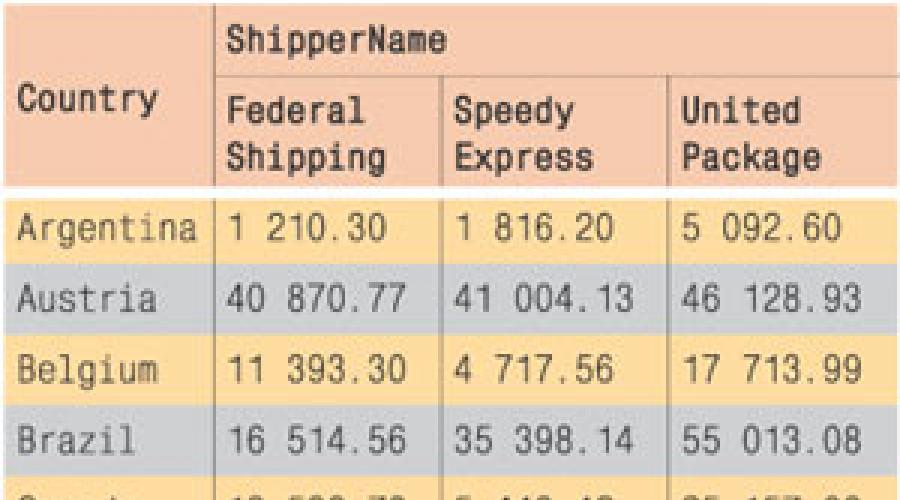
Если же мы хотим узнать, какова суммарная стоимость заказов, сделанных клиентами из разных стран и доставленных различными службами доставки, мы должны выполнить запрос, содержащий два параметра в предложении GROUP BY:
SELECT Country, ShipperName, SUM (ExtendedPrice) FROM Invoices
GROUP BY COUNTRY, ShipperName
Исходя из результатов этого запроса можно создать таблицу следующего вида:

Такой набор данных называется сводной таблицей (pivot table).
SELECT Country, ShipperName, SalesPerson SUM (ExtendedPrice) FROM Invoices
GROUP BY COUNTRY, ShipperName, Year
На основании результатов этого запроса можно построить трехмерный куб (рис. 1).

Добавляя дополнительные параметры для анализа, можно создать куб с теоретически любым числом измерений, при этом наряду с суммами в ячейках OLAP-куба могут содержаться результаты вычисления иных агрегатных функций (например, средние, максимальные, минимальные значения, количество записей исходного представления, соответствующее данному набору параметров). Поля, на основании которых вычисляются результаты, называются мерами куба.
Иерархии в измерениях
Предположим, нас интересует не только суммарная стоимость заказов, сделанных клиентами в разных странах, но и суммарная стоимость заказов, сделанных клиентами в разных городах одной страны. В этом случае можно воспользоваться тем, что значения, наносимые на оси, имеют различные уровни детализации это описывается в рамках концепции иерархии изменений. Скажем, на первом уровне иерархии располагаются страны, на втором города. Отметим, что начиная с SQL Server 2000 аналитические службы поддерживают так называемые несбалансированные иерархии, содержащие, например, такие члены, «дети» которых содержатся не на соседних уровнях иерархии или отсутствуют для некоторых членов изменения. Типичный пример подобной иерархии учет того факта, что в разных странах могут существовать, либо отсутствовать такие административно-территориальные единицы, как штат или область, размещающиеся в географической иерархии между странами и городами (рис. 2).

Отметим, что в последнее время принято выделять типичные иерархии, например содержащие географические или временные данные, а также поддерживать существование нескольких иерархий в одном измерении (в частности, для календарного и финансового года).
Создание OLAP-кубов в SQL Server 2005
SQL Server 2005 кубы создаются с помощью SQL Server Business Intelligence Development Studio. Этот инструмент представляет собой специальную версию Visual Studio 2005, предназначенную для решения данного класса задач (а при наличии уже установленной среды разработки список шаблонов проектов пополняется проектами, предназначенными для создания решений на основе SQL Sever и его аналитических служб). В частности, для создания решений на основе аналитических служб предназначен шаблон Analysis Services Project (рис. 3).

Для создания OLAP-куба в первую очередь следует решить, на основе каких данных его формировать. Наиболее часто OLAP-кубы строятся на основе реляционных хранилищ данных со схемами «звезда» или «снежинка» (о них мы рассказывали в предыдущей части статьи). В комплекте поставки SQL имеется пример такого хранилища база данных AdventureWorksDW, для использования которой в качестве источника следует найти в Solution Explorer папку Data Sources, выбрать пункт контекстного меню New Data Source и последовательно ответить на вопросы соответствующего мастера (рис. 4).

Затем рекомендуется создать Data Source View представление, на основе которого будет создаваться куб. Для этого необходимо выбрать соответствующий пункт контекстного меню папки Data Source Views и последовательно ответить на вопросы мастера. Результатом указанных действий станет схема данных, с помощью которых будет построено представление источников данных, при этом в полученной схеме вместо исходных можно указать «дружественные» имена таблиц (рис. 5).




Описанный таким образом куб можно перенести на сервер аналитических служб, выбрав из контекстного меню проекта опцию Deploy, и осуществить просмотр его данных (рис. 7).

При создании кубов в настоящее время используются многие особенности новой версии SQL Server, такие, например, как представление источников данных. Описание исходных данных для построения куба, равно как и описание структуры куба, теперь производится с помощью знакомого многим разработчикам инструмента Visual Studio, что является немалым достоинством новой версии этого продукта изучение разработчиками аналитических решений нового инструментария в этом случае сведено к минимуму.
Отметим, что в созданном кубе можно менять состав мер, удалять и добавлять атрибуты измерений и добавлять вычисляемые атрибуты членов измерений на основе имеющихся атрибутов (рис. 8).

