Basic concepts of information coding theory. Coding theory
Coding. Basic concepts.
Various coding methods are widely used in practical activities man since time immemorial. For example, the decimal positional number system is a way of encoding natural numbers. Another way to encode natural numbers is Roman numerals, and this method is more visual and natural; indeed, a finger is I, a finger is V, two fingers are X. However, with this coding method it is more difficult to perform arithmetic operations over large numbers, so it was supplanted by a coding method based on the positional decimal number system. From this example we can conclude that various ways codings have specific features inherent only to them, which, depending on the purposes of coding, can be either an advantage of a particular coding method or its disadvantage.
Widely known methods for numerical coding of geometric objects and their position in space: Cartesian coordinates and polar coordinates. And these coding methods are distinguished by their specific features.
Until the 20th century, coding methods and tools played a supporting role, but with the advent of computers the situation changed radically. Coding finds widest application V information technology and is often a central issue when solving a variety of problems such as:
– presentation of data of arbitrary nature (numbers, text, graphics) in computer memory;
– optimal data transmission via communication channels;
– protection of information (messages) from unauthorized access;
– ensuring noise immunity when transmitting data over communication channels;
– information compression.
From the point of view of information theory, coding is the process of unambiguous comparison of the alphabet of the message source and a certain set of conventional symbols, carried out according to a certain rule, and a code (code alphabet) is a complete set (set) of different conventional symbols (code symbols) that can be used to encoding the original message and which are possible with this rule coding. The number of different code symbols that make up the code alphabet is called the volume of the code or the volume of the code alphabet. Obviously, the volume of the code alphabet cannot be less than the volume of the alphabet of the original message being encoded. Thus, encoding is the transformation of the original message into a set or sequence of code symbols representing the message transmitted over the communication channel.
Coding can be numeric (digital) and non-numeric, depending on the type in which the code symbols are presented: numbers in some number system or some other objects or signs, respectively.
In most cases, code symbols are a collection or sequence of certain simple components, for example, a sequence of digits in code symbols of a numeric code, which are called code symbol elements. The location or serial number of an element in a codeword is determined by its position.
The number of code symbol elements used to represent one character of the original message source alphabet is called the code value. If the meaning of the code is the same for all characters of the alphabet of the original message, then the code is called uniform, otherwise - uneven. The number of elements included in a code symbol is sometimes called the length of the code symbol.
From the point of view of redundancy, all codes can be divided into non-redundant codes and redundant ones. In redundant codes, the number of elements of code symbols can be reduced due to more efficient use of the remaining elements, but in non-redundant codes, reducing the number of elements in code symbols is impossible.
Coding problems in the absence of interference and in its presence are significantly different. Therefore, a distinction is made between effective (statistical) coding and corrective (noise-resistant) coding. With efficient coding, the goal is to achieve the representation of the alphabet symbols of the message source with a minimum number of elements of code symbols on average per one symbol of the message source alphabet by reducing code redundancy, which leads to an increase in the message transmission speed. And with corrective (noise-resistant) coding, the task is to reduce the probability of errors in the transmission of symbols of the original alphabet by detecting and correcting errors by introducing additional code redundancy.
A separate task of encoding is to protect messages from unauthorized access, distortion and destruction. With this type of encoding, messages are encoded in such a way that even after receiving them, an attacker would not be able to decode them. The process of this type of message encoding is called encryption (or scrambling), and the decoding process is called decryption (or decryption). The encoded message itself is called encrypted (or simply encryption), and the encoding method used is called a cipher.
Quite often, encoding methods are separated into a separate class, which allow you to construct (without loss of information) message codes that are shorter in length compared to the original message. Such encoding methods are called data compression or packaging methods. The quality of compression is determined by the compression ratio, which is usually measured as a percentage and which shows how many percent the encoded message is shorter than the original one.
