What is ansi? Why is garbage displayed instead of Russian letters in the console application.
Read also
Often in web programming and layout of html pages, you have to think about the encoding of the edited file - after all, if the encoding is selected incorrectly, then there is a chance that the browser will not be able to automatically determine it and as a result the user will see the so-called. "Krakozyabry".
Perhaps you yourself have seen on some sites instead of normal text incomprehensible characters and question marks. All this occurs when the encoding of the html page and the encoding of the file itself of this page do not match.
At all, what is text encoding? It's just a set of characters, in English "charset" (character set). She needs it in order to text information be converted into data bits and transmitted, for example, over the Internet.
Actually, the main parameters that distinguish encodings are the number of bytes and the set of special characters into which each character of the source text is converted.
Brief history of encodings:
One of the first to transmit digital information was the appearance of the ASCII encoding - American Standard Code for Information Interchange - American standard code table, adopted by the American National Standards Institute - American National Standards Institute (ANSI).
These abbreviations can be confusing. For practice, it is important to understand that the source encoding of the created text files may not support all the characters of some alphabets (for example, hieroglyphs), so there is a tendency to move to the so-called. standard Unicode (Unicode), which supports universal encodings − utf-8, utf-16, utf-32 and etc.
The most popular Unicode encoding is Utf-8. Usually, site pages are now typeset in it and various scripts are written. It allows you to easily display various hieroglyphs, Greek letters and other conceivable and inconceivable characters (character size up to 4 bytes). In particular, all WordPress and Joomla files are written in this encoding. And also some web technologies (in particular, AJAX) are only able to process utf-8 characters normally.

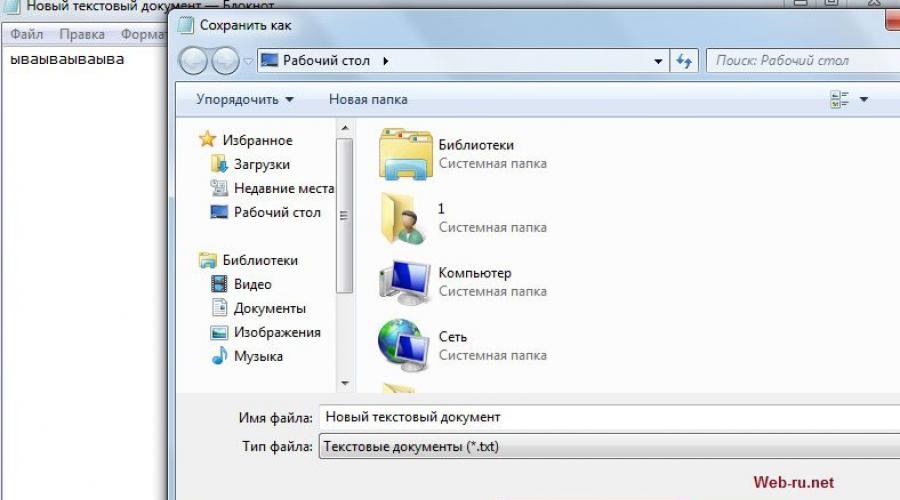
Setting encodings text file when creating it with regular notepad. Clickable
In Runet, you can still find sites written with the expectation of encoding Windows-1251 (or cp-1251). This is a special encoding designed specifically for Cyrillic.
ANSI-lumen (lm, lm), the unit is...
ANSI lumens is a unit of measure of illumination in multimedia projectors created by a lamp when it shines through a lens. "Lumen" in Latin means "light", ANSI stands for "American National Standards Institute". This is a standard for measuring luminous flux used to compare projectors.
This parameter was introduced in 1992 by the American National Standards Institute as a unit that characterizes the average luminous flux on a 40" control screen at the minimum focal length of a projector's zoom lens.
The measurement is carried out on a completely white picture (full white), the screen illumination is measured using a luxmeter in lux (Lux) at 9 control points of the screen. The value of the luminous flux is calculated as the average value of these 9 measurements - multiplied by its area and averaged.
The resulting light energy on the screen per square meter is indicated in lux and is found by the formula: lux = lumen / m². But lumens/lux measurement varies depending on the environment, fixture setup, and projected image, which is why ANSI lumens of usable luminous flux has become the standard today.
Such a measurement makes it possible to evaluate the uniformity of the distribution of the light flux over the screen surface. The reduction in brightness of an image at its edges is called a "Hot Spot" or light spot. The uniformity of the distribution of the light flux is calculated as the ratio of the smallest and largest of the received illumination measurements. In good projectors, this value does not fall below 70%.
This technique accurately describes the order in which measurements are taken. Under strictly defined conditions environment and the settings of the device, the image projected on the screen is divided into nine equal parts, and in each of them the light energy is determined. The average value obtained from all nine measurements and multiplied by the screen area in m² gives the ANSI lumen value.