Рис. 8. Добавление вычисляемого атрибута
Кроме того, в кубах SQL Server 2005 можно осуществлять автоматическую группировку или сортировку членов измерения по значению атрибута, определять связи между атрибутами, реализовывать связи «многие ко многим», определять ключевые показатели бизнеса, а также решать многие другие задачи (подробности о том, как выполняются все эти действия, можно найти в разделе SQL Server Analysis Services Tutorial справочной системы данного продукта).
В последующих частях данной публикации мы продолжим знакомство с аналитическими службами SQL Server 2005 и выясним, что нового появилось в области поддержки Data Mining.
Данных, как правило, разрежённый и долговременно хранимый. Может быть реализован на основе универсальных реляционных СУБД или специализированным программным обеспечением (см. также OLAP). В программных продуктах компании SAP используется термин «инфокуб».
Индексам массива соответствуют измерения (dimensions) или оси куба, а значениям элементов массива - меры (measures) куба.
w : (x ,y ,z ) → w xyz ,где x , y , z - измерения, w - мера.
В отличие от обычного массива в языке программирования, доступ к элементам- OLAP-куба может осуществляться как по полному набору индексов-измерений, так и по их подмножеству, и тогда результатом будет не один элемент, а их множество.
W : (x ,y ) → W = {w z1 , w z2 , …, w zn }Также известно описание OLAP-куба с использованием терминологии реляционной алгебры, как проекции отношений .
См. также
Wikimedia Foundation . 2010 .
- Схема звезды
- Наш дом - Россия (фракция)
Смотреть что такое "OLAP-куб" в других словарях:
OLAP куб - … Википедия
OLAP - (англ. online analytical processing, аналитическая обработка в реальном времени) технология обработки данных, заключающаяся в подготовке суммарной (агрегированной) информации на основе больших массивов данных, структурированных по… … Википедия
Куб (значения) - Куб многозначный термин: В математике В стереометрии куб шестигранный правильный многогранник В алгебре третья степень числа Фильм Серия фантастических фильмов: «Куб» «Куб 2: Гиперкуб» «Куб Ноль» Сленг и жаргон медицинское… … Википедия
Куб - У этого термина существуют и другие значения, см. Куб (значения). Куб Тип Правильный многогранник Грань квадрат … Википедия
Mondrian - OLAP Server Тип OLAP сервер Разработчик Pentaho Операционная система кроссплатформенное программное обеспечение Последняя версия 3.4.1 (2012 05 07) Лицензия свободное программное обеспечение … Википедия - Информационно аналитическая система автоматизированная система позволяющая экспертам быстро анализировать большие объемы данных, как правило является одним из элементов ситуационных центров. Так же, иногда в состав ИАС включают систему сбора… … Википедия
В рамках данной работы будут рассмотрены следующие вопросы:
- Что представляют собой OLAP-кубы?
- Что такое меры, измерения, иерархии?
- Какие виды операций можно выполнять над OLAP-кубами?
Главный постулат OLAP - многомерность в представлении данных. В терминологии OLAP для описания многомерного дискретного пространства данных используется понятие куба, или гиперкуба.
Куб представляет собой многомерную структуру данных, из которой пользователь-аналитик может запрашивать информацию. Кубы создаются из фактов и измерений.
Факты - это данные об объектах и событиях в компании, которые будут подлежать анализу. Факты одного типа образуют меры (measures). Мера есть тип значения в ячейке куба.
Измерения - это элементы данных, по которым производится анализ фактов. Коллекция таких элементов формирует атрибут измерения (например, дни недели могут образовать атрибут измерения "время"). В задачах бизнес-анализа коммерческих предприятий в качестве измерений часто выступают такие категории, как "время", "продажи", "товары", "клиенты", "сотрудники", "географическое местоположение". Измерения чаще всего являются иерархическими структурами, представляющими собой логические категории, по которым пользователь может анализировать фактические данные. Каждая иерархия может иметь один или несколько уровней. Так иерархия измерения "географическое местоположение" может включать уровни: "страна - область - город". В иерархии времени можно выделить, например, такую последовательность уровней: Измерение может иметь несколько иерархий (при этом каждая иерархия одного измерения должна иметь один и тот же ключевой атрибут таблицы измерений).
Куб может содержать фактические данные из одной или нескольких таблиц фактов и чаще всего содержит несколько измерений. Любой конкретный куб обычно имеет конкретный направленный предмет анализа.
На рисунке 1 показан пример куба, предназначенного для анализа продаж продуктов нефтепереработки некоторой компанией по регионам. Данный куб имеет три измерения (время, товар и регион) и одну меру (объем продаж, выраженный в денежном эквиваленте). Значения мер хранятся в соответствующих ячейках (cell) куба. Каждая ячейка уникально идентифицируется набором членов каждого из измерений, называемого кортежем. Например, ячейка, расположенная в нижнем левом углу куба (содержит значение $98399), задается кортежем [Июль 2005, Дальний Восток, Дизель]. Здесь значение $98399 показывают объем продаж (в денежном выражении) дизеля на Дальнем Востоке за июль 2005 года.
Стоит обратите также внимание на то, что некоторые ячейки не содержат никаких значений: эти ячейки пусты, потому что в таблице фактов не содержится данных для них.
Рис. 1. Куб с информацией о продажах нефтепродуктов в различных регионах
Конечной целью создания подобных кубов является минимизация времени обработки запросов, извлекающих требуемую информацию из фактических данных. Для реализации этой задачи кубы обычно содержат предварительно вычисленные итоговые данные, называемые агрегациями (aggregations). Т.е. куб охватывает пространство данных большее, чем фактическое - в нем существуют логические, вычисляемые точки. Вычислять значения точек в логическом пространстве на основе фактических значений позволяют функции агрегирования. Наиболее простыми функциями агрегирования являются SUM, MAX, MIN, COUNT. Так, например, используя функцию MAX, для приведенного в примере куба можно выявить, когда произошел пик продаж дизеля на Дальнем Востоке и т.д.