When automatically processing information using a computer, numeric (digital) coding is usually used, which naturally raises the question of justifying the number system used. Indeed, when the base of the number system is reduced, the alphabet of elements of code symbols is simplified, but the code symbols are lengthened. On the other hand, the larger the base of the number system, the fewer number of bits is required to represent one code symbol, and, consequently, the less time for its transmission, but with the increase in the base of the number system, the requirements for communication channels and technical means recognition of elementary signals corresponding to various elements of code symbols. In particular, the code of a number written in the binary number system is on average approximately 3.5 times longer than the decimal code. Since in all information processing systems it is necessary to store large information arrays in the form of numerical information, one of the essential criteria for choosing an alphabet of elements of symbols of a numerical code (i.e., the base of the number system used) is to minimize the number electronic elements in storage devices, as well as their simplicity and reliability.
When determining the number of electronic elements required to fix each of the elements of the code symbols, it is necessary to proceed from the practically justified assumption that this requires a number of the simplest electronic elements (for example, transistors) equal to the base of the number system a. Then for storage in some device n code symbol elements will be required M electronic elements:
M = a·n. (2.1)
Largest quantity different numbers that can be written in this device N:
N = a n .
Taking logarithms of this expression and expressing from it n we get:
n= log N/ln a.
Transforming expression (2.1) to the form
M= a∙ ln N/ln a(2.2)
can be determined at what base of logarithms a amount of elements M will be minimal for a given N. Differentiating by a function M = f(a) and equating its derivative to zero, we get:
Obviously, for any finite a
ln N/ ln 2 a ≠ 0
and therefore
ln a- 1 = 0,
where a = e ≈ 2.7.
Since the base of the number system can only be an integer, then A choose equal to 2 or 3. For example, let's set the maximum capacity of the storage device N=10 6 numbers. Then, for different bases of number systems ( A)amount of elements ( M) in such a storage device there will be, in accordance with expression (2.2), the following (Table 2.1):
Table 2.1.
| A | ||||||
| M | 39,2 | 38,2 | 39,2 | 42,9 | 91,2 |
Consequently, if we proceed from minimizing the amount of equipment, then the most profitable will be the binary, ternary and quaternary number systems, which are close in this parameter. But since the technical implementation of devices operating in the binary number system is much simpler, codes based on the base 2 number system are most widely used in numeric coding.
To analyze various sources of information, as well as transmission channels, it is necessary to have a quantitative measure that would allow one to assess the amount of information contained in the message and carried by the signal. This measure was introduced in 1946 by the American scientist K. Shannon.
Next, we assume that the source of information is discrete, producing a sequence of elementary messages (i,), each of which is selected from a discrete ensemble (alphabet) a, a 2 ,...,th A; To is the volume of the alphabet of the information source.
Each elementary message contains certain information as a set of information (in the example under consideration) about the state of the information source in question. To quantify the measure of this information, its semantic content, as well as the degree of importance of this information for its recipient, is unimportant. Note that before receiving a message, the recipient always has uncertainty as to what kind of message I am. from among all possible ones will be transferred to him. This uncertainty is estimated using the prior probability P(i,) of transmitting the message i,. We conclude that an objective quantitative measure of information contained in an elementary message from a discrete source is established by the probability of selecting a given message and determines cc as a function of this probability. The same function characterizes the degree of uncertainty that the recipient of information has regarding the state of a discrete source. It can be concluded that the degree of uncertainty about the expected information determines the requirements for information transmission channels.
In general, the probability R(a,) The choice by the source of some elementary message I, (hereinafter we will call it a symbol) depends on the previously selected symbols, i.e. is a conditional probability and will not coincide with the prior probability of such a choice.
tim that ^ R(a):) = 1, since all I form a complete group of events
gy), and the selection of these symbols is carried out using some functional dependency J(a,)= P(a,) = 1, if the choice of symbol by the source is a priori determined, J(a,)= a„a P(a t ,a)- the probability of such a choice, then the amount of information contained in a pair of symbols is equal to the sum of the amount of information contained in each of the symbols I and I. This property of a quantitative measure of information is called additivity.