Interestingly, luminous flux, unlike illumination (measured in ANSI lumens), does not depend on the projected area. In addition, manufacturer-specified ANSI lumens are often based on reference maximum settings that are rarely used in practice.
Also, often the ANSI lumens value is just an average, so it's hard to tell from it how well or poorly the projector distributes light across the screen surface.
ANSI lumens for digital projectors can range from 900 ANSI lumens for older models to 4700 ANSI lumens for today's high power fixtures. A good digital home theater projector should be around 2000 ANSI lumens.
Reg.ru: domains and hosting
The largest registrar and hosting provider in Russia.
Over 2 million domain names in service.
Promotion, mail for domain, solutions for business.
More than 700 thousand customers around the world have already made their choice.
*Mouseover to pause scrolling.
Back forward
Encodings: useful information and a brief retrospective
I decided to write this article as a small review on the issue of encodings.
We will understand what encoding is in general and touch a little on the history of how they appeared in principle.
We will talk about some of their features and also consider the points that allow us to work with encodings more consciously and avoid the so-called krakozyabrov, i.e. unreadable characters.
So let's go...
What is an encoding?
Simply put, encoding is a table of character mappings that we can see on the screen, to certain numeric codes.
Those. each character that we enter from the keyboard, or see on the monitor screen, is encoded certain sequence bits (zeros and ones). 8 bits, as you probably know, are equal to 1 byte of information, but more on that later.
The appearance of the characters themselves is determined by the font files that are installed on your computer. Therefore, the process of displaying text on the screen can be described as a constant mapping of sequences of zeros and ones to some specific characters that are part of the font.
The progenitor of all modern encodings can be considered ASCII.
This abbreviation stands for American Standard Code for Information Interchange(American standard encoding table for printable characters and some special codes).
This single byte encoding, which originally contained only 128 characters: letters of the Latin alphabet, Arabic numerals, etc.

Later it was expanded (initially it did not use all 8 bits), so it became possible to use not 128, but 256 (2 to 8) different characters that can be encoded in one byte of information.
This improvement made it possible to add to ASCII symbols of national languages, in addition to the already existing Latin alphabet.
There are a lot of options for extended ASCII encoding, due to the fact that there are also a lot of languages in the world. I think that many of you have heard of such an encoding as KOI8-R is also an extended ASCII encoding, designed to work with Russian characters.
The next step in the development of encodings can be considered the appearance of the so-called ANSI encodings.
Essentially they were the same extended versions of ASCII, however, various pseudo-graphic elements were removed from them and typographic symbols were added, for which there were not enough "free spaces" previously.
An example of such an ANSI encoding is the well-known Windows-1251. In addition to typographic symbols, this encoding also included letters of the alphabets of languages close to Russian (Ukrainian, Belarusian, Serbian, Macedonian and Bulgarian).
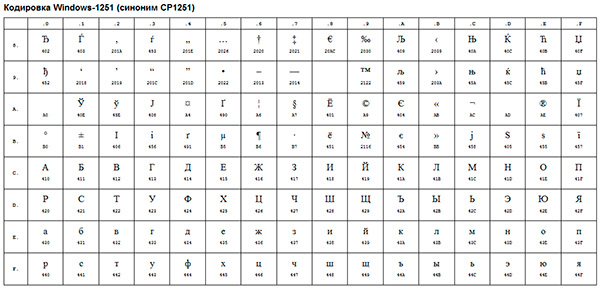
ANSI encoding is the collective name for. In fact, the actual encoding when using ANSI will be determined by what is specified in the registry of your operating system Windows. In the case of Russian, this will be Windows-1251, however, for other languages, it will be a different kind of ANSI.
As you understand, a bunch of encodings and the lack of a single standard did not bring to good, which was the reason for frequent meetings with the so-called krakozyabry- an unreadable meaningless set of characters.
The reason for their appearance is simple - it is attempt to display characters encoded with one encoding table using another encoding table.
In the context of web development, we may encounter bugs when, for example, Russian text is mistakenly saved in the wrong encoding that is used on the server.
Of course, this is not the only case when we can get unreadable text - there are a lot of options here, especially when you consider that there is also a database in which information is also stored in a certain encoding, there is a database connection mapping, etc.
The emergence of all these problems served as an incentive to create something new. It was supposed to be an encoding that could encode any language in the world (after all, with the help of single-byte encodings, with all the desire, it is impossible to describe all the characters, say, of the Chinese language, where there are clearly more than 256), any additional special characters and typography.
In a word, it was necessary to create a universal encoding that would solve the problem of bugs once and for all.