Еще одной специфической чертой многомерных кубов является сложность определения точки начала координат. Например, как задать точку 0 для измерения "Товар" или "Регионы"? Решением этой проблемы является внедрение специального атрибута, объединяющего все элементы измерения. Этот атрибут (создается автоматически) содержит всего один элемент - All ("Все"). Для простых функций агрегирования, например, суммы, элемент All эквивалентен сумме значений всех элементов фактического пространства данного измерения.
Важной концепцией многомерной модели данных является подпространство, или подкуб (sub cube). Подкуб представляет собой часть полного пространства куба в виде некоторой многомерной фигуры внутри куба. Так как многомерное пространство куба дискретно и ограничено, подкуб также дискретен и ограничен.
Операции над OLAP-кубами
Над OLAP-кубом могут выполняться следующие операции:
- срез;
- вращение;
- консолидация;
- детализация.

Рис. 2. Срез OLAP-куба
Вращение (рисунок 3) - операция изменения расположения измерений, представленных в отчете или на отображаемой странице. Например, операция вращения может заключаться в перестановке местами строк и столбцов таблицы. Кроме того, вращением куба данных является перемещение внетабличных измерений на место измерений, представленных на отображаемой странице, и наоборот.
/ В кубистической манере. Применение OLAP-кубов в практике управления крупных компаний
Вконтакте
Одноклассники
Константин Токмачев , системный архитектор
В кубистической манере.
Применение OLAP-кубов в практике управления крупных компаний
Возможно, уже прошло то время, когда вычислительные ресурсы корпорации тратились только на регистрацию информации и бухгалтерскую отчетность. При этом управленческие решения принимались «на глазок» в кабинетах, на совещаниях и заседаниях. Возможно, и в России пора вернуть корпоративным вычислительным комплексам их главный ресурс – решение задач управления на основе зарегистрированных в компьютере данных
О пользе бизнес-аналитики
В контуре управления корпорацией между «сырыми» данными и «рычагами» воздействия на управляемый объект располагаются «показатели работы» – KPI. Они образуют как бы «приборное табло», отражающее состояние различных подсистем управляемого объекта. Оснастить фирму информативными показателями работы и контролировать их расчет и полученные значения – труд бизнес-аналитика. Существенную помощь в организации аналитической работы корпорации способны оказать автоматизированные службы анализа, такие как утилита MS SQL Server Analysis Services (SSAS) и ее главный диспозитив – OLAP-куб.
Прямо здесь нужно сделать еще одно замечание. Скажем, в американской традиции специальность, ориентированная на работу с OLAP-кубами, называется BI (Business Intelligence) . Не должно быть никаких иллюзий, будто бы американское BI соответствует русскому «бизнес-аналитик». Без обид, но нередко наш бизнес-аналитик – это «недобухгалтер» и «недопрограммист», специалист с нечеткими знаниями и с небольшим окладом, реально не обладающий никаким собственным инструментарием и методологией.
Специалист же BI – это, по сути, прикладной математик, высококлассный специалист, ставящий на вооружение фирмы современные математические методы (то, что называлось Operations Researh – методы исследования операций). BI больше соответствует бывшей когда-то в СССР специальности «системный аналитик», выпускавшейся факультетом ВМК МГУ им. М.В. Ломоносова. OLAP-куб и службы анализа могут стать перспективной основой рабочего места русского бизнес-аналитика, возможно, после некоторого повышения его квалификации в сторону американского BI.
В последнее время возникла еще одна вредная тенденция. Благодаря специализации утрачено взаимопонимание между разными категориями работников корпорации. Бухгалтер, менеджер и программист, как «лебедь, рак да щука» в басне И.А. Крылова, тянут корпорацию в разные стороны.
Бухгалтер занят отчетностью, его суммы и по смыслу и по динамике не имеют прямого отношения к бизнес-процессу фирмы.
Менеджер занят своим отрезком бизнес-процесса, но не способен оценить глобально, на уровне фирмы в целом, итоги и перспективы своих действий.
Наконец, программист, бывший когда-то (благодаря образованию) проводником передовых технических идей из сферы науки в сферы бизнеса, превратился в пассивного исполнителя фантазий бухгалтера и менеджера, так что уже не редкость, когда ИТ-отделами корпораций подруливают бухгалтеры и вообще все, кому не лень. Безынициативный, малограмотный, но относительно высокооплачиваемый программист 1С – настоящий бич российских корпораций. (Почти как отечественный футболист.) О так называемых «экономистов и юристов» я уже не говорю, о них давно все сказано.
Так вот, позиция бизнес-аналитика, оснащенного наукоемким аппаратом SSAS, владеющего азами программирования и бухучета, способна консолидировать работу фирмы в отношении анализа и прогноза бизнес-процесса.
Преимущества OLAP-кубов
OLAP-куб – это современное средство анализа базы данных корпоративной вычислительной системы, позволяющее обеспечить сотрудников всех уровней иерархии требуемым набором показателей, которые характеризуют производственный процесс фирмы. Дело не только в том, что удобный интерфейс и гибкий язык запросов к кубу MDX (MultiDimensional eXpressions) позволяют сформулировать и вычислить необходимые аналитические показатели, но в замечательной скорости и легкости, с которой это делает OLAP-куб. Причем эти скорость и легкость, в известных пределах, не зависят от сложности расчетов и объема базы данных.
Некоторое представление об OLAP-
кубе может дать «сводная таблица» MS Excel. У этих объектов схожая логика и похожие интерфейсы. Но, как будет видно из статьи, функциональность OLAP несравненно богаче, а производительность несравненно выше, так что «сводная таблица» остается локальным настольным продуктом, тогда как OLAP – продукт корпоративного уровня.