We believe that R(a,) is the conditional probability of choosing the symbol i, after all the symbols preceding it, and R(a,,i,) is the conditional probability of choosing the symbol i; after I, and all the previous ones, and, given that P(a 1,a 1) = P(a) P(i,|i y), the additivity condition can be written
Let us introduce the notation R(a) = P p P(ar) = Q and rewrite condition (5.1):
We believe that R, O* 0. Using expression (5.2), we determine the type of function (р (R). Having carried out differentiation, multiplication by R* 0 and designating RO = R, let's write down
Note that relation (5.3) is satisfied for any R f O u^^O. However, this requirement leads to constancy of the right and left sides (5.3): Pq>"(P)= Ar"(/?) - To - const. Then we arrive at the equation Rts>"(R) = TO and after integration we get
Let's take into account that we will rewrite
Consequently, when two conditions on the properties of J(a,) are met, it turns out that the type of functional dependence J(a,) on the probability of choosing a symbol a t accurate to a constant coefficient TO uniquely determined
Coefficient TO affects only the scale and determines the system of units for measuring the amount of information. Since 1n[P] F 0, then it makes sense to choose To ensure that the measure of the amount of information J(a) was positive.
Having accepted K=-1, write it down
It follows that the unit of information quantity is equal to the information that an event has occurred, the probability of which is equal to Me. Such a unit of information quantity is called a natural unit. It is more often believed that TO= -, then
Thus, we came to a binary unit of the amount of information, which contains a message about the occurrence of one of two equally probable events and is called a “bit”. This unit is widely used due to the use of binary codes in communication technology. Choosing the base of the logarithm in the general case, we obtain
where the logarithm can be with an arbitrary base.
The additivity property of a quantitative measure of information allows, based on expression (5.9), to determine the amount of information in a message consisting of a sequence of symbols. The probability of the source choosing such a sequence is taken taking into account all previously available messages.
A quantitative measure of information contained in an elementary message a (, does not give an idea of the average amount of information J(A), issued by the source when selecting one elementary message a d
The average amount of information characterizes the source of information as a whole and is one of the most important characteristics of communication systems.
Let us define this characteristic for a discrete source of independent messages with the alphabet TO. Let us denote by ON THE) the average amount of information per symbol and which is the mathematical expectation of the random variable A - the amount of information contained in a randomly selected symbol A
The average amount of information per symbol is called the entropy of the source of independent messages. Entropy is an indicator of the average a priori uncertainty when choosing the next symbol.
From expression (5.10) it follows that if one of the probabilities R(a) is equal to one (hence, all others are equal to zero), and the entropy of the information source will be equal to zero - the message is completely defined.
Entropy will be maximum if the prior probabilities of all possible symbols are equal TO, i.e. R(a) = 1 /TO, Then
If the source independently selects binary symbols with probabilities P, = P(a x) and P 2 = 1 - P, then the entropy per character will be
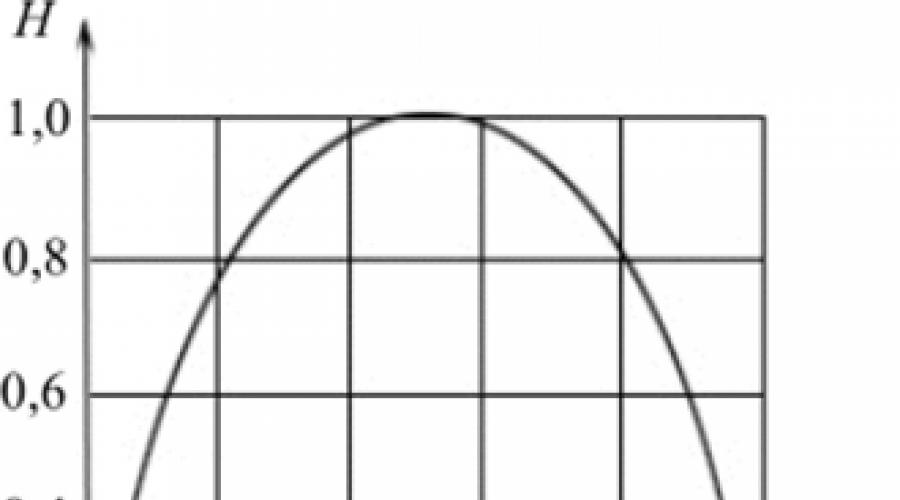
In Fig. Figure 16.1 shows the dependence of the entropy of a binary source on the a priori probability of choosing from two binary symbols; from this figure it is also clear that the entropy is maximum at R, = R 2 = 0,5
1 o 1 two - and in binary units log 2 2 = 1-

Rice. 5.1. Dependence of entropy at K = 2 from the probability of choosing one of them
Entropy of sources with equally probable choice of symbols, but with different sizes of alphabets TO, increases logarithmically with growth TO.