Unicode - universal text encoding (UTF-32, UTF-16 and UTF-8)
The standard itself was proposed in 1991 by a non-profit organization "Unicode Consortium"(Unicode Consortium, Unicode Inc.), and the first result of his work was the creation of an encoding UTF-32.
Incidentally, the abbreviation UTF stands for Unicode Transformation Format(Unicode Conversion Format).
In this encoding, to encode one character, it was supposed to use as many as 32 bits, i.e. 4 bytes of information. If we compare this number with single-byte encodings, then we will come to a simple conclusion: to encode 1 character in this universal encoding, you need 4 times more bits, which "weights" the file 4 times.
It is also obvious that the number of characters that could potentially be described using this encoding exceeds all reasonable limits and is technically limited to a number equal to 2 to the power of 32. It is clear that this was a clear overkill and wastefulness in terms of the weight of the files, so this encoding was not widely used.
It was replaced by a new development - UTF-16.
As the name implies, in this encoding one character is encoded no longer 32 bits, but only 16(i.e. 2 bytes). Obviously, this makes any character twice "lighter" than in UTF-32, but also twice as "heavier" than any character encoded using a single-byte encoding.
The number of characters available for encoding in UTF-16 is at least 2 to the power of 16, i.e. 65536 characters. Everything seems to be fine, besides, the final value of the code space in UTF-16 has been expanded to more than 1 million characters.
However, this encoding did not fully satisfy the needs of developers. Let's say if you write using exclusively Latin characters, then after switching from the extended version of the ASCII encoding to UTF-16, the weight of each file doubled.
As a result, another attempt was made to create something universal, and this something has become the well-known UTF-8 encoding.
UTF-8- This multibyte character encoding with variable character length. Looking at the name, you might think, by analogy with UTF-32 and UTF-16, that 8 bits are used to encode one character, but this is not so. More precisely, not quite so.
This is because UTF-8 provides the best compatibility with older systems that used 8-bit characters. To encode a single character in UTF-8 is actually used 1 to 4 bytes(hypothetically possible up to 6 bytes).
In UTF-8, all Latin characters are encoded with 8 bits, just like in ASCII encoding.. In other words, the basic part of the ASCII encoding (128 characters) has moved to UTF-8, which allows you to "spend" only 1 byte on their representation, while maintaining the universality of the encoding, for which everything was started.
So, if the first 128 characters are encoded with 1 byte, then all other characters are already encoded with 2 bytes or more. In particular, each Cyrillic character is encoded with exactly 2 bytes.
Thus, we got a universal encoding that allows us to cover all possible characters that need to be displayed without "heavier" files unnecessarily.
With BOM or without BOM?
If you have worked with text editors(by code editors), for example Notepad++, phpDesigner, rapid PHP etc., then they probably paid attention to the fact that when setting the encoding in which the page will be created, you can usually choose 3 options:
ANSI
-UTF-8
- UTF-8 without BOM



I must say right away that it is always worth choosing the last option - UTF-8 without BOM.
So what is BOM and why don't we need it?
BOM stands for Byte Order Mark. This is a special Unicode character used to indicate the byte order of a text file. According to the specification, its use is optional, but if BOM is used, it must be set at the beginning of the text file.
We will not go into the details of the work BOM. For us, the main conclusion is the following: using this service character together with UTF-8 prevents programs from reading the encoding normally, resulting in script errors.
ANSI is an institution for the standardization of industrial methods and technologies. It is a member of the International Organization for Standardization (ISO). In Germany, there is an analogue of such an organization - the German Standardization Institute (DIN), in Austria - the Austrian Standards Institute (ASI), in Switzerland - the Swiss Association of Standards (SNV).
Although ANSI codes are found in many industrial areas, the computer abbreviation "ANSI" refers to a specific group of characters based on ASCII. There is no true ANSI standard, however, ANSI projects have smoothly adopted the ISO 8859 standard.
ANSI tasks
The main task of the American National Standards Institute (ANSI) is the dissemination and implementation of US national standards around the world, at enterprises in all countries.
In addition, the work of this institute solves the problems of a global scale:
- environment protection,
- industrial safety,
- household safety.
It is known that in the United States, as in Russia, standards are regulated primarily by the state (although ANSI positions itself as a non-profit non-governmental organization), so the desire to fill this niche and bring all norms to the American denominator is a completely logical and consistent thought. Indeed, through standards it is possible to distribute not only purely technical innovations, but also to pursue the state foreign policy of globalization and world integration.
A large budget is spent on supporting the ANSI program by the state, which is spent mainly on optimization, updating and reorganization of production methods. In the steel industry, ANSI standards have long established themselves as some of the best in the world.
Our company is also willing in its work in the production of flange products, which are sold in huge quantities to industrial enterprises in Russia and the CIS countries.