Почему OLAP-куб так хорошо подходит для решения аналитических задач? OLAP-куб устроен так, что все показатели во всех возможных разрезах заранее вычислены (полностью или частично), и пользователю остается только «вытянуть» мышью требуемые показатели (измерения measures) и разрезы (размерности dimensions), а программе – перерисовать таблички.
Все возможные аналитики во всех разрезах образуют одно огромное поле, вернее, не поле, а как раз многомерный OLAP-куб. С каким бы запросом пользователь (менеджер, бизнес-аналитик, руководитель) ни обратился к службе аналитики, скорость ответа объясняется двумя вещами: во-первых, требуемая аналитика может быть легко сформулирована (либо выбрана из списка по имени, либо задана формулой на языке MDX), во-вторых, как правило, она уже вычислена.
Формулировка аналитики возможна в трех вариантах: это либо поле базы данных (вернее, поле warehouse), либо расчетное поле calculation, определяемое на уровне дизайна куба, либо выражение языка MDX при интерактивной работе с кубом.
Это означает сразу несколько привлекательных особенностей OLAP-кубов. По сути, исчезает барьер между пользователем и данными. Барьер в виде прикладного программиста, которому, во-первых, нужно объяснить проблему (поставить задачу). Во-вторых, придется подождать, пока прикладной программист создаст алгоритм, напишет и отладит программу, потом ее, возможно, будет модифицировать. Если сотрудников много и их требования разнообразны и изменчивы, то нужна целая команда прикладных программистов. В этом смысле OLAP-куб (и квалифицированный бизнес-аналитик) в плане аналитической работы заменяет целую команду прикладных программистов, подобно тому, как мощный экскаватор с экскаваторщиком при рытье канавы заменяет целую бригаду гастарбайтеров с лопатами!
При этом достигается еще одно весьма важное качество получаемых аналитических данных. Поскольку OLAP-куб – один на всю фирму, т.е. это одно и то же поле с аналитиками на всех, то исключается досадный разнобой в данных. Когда руководителю приходится задавать одну и ту же задачу нескольким независимым сотрудникам, чтобы исключить фактор субъективности, а они все равно приносят разные ответы, которые каждый берется как-то объяснить, и т.п. OLAP-куб обеспечивает единообразие аналитических данных на разных уровнях корпоративной иерархии, т.е. если руководитель захочет детализировать некий интересующий его показатель, то он непременно придет к данным более низкого уровня, с которыми работает его подчиненный, причем это будут как раз те данные, на основании которых рассчитан показатель более высокого уровня, а не какие-то еще данные, полученные каким-то другим путем, в какое-то другое время и т.п. То есть вся фирма видит одну и ту же аналитику, но на разных уровнях укрупнения.
Приведем пример. Допустим, руководитель контролирует дебиторскую задолженность. Пока KPI просроченной дебиторской задолженности «горит зеленым светом», значит, все в норме, никаких управленческих действий не требуется. Если цвет изменился на желтый или красный – что-то не так: разрезаем KPI по отделам продаж и сразу видим подразделения «в красном». Следующий разрез по менеджерам – и продавец, чьи клиенты просрочили платежи, определен. (Далее сумму просрочки можно разрезать по покупателям, по срокам и т.п.) Руководитель корпорации может прямо обратиться к нарушителям на любом уровне. Но вообще-то тот же KPI (на своих уровнях иерархии) видят и начальники отделов, и менеджеры по продажам. Поэтому, чтобы исправить ситуацию, им даже не нужно ждать «вызова на ковер»… Разумеется, сам KPI по смыслу не обязательно должен быть суммой просрочки – он может быть средневзвешенным сроком просрочки или вообще скоростью оборота дебиторской задолженности.
Отметим, что комплексность и гибкость языка MDX совместно с быстрым (порой, мгновенным) получением результата позволяет решать (с учетом этапов разработки и отладки) сложные задачи управления, которые в иных условиях, возможно, вообще не ставились бы из-за трудоемкости для прикладных программистов и исходной неопределенности в постановке. (Затянутые сроки решения прикладными программистами аналитических задач из-за плохо понятой постановки и долгие модификации программ при изменении условий часто встречаются на практике.)
Обратим внимание еще и на то, что каждый сотрудник фирмы может собрать с общего поля аналитик OLAP именно тот урожай, что ему требуется для работы, а не довольствоваться той «полоской», которая ему нарезана в коммунальных «стандартных отчетах».
Многопользовательский интерфейс работы с OLAP-кубом в режиме клиент-сервер позволяет каждому работнику независимо от других иметь свои (даже собственного изготовления при некотором навыке) блоки аналитики (отчеты), которые, будучи раз определены, автоматически обновляются – проще говоря, всегда находятся в актуальном состоянии.
То есть OLAP-куб позволяет сделать аналитическую работу (которой вообще-то занимаются не только записные аналитики, но, по сути, почти все сотрудники фирмы, даже логисты и менеджеры, контролирующие остатки и отгрузки) более избирательной, «с лица не общим выраженьем», что создает условия для совершенствования работы и повышения производительности труда.
Подводя итог нашему введению, отметим, что применение OLAP-кубов способно поднять управление фирмой на более высокий уровень. Единообразие аналитических данных на всех уровнях иерархии, их достоверность, комплексность, легкость создания и модификации показателей, индивидуальность настройки, высокая скорость обработки данных, наконец, экономия средств и времени, потраченных на поддержку альтернативных путей аналитики (прикладные программисты, самостоятельные расчеты работника), открывают перспективы применения OLAP-кубов в практике крупных российских компаний.
OLTP + OLAP: контур обратной связи в цепи управления фирмой
Теперь рассмотрим общую идею OLAP-кубов и их точку приложения в управленческой цепи корпорации. Термин OLAP (OnLine Analytical Processing) был введен британским математиком Едгаром Коддом в дополнение к им же ранее введенному термину OLTP (OnLine Transactions Processing). Об этом еще будет сказано, но Е. Кодд, разумеется, предложил не только термины, но и математические теории OLTP и OLAP. Не вдаваясь в детали, в современной интерпретации OLTP – это реляционная база данных, рассмотренная как механизм регистрации, хранения и выборки информации .