If the probability of choosing symbols is different, then the entropy of the source decreases I(A) relative to the possible maximum N(A) psh = log TO.
The greater the correlation between symbols, the less freedom of choice of subsequent symbols and the less information the newly selected symbol has. This is due to the fact that the uncertainty of the conditional distribution cannot exceed the entropy of their unconditional distribution. Let us denote the entropy of a source with memory and alphabet TO through N(AA"), and the entropy of the source without memory, but in the same alphabet - through ON THE) and prove the inequality
By entering the designation P(aa") for the conditional probability of choosing a symbol a,(/ = 1, 2, TO) provided that the symbol is previously selected ajij =1,2,TO) and omitting transformations, we write without proof

which proves inequality (5.13).
Equality in (5.13) or (5.14) is achieved in the case when
This means that the conditional probability of choosing a symbol is equal to the unconditional probability of choosing it, which can only be the case for sources without memory.
Interestingly, the entropy of text in Russian is 1.5 binary units per character. At the same time with the same alphabet K= 32 with the condition of independent and equally probable symbols N(A) tn = 5 binary ones per character. Thus, the presence internal connections decreased entropy by approximately 3.3 times.
An important characteristic of a discrete source is its redundancy p and:
The redundancy of the information source is a dimensionless quantity within the range . Naturally, in the absence of redundancy p u = 0.
To transmit a certain amount of information from a source that does not have correlations between symbols, with equal probability of all symbols, the minimum possible number of transmitted symbols is required /7 min: /r 0 (/7 0 R(L max)). To transmit the same amount of information from a source with entropy (symbols are interconnected and unequally probable), an average number of symbols will be required n = n„H(A) m JH(A).
A discrete source is also characterized by performance, determined by the number of symbols per unit of time v H:
If performance I(A) define in binary units, and time in seconds, then ON THE) - is the number of binary ones per second. For discrete sources that produce stationary sequences of symbols of sufficiently large length /?, the concepts are introduced: typical and atypical sequences of source symbols, into which all sequences of length can be divided P. All typical sequences N lMl (A) source at P-»oo have approximately the same probability of occurrence
The total probability of the appearance of all atypical sequences tends to zero. In accordance with equality (5.11), assuming that the probability of typical sequences /Nrm(A), the entropy of the source is equal to logN TIin (,4) and then
Let's consider the amount and speed of information transmission over a discrete channel with noise. Previously, information provided by a discrete source in the form of a sequence of symbols (i,) was considered.
Now suppose that the source information is encoded and represents a sequence of code symbols (b, (/ = 1,2,..T - code base), is consistent with a discrete information transmission channel, at the output of which a sequence of symbols appears
We assume that the encoding operation is one-to-one - based on the sequence of characters (b,) it is possible to uniquely reconstruct the sequence (i,), i.e. Using code symbols, you can completely restore the source information.
However, if we consider the escape symbols |?. j and input symbols (/>,), then due to the presence of interference in the information transmission channel, restoration is impossible. Entropy of the output sequence //(/?)
may be greater than the entropy of the input sequence N(V), but the amount of information for the recipient did not increase.
In the best case, one-to-one relationships between input and output are possible and useful information is not lost; in the worst case, nothing can be said about the input symbols from the output symbols of the information transmission channel, i.e. useful information is completely lost in the channel.
Let us estimate the loss of information in a noisy channel and the amount of information transmitted over a noisy channel. We consider that the symbol is transmitted correctly if, with the transmitted symbol, 6 is accepted
symbol bj with the same number (/ = j). Then for an ideal channel without noise we write:

By symbol bj-at the channel output due to inequalities (5.21)
uncertainty is inevitable. We can assume that the information in the symbol b i is not transmitted completely and part of it is lost in the channel due to interference. Based on the concept of a quantitative measure of information, we will assume that the numerical expression of the uncertainty arising at the output of the channel after receiving the symbol ft ; :
and it determines the quantity lost information in the channel during transmission.
Having fixed ft. and averaging (5.22) over all possible symbols, we obtain the sum
determining the amount of information lost in the channel when transmitting an elementary symbol over a channel without memory when receiving a symbol bj(t).
When averaging the sum (5.23) over all ft, we obtain the value Z?), which we denote by n(v/v- It determines the amount of information lost when transmitting one character over a channel without memory:

Where P^bjbjj - joint probability of an event that, during transmission
symbol b. it will accept the symbol b t.
N [v/ depends on the characteristics of the information source on
channel input IN and on the probabilistic characteristics of the communication channel. According to Shannon in statistical communication theory n(v/v called channel unreliability.
Conditional entropy NV/V, entropy of a discrete source
at the channel input N(V) and entropy And ^B) at its output cannot be
negative. In a channel without interference, channel unreliability
n(in/in = 0. In accordance with (5.20), we note that Н^в/В^
and equality occurs only when the input and output of the channel are statistically independent:
The output symbols do not depend on the input symbols - the case of a channel break or very strong interference.
As before, for typical sequences we can write
It means that in the absence of interference its unreliability
Under the average information transmitted over the channel J[ b/per one symbol we understand the difference between the amount of information at the channel input J(B) and information lost in the /? channel).
If the source of information and the channel are without memory, then
Expression (5.27) determines the entropy of the output symbols of the channel. Some of the information at the channel output is useful, and the rest is false, since it is generated by interference in the channel. Please note that n[v/ 2?) expresses information about interference in the channel, and the difference I(th)-I(th/th) - useful information, passed through the channel.
Note that the overwhelming number of sequences generated at the output of the channel are atypical and have a very low total probability.
As a rule, the most common type of interference is taken into account - additive noise. N(t); the channel output signal has the form:
For discrete signals, the equivalent noise, following from (5.28), has a discrete structure. Noise is a discrete random sequence, similar to the sequences of incoming and outgoing signals. Let us denote the symbols of the alphabet of additive noise in a discrete channel by Ts1 = 0, 1,2, T- 1). Conditional transition probabilities in such a channel
Because And (^B/?) And (B) then, therefore, the information of the output sequence discrete channel#(/) relative to input B(t) or vice versa I (B) - H^v/v) (5).
In other words, the information transmitted over the channel cannot exceed the information at its input.
If the channel input receives on average x k symbols per second, then we can determine the average speed of information transmission over a noisy channel:
Where Н(В) = V k J(B,B^ - source performance at the channel input; n(v/v) = U k n(v,v) ~ channel unreliability per unit time; H (B) = V k H^B^- performance of the source formed by the output of the channel (providing part of the useful and part of the false information); Н^в/В^ = У к 1/(в/в)- amount of false information,
generated interference in the channel per unit time.
The concepts of quantity and speed of information transmission over a channel can be applied to different sections of the communication channel. This may be the “encoder input - decoder output” section.
Note that when expanding the section of the channel under consideration, it is impossible to exceed the speed of any of its components. Any irreversible transformation leads to loss of information. Irreversible transformations include not only the impact of interference, but also detection and decoding with redundant codes. There are ways to reduce reception losses. This is "reception as a whole."
Let's consider the capacity of a discrete channel and optimal coding theorems. Shannon introduced a characteristic that determines the maximum possible speeds of information transmission over a channel with known properties (noise) under a number of restrictions on the ensemble of input signals. This is the capacity of channel C. For a discrete channel

where the maximum was taken care of according to possible sources of entry IN for a given V k and the volume of the alphabet of input characters T.
Based on the definition bandwidth of a discrete channel we write
Note that C = 0 with independent input and output (high level of interference in the channel) and, accordingly,
in the complete absence of interference on the signal.
For binary symmetrical channel without memory

Rice. 5.2.