Методология решения
Такие ERP-системы (Enterprice Resource Planning), как 1С7, 1С8, MS Dynamics AX, имеют программные интерфейсы, ориентированные на пользователя (ввод и корректировка документов и т.п.), и реляционную базу данных (DB) для хранения и выборки информации, представленную сегодня программными продуктами типа MS SQL Server (SS).
Отметим, что информация, зарегистрированная в базе данных ERP-системы, и в самом деле представляет весьма ценный ресурс. Дело не только в том, что зарегистрированная информация обеспечивает текущий документооборот корпорации (выписку документов, их корректировку, возможность распечатки и сверки и т.п.) и не только в возможности расчета бухгалтерской отчетности (налоги, аудит и т.п.). С точки зрения управления намного важнее, что OLTP-система (реляционная база данных) – это, по сути, актуальная цифровая модель деятельности корпорации в натуральную величину.
Но, чтобы управлять процессом, недостаточно регистрировать информацию о нем. Процесс должен быть представлен в виде системы числовых показателей (KPI), характеризующих его ход. Кроме того, для показателей должны быть определены допустимые интервалы значений. И только если значение показателя выходит за пределы допустимого интервала, должно последовать управляющее воздействие.
Относительно подобной логики (или мифологии) управления («управление по отклонению») сходятся и древнегреческий философ Платон, создавший образ кормчего (киберноса), который налегает на весло, когда лодка отклоняется от курса, и американский математик Норберт Винер, создавший науку кибернетику в преддверии эры компьютеров.
Кроме привычной системы регистрации информации методом OLTP, нужна еще одна система – система анализа собранной информации. Эта надстройка, которая в контуре управления играет роль обратной связи между руководством и объектом управления, и есть система OLAP или, короче говоря, OLAP-куб.
В качестве программной реализации OLAP мы будем рассматривать утилиту MS Analysis Services, входящую в состав стандартной поставки MS SQL Server, сокращенно SSAS. Отметим, что по замыслу Е. Кодда OLAP-куб в аналитике должен дать ту же исчерпывающую свободу действий, которую система OLTP и реляционная база данных (SQL Server) дают в хранении и выборке информации.
Материально-техническое обеспечение OLAP
Теперь рассмотрим конкретную конфигурацию внешних устройств, прикладных программ и технологических операций, на которых основана автоматизированная работа OLAP-куба.
Будем считать, что корпорация использует ERP-систему, например, 1С7 или 1С8, в рамках которой в обычном порядке идет регистрация информации. База данных этой ERP-системы располагается на некоем сервере и поддерживается программой MS SQL Server.
Будем считать также, что на другом сервере установлено матобеспечение, включающее MS SQL Server с утилитой MS Analysis Services (SSAS), а также программы MS SQL Server Managment Studio, MS C#, MS Excel и MS Visual Studio. Эти программы в совокупности образуют требуемый контекст: инструментарий и необходимые интерфейсы разработчика OLAP-кубов.
На сервере SSAS установлена свободно распространяемая программа blat, вызываемая (с параметрами) из командной строки и обеспечивающая почтовый сервис.
На рабочих станциях сотрудников, в рамках локальной сети, среди прочего установлены программы MS Excel (версии не менее 2003), а также, возможно, специальный драйвер для обеспечения работы MS Excel с MS Analysis Services (если только соответствующий драйвер уже не включен в MS Excel).
Для определенности будем считать, что на рабочих станциях сотрудников установлена операционная система Windows XP, а на серверах – Windows Server 2008. Кроме того, пусть в качестве SQL Server используется MS SQL Server 2005, причем на сервере с OLAP-кубом установлены Enterprise Edition (EE) или Developer Edition (DE). В этих редакциях возможно использовать т.н. «полуаддитивные меры», т.е. дополнительные агрегатные функции (статистики), отличные от обычных сумм (например, экстремум или среднее значение).
Дизайн OLAP-куба (OLAP-кубизм)
Скажем несколько слов о дизайне самого OLAP-куба. На языке статистики OLAP-куб – это множество показателей работы, рассчитанных во всех необходимых разрезах, например, показатель отгрузки в разрезах по покупателям, по товарам, по датам и т.п. Из-за прямого перевода с английского в русской литературе по OLAP-кубам показатели называются «мерами», а разрезы – «размерностями». Это математически корректный, но синтаксически и семантически не очень удачный перевод. Русские слова «мера», «измерение», «размерность» почти не отличаются по смыслу и написанию, в то время как английские «measure» и «dimension» отличны и по написанию и по смыслу. Поэтому мы отдаем предпочтение аналогичным по смыслу традиционным русским статистическим терминам «показатель» и «разрез».
Существует несколько вариантов программной реализации OLAP-куба в отношении OLTP-системы, где идет регистрация данных. Мы рассмотрим только одну схему, самую простую, надежную и быструю.
В этой схеме OLAP и OLTP не имеют общих таблиц, и аналитики OLAP рассчитываются максимально детально на стадии обновления куба (Process), предшествующей стадии использования. Эта схема называется MOLAP (Multidimensional OLAP). Ее минусы – асинхронность с ERP и большие затраты памяти.
Хотя формально OLAP-куб можно построить с использованием в качестве источника данных всех (тысяч) таблиц реляционной базы данных ERP-системы и всех (сотен) их полей в качестве показателей или разрезов, реально этого делать не стоит. Наоборот. Для загрузки в куб правильнее подготовить отдельную базу данных, называемую «витрина» или «хранилище» (warehouse).
Несколько причин заставляют поступить именно так.
- Во-первых, привязка OLAP-куба к таблицам реальной базы данных наверняка создаст технические проблемы. Изменение данных в таблице может инициировать обновление куба, а обновление куба – не обязательно быстрый процесс, так что куб будет в состоянии перманентной перестройки; при этом еще процедура обновления куба может блокировать (при чтении) данные таблиц базы, тормозя работу пользователей по регистрации данных в ERP-системе.
- Во-вторых , наличие слишком большого количества показателей и разрезов резко увеличит область хранения куба на сервере. Не забудем, что в OLAP-кубе хранятся не только исходные данные, как в OLTP-системе, а еще и все показатели, просуммированные по всем возможным разрезам (и даже по всем сочетаниям всех разрезов). Кроме того, соответственно, замедлятся скорость обновления куба и в конце концов скорость построения и обновления аналитик и основанных на них пользовательских отчетов.
- В-третьих , слишком большое количество полей (показателей и разрезов) создаст проблемы в интерфейсе разработчика OLAP, т.к. списки элементов станут необозримы.
- В-четвертых, OLAP-куб весьма чувствителен к нарушениям целостности данных. Куб не может быть построен, если ключевые данные не находятся по ссылке, прописанной в структуре связей полей куба. Временное или постоянное нарушение целостности, незаполненные поля – обычное дело в базе данных ERP-системы, но это категорически не годится для OLAP.
Можно еще добавить, что ERP-систему и OLAP-куб следует располагать на разных серверах, чтобы разделить нагрузку. Но тогда при наличии общих таблиц для OLAP и OLTP возникает еще и проблема сетевого трафика. Практически неразрешимые -проблемы появляются в этом случае при необходимости консолидации в один OLAP-куб нескольких разнородных ERP-систем (1С7, 1С8, MS Dynamics AX).
Наверное, можно и дальше громоздить технические проблемы. Но самое главное, вспомним, что, в отличие от OLTP, OLAP – не средство регистрации и хранения данных, а средство аналитики. Это означает, что не нужно «на всякий случай» грузить и грузить «грязные» данные из ERP в OLAP. Наоборот, нужно сначала выработать концепцию управления фирмой, хотя бы на уровне системы KPI, и далее сконструировать прикладное хранилище данных (warehouse), расположенное на том же сервере, что и OLAP-куб, и содержащее небольшое рафинированное количество данных из ERP, необходимых для управления.
Не пропагандируя дурные привычки, OLAP-куб в отношении OLTP можно уподобить известному «перегонному кубу», посредством которого из «забродившей массы» реальной регистрации извлекается «чистый продукт».
Итак, мы получили, что источник данных для OLAP – это специальная база данных (warehouse), расположенная на том же сервере, что и OLAP. Вообще это означает две вещи. Во-первых, должны существовать особые процедуры, которые будут создавать warehouse из баз данных ERP. Во-вторых, OLAP-куб асинхронен со своими ERP-системами.
Учитывая сказанное выше, предлагаем следующий вариант архитектуры вычислительного процесса.
Архитектура решения
Пусть на разных серверах располагается множество ERP-систем некой корпорации (холдинга), аналитические данные по которым мы хотели бы консолидировано видеть в пределах одного OLAP-куба. Подчеркнем, что в описываемой технологии мы объединяем данные ERP-систем на уровне warehouse, оставляя неизменным дизайн OLAP-куба.
На сервере OLAP мы создаем образы (пустые копии) баз данных всех этих ERP-систем. На эти пустые копии мы периодически (еженощно) выполняем частичную репликацию баз данных соответствующих активно работающих ERP.
Далее запускаются SP (stored procedure), которые на том же сервере OLAP без сетевого трафика на основе частичных реплик баз данных ERP-систем создают (или пополняют) хранилище (warehouse) – источник данных OLAP-куба.
Потом запускается стандартная процедура обновления/построения куба по данным warehouse (операция Process в интерфейсе SSAS).
Прокомментируем отдельные моменты технологии. Какую работу выполняют SP?
В результате частичной репликации, в образе некоторой ERP-системы на сервере OLAP появляются актуальные данные. Кстати, частичная репликация может выполняться двумя способами.
Во-первых, из всех таблиц базы данных ERP-системы в ходе частичной репликации копируются лишь те, что нужны для построения warehouse. Это управляется фиксированным списком имен таблиц.
Во-вторых, частичность репликации может означать также, что копируются не все поля таблицы, а лишь те, что участвуют в построении warehouse. Список полей для копирования либо задается, либо динамически создается в SP по образу копии (если в копии таблицы исходно имеются не все поля).
Конечно, возможно не копировать строки таблиц целиком, но только добавлять новые записи. Однако это создает серьезные неудобства при учете редакций ERP «задним числом», что часто встречается в реально работающих системах. Так что проще, не мудрствуя лукаво, копировать все записи (или обновлять «хвост» начиная с некоторой даты).
Далее, главная задача SP – преобразовать данные ERP-систем к формату warehouse. Если имеется только одна ERP-система, то задача преобразования в основном сводится к выкопировке и, возможно, переформатированию нужных данных. Но если в одном и том же OLAP-кубе необходимо консолидировать несколько ERP-систем разной структуры, то преобразования усложняются.
Особенно сложной является задача консолидации в кубе нескольких различных ERP-систем, если множества их объектов (справочники товаров, контрагентов, складов и т.п.) частично пересекаются, объекты имеют один смысл, но естественно по-разному описаны в справочниках разных систем (в смысле кодов, идентификаторов, названий и т.п.).
Реально такая картина возникает в большом холдинге, когда несколько составляющих его автономных однотипных компаний осуществляют примерно одни и те же виды деятельности примерно на одной и той же территории, но используют собственные и не согласованные системы регистрации. В этом случае при консолидации данных на уровне warehouse не обойтись без вспомогательных таблиц мэппинга.
Уделим некоторое внимание архитектуре хранилища warehouse. Обычно схему OLAP-куба представляют в виде «звезды», т.е. как таблицу данных, окруженную «лучами» справочников – таблицами значений вторичных ключей. Таблица – это блок «показателей», справочники – это их разрезы. При этом справочник, в свою очередь, может быть произвольным несбалансированным деревом или сбалансированной иерархией, например, многоуровневой классификацией товаров или контрагентов. В OLAP-кубе числовые поля таблицы данных из warehouse автоматически становятся «показателями» (или измерениями measures), а посредством таблиц вторичных ключей могут быть определены разрезы (или размерности dimensions).
Это наглядное «педагогическое» описание. На самом деле архитектура OLAP-куба может быть значительно сложнее.
Во-первых, warehouse может состоять из нескольких «звездочек», возможно, связанных через общие справочники. В этом случае OLAP-куб будет объединением нескольких кубов (нескольких блоков данных).
Во-вторых, «луч» звездочки может быть не одним справочником, но целой (иерархической) файловой системой.
Во-третьих, на базе существующих разрезов dimension средствами интерфейса разработчика OLAP могут быть определены новые иерархические разрезы (скажем, с меньшим числом уровней, с другим порядком уровней и т.п.)
В-четвертых, на базе существующих показателей и разрезов при использовании выражения языка MDX могут быть определены новые показатели (calculations). Важно отметить, что новые кубы, новые показатели, новые разрезы автоматически полностью интегрированы с исходными элементами. Следует отметить также, что неудачно сформулированные показатели calculations и иерархические разрезы могут заметно затормозить работу OLAP-куба.
MS Excel как интерфейс с OLAP
Отдельный интерес представляет интерфейс пользователя с OLAP-кубами. Естественно наиболее полный интерфейс предоставляет сама утилита SSAS. Это и инструментарий разработчика OLAP-кубов, и интерактивный конструктор отчетов, и окно интерактивной работы с OLAP-кубом посредством запросов на языке MDX.
Кроме самого SSAS, существует много программ, обеспечивающих интерфейс с OLAP, в большей или меньшей степени охватывающих их функциональность. Но среди них есть одна, которая, на наш взгляд, имеет неоспоримые преимущества. Это MS Excel.
Интерфейс с MS Excel обеспечивает специальный драйвер, отдельно загружаемый или включенный в поставку Excel. Он не охватывает всей функциональности OLAP, но с ростом номеров версий MS Excel этот охват становится все шире (скажем, в MS Excel 2007 появляется графическое изображение KPI, чего не было в MS Excel 2003 и т.п.).
Разумеется, кроме достаточно полной функциональности, главное преимущество MS Excel – повсеместное распространение этой программы и тесное знакомство с ней подавляющего числа офисных пользователей. В этом смысле в отличие от других интерфейсных программ фирме ничего не нужно дополнительно приобретать и никого не нужно дополнительно обучать.
Большим преимуществом MS Excel как интерфейса с OLAP является возможность дальнейшей самостоятельной обработки данных, полученных в отчете OLAP (т.е. продолжение исследования данных, полученных из OLAP на других листах того же Excel, уже не средствами OLAP, но обычными средствами Excel).
Еженощный цикл обработки facubi
Теперь опишем ежедневный (еженощный) вычислительный цикл эксплуатации OLAP. Расчет ведется под контролем программы facubi, написанной на C# 2005 и запускаемой посредством Task Scheduler на сервере с warehouse и SSAS. В начале facubi обращается к интернету и считывает текущие курсы валют (используются для представления ряда показателей в валюте). Далее выполняются следующие действия.
Во-первых, facubi запускает SP, выполняющие частичную репликацию баз данных различных ERP-систем (элементов холдинга), доступных в локальной сети. Репликация выполняется, как мы говорили, на заранее подготовленные «подворья» – образы удаленных ERP-систем, расположенные на сервере SSAS.
Во-вторых, посредством SP выполняется отображение из реплик ERP на хранилище warehouse – особую DB, являющуюся источником данных OLAP-куба и расположенную на сервере SSAS. При этом решаются три главные задачи:
- данные ERP подводятся под требуемые форматы куба; речь идет и о таблицах, и о полях таблиц. (Иногда требуемую таблицу нужно «вылепить», скажем, из нескольких листов MS Excel.) Аналогичные данные могут иметь разный формат в разных ERP, например, ключевые поля ID в справочниках 1С7 имеют 36-значный символьный код длиной 8, а поля _idrref в справочниках 1С8 – шестнадцатеричные числа длиной 32;
- по ходу обработки ведется логический контроль данных (в том числе прописывание «умолчаний» default на месте пропущенных данных, где это возможно) и контроль целостности, т.е. проверка наличия первичных и вторичных ключей в соответствующих классификаторах;
- консолидация кодов объектов, имеющих один и тот же смысл в разных ERP. Например, соответствующие элементы справочников разных ERP могут иметь один и тот же смысл, скажем, это один и тот же контрагент. Задача консолидации кодов решается посредством построения таблиц мэппинга, где различные коды одних и тех же объектов приводятся к единству.
В-третьих, facubi запускает стандартную процедуру обновления данных куба Process (из состава процедур утилиты SSAS).
Согласно контрольным спискам программа facubi рассылает почтовые сообщения о ходе выполнения этапов обработки.
Выполнив facubi, Task Scheduler запускает по очереди несколько файлов excel, в которых заранее созданы отчеты на базе показателей OLAP-куба. Как мы говорили, MS Excel имеет специальный программный интерфейс (отдельно загружаемый или встроенный драйвер) для работы с OLAP-кубами (с SSAS). При запуске MS Excel включаются программы на MS VBA (типа макросов), которые обеспечивают обновление данных в отчетах; отчеты при необходимости модифицируются и рассылаются по почте (программа blat) пользователям согласно контрольным спискам.
Пользователи локальной сети, имеющие доступ к SSAS-серверу, получат «живые» отчеты, настроенные на OLAP-куб. (В принципе они сами, без всякой почты, могут обновлять OLAP-отчеты в MS Excel, лежащие на их локальных компьютерах.) Пользователи вне локальной сети либо получат оригинальные отчеты, но с ограниченной функциональностью, либо для них (после обновления OLAP-отчетов в MS Excel) будут вычислены особые «мертвые» отчеты, не обращающиеся к серверу SSAS.
Оценка результатов
Мы говорили выше об асинхронности OLTP и OLAP. В рассматриваемом варианте технологии цикл обновления OLAP-куба выполняется ночью (скажем, запускается в 1 час ночи). Это означает, что в текущем рабочем дне пользователи работают со вчерашними данными. Поскольку OLAP – это не средство регистрации (посмотреть последнюю редакцию документа), а средство управления (понять тенденцию процесса), такое отставание обычно не критично. Впрочем, при необходимости даже в описанном варианте архитектуры куба (MOLAP) обновление возможно проводить несколько раз в сутки.
Время выполнения процедур обновления зависит от особенностей конструкции OLAP-куба (большей или меньшей комплексности, более или менее удачных определений показателей и разрезов) и от объема баз данных внешних OLTP-систем. По опыту процедуры построения warehouse занимают от нескольких минут до двух часов, процедура обновления куба (Process) – от 1 до 20 минут. Речь идет о комплексных OLAP-кубах, объединяющих десятки структур типа «звездочка», о десятках общих «лучей» (справочников-разрезов) для них, о сотнях показателей. Оценивая объемы баз данных внешних ERP-систем по документам отгрузки, мы говорим о сотнях тысяч документов и, соответственно, миллионах товарных строк в год. Историческая глубина обработки, интересующая пользователя, составляла три – пять лет.
Описанная технология эксплуатируется в ряде крупных корпораций: с 2008 года в «Русской рыбной компании» (РРК) и компании «Русское море» (РМ), с 2012 года в компании «Санта-Бремор» (СБ). Часть корпораций является по преимуществу торгово-закупочными фирмами (РРК), другие – производственными (заводы по переработке рыбы и морепродуктов РМ и СБ). Все корпорации являются крупными холдингами, объединяющими по несколько фирм с независимыми и различными системами компьютерного учета – начиная от стандартных ERP-систем типа 1C7 и 1C8 и заканчивая «реликтовыми» учетными системами на базе DBF и Excel. Добавлю, что описанная технология эксплуатации OLAP-кубов (без учета этапа разработки) либо вообще не требует специальных сотрудников, либо входит в круг обязанностей одного штатного бизнес-аналитика. Задача годами крутится в автоматическом режиме, ежедневно снабжая различные категории сотрудников корпораций актуальной отчетностью.
Плюсы и минусы решения
Как показывает опыт, вариант предложенного решения достаточно надежен и прост в эксплуатации. Он легко модифицируется (подключение/отключение новых ERP, создание новых показателей и разрезов, создание и модификация Excel-отчетов и списков их почтовой рассылки) при инвариантности управляющей программы facubi.
MS Excel как интерфейс с OLAP обеспечивает достаточную выразительность и позволяет быстро приобщиться к OLAP-технологии разным категориям офисных сотрудников. Пользователь получает ежедневные «стандартные» OLAP-отчеты; используя интерфейс MS Excel с OLAP, может самостоятельно создавать OLAP-отчеты в MS Excel. Кроме того, пользователь может самостоятельно продолжить исследование информации OLAP-отчетов, используя обычные возможности своего MS Excel.
«Рафинированная» БД warehouse, в которой консолидировано (в ходе построения куба) несколько разнородных ERP-систем, даже без всякого OLAP позволяет решать (на сервере SSAS, методом запросов на языке Transact SQL или методом SP и др.) множество прикладных задач управления. Напомним, структура БД warehouse унифицирована и существенно проще (в плане количества таблиц и числа полей таблиц), чем структуры БД исходных ERP.
Особо отметим, что в предложенном нами решении имеется возможность консолидации в одном OLAP-кубе различных ERP-систем. Это позволяет получить аналитику по всему холдингу и сохранить многолетнюю преемственность в аналитике при переходе корпорации на другую учетную ERP-систему, скажем, при переходе от 1C7 к 1С8.
Мы использовали модель куба MOLAP. Плюсы этой модели – надежность в эксплуатации и высокая скорость обработки запросов пользователя. Минусы – асинхронность OLAP и OLTP, а также большие объемы памяти для хранения OLAP.
В заключение приведем еще один аргумент в пользу OLAP, который, возможно, был бы более уместным в Средние века. Поскольку его доказательная сила покоится на авторитете. Скромный, явно недооцененный британский математик Е. Кодд в конце 60-х годов разработал теорию реляционных БД. Сила этой теории была такова, что сейчас, по прошествии 50 лет, уже трудно найти базу данных не реляционного типа и язык запроса к БД, отличный от SQL.
Технология OLTP, основанная на теории реляционных БД, была первой идеей Е. Кодда. По сути, концепция OLAP-кубов – это вторая его идея, высказанная им в начале 90-х годов. Даже не будучи математиком, вполне можно ожидать, что вторая идея окажется столь же эффективной, как первая. То есть в плане компьютерной аналитики идеи OLAP скоро захватят мир и вытеснят все другие. Просто потому, что тема аналитики находит в OLAP свое исчерпывающее математическое решение, и это решение «адекватно» (термин Б. Спинозы) практической задаче аналитики. «Адекватно» же означает у Спинозы, что и сам Бог не придумал бы лучше…
- Ларсон Б. Разработка бизнес-аналитики в Microsoft SQL Server 2005. – СПб.: «Питер», 2008.
- Codd E. Relational Completeness of Data Base Sublanguages, Data Base Systems, Courant Computer Science Sumposia Series 1972, v. 6, Englwood cliffs, N.Y., Prentice – Hall.
Вконтакте