Graph of the dependence of the binary channel capacity on the parameter R shown in Fig. 5.2. At R= 1/2 channel capacity C = 0, conditional entropy
//(/?//?) = 1. Practical interest
graph represents at 0
Shannon's fundamental theorem on optimal coding is related to the concept of capacity. Its formulation for a discrete channel is as follows: if the performance of the message source ON THE) less bandwidth of channel C:
There is a method for optimal encoding and decoding, in which case the probability of error or unreliability of the channel n[a!A j can be arbitrarily small. If
There are no such methods.
In accordance with Shannon’s theorem, the final value WITH is the limiting value of the error-free speed of information transmission over the channel. But for a noisy channel, ways to find the optimal code are not indicated. However, the theorem radically changed views on the fundamental capabilities of information transmission technology. Before Shannon, it was believed that in a noisy channel it was possible to obtain an arbitrarily small error probability by reducing the information transmission rate to zero. This is, for example, an increase in communication fidelity as a result of the repetition of symbols in a channel without memory.
Several rigorous proofs of Shannon's theorem are known. The theorem was proven for a discrete channel without memory using the random encoding method. In this case, the set of all randomly selected codes for this source and this channel, and the fact that the average probability of erroneous decoding for all codes asymptotically tends to zero with an unlimited increase in the duration of the message sequence is stated. Thus, only the fact of the existence of a code that provides the possibility of error-free decoding is proven, but an unambiguous encoding method is not proposed. At the same time, as the proof progresses, it becomes obvious that while maintaining the equality of the entropies of the ensemble of the sequence of messages and the one-to-one corresponding set of codewords used for transmission, the ensemble IN Additional redundancy must be introduced to ensure an increase in the mutual dependence of the sequence of code symbols. This can only be done by expanding the set of code sequences from which code words.
Despite the fact that the main coding theorem for channels with noise does not indicate unambiguous ways to select a specific code and they are also absent from the proof of the theorem, it can be shown that most of the randomly selected codes when encoding sufficiently long sequences of messages do not significantly exceed the average probability of erroneous decoding . However, the practical possibilities of encoding in long blocks are limited due to the difficulties of implementing memory systems and logical processing of sequences of a huge number of code elements, as well as increasing delays in the transmission and processing of information. In fact, of particular interest are the results that make it possible to determine the probability of erroneous decoding for finite values of duration P code blocks used. In practice, they are limited to moderate delay values and achieve an increase in the probability of transmission when the channel capacity is not fully used.
Material from Wikipedia - the free encyclopedia
Coding theory- the science of the properties of codes and their suitability for achieving a given goal.
General information
Coding is the process of converting data from a form convenient for immediate use into a form convenient for transmission, storage, automatic processing and preservation from unauthorized access. The main problems of coding theory include issues of one-to-one coding and the complexity of implementing a communication channel when given conditions:86. In this regard, coding theory primarily considers the following areas:18:
Data compression
Forward error correction
Cryptography
Cryptography (from ancient Greek. κρυπτός - hidden and γράφω - I write), this is an area of knowledge about methods of ensuring confidentiality (the impossibility of reading information by strangers), data integrity (the impossibility of discreetly changing information), authentication (verifying the authenticity of authorship or other properties of an object), as well as the impossibility of renouncing authorship
Coding theory. Types of coding Basic concepts of coding theory Previously, coding tools played an auxiliary role and were not considered as a separate subject of mathematical study, but with the advent of computers the situation has changed radically. Coding literally permeates information technology and is a central issue in solving a wide variety of (almost all) programming problems: ۞ representation of data of arbitrary nature (for example, numbers, text, graphics) in computer memory; ۞ protection of information from unauthorized access; ۞ ensuring noise immunity when transmitting data over communication channels; ۞ compression of information in databases. Coding theory is a branch of information theory that studies ways to identify messages with the signals that represent them. Task: Coordinate the source of information with the communication channel. Object: Discrete or continuous information reaching the consumer through an information source. Coding is the transformation of information into a formula convenient for transmission over a specific communication channel. An example of coding in mathematics is the coordinate method introduced by Descartes, which makes it possible to study geometric objects through their analytical expression in the form of numbers, letters and their combinations - formulas. The concept of coding means converting information into a form convenient for transmission over a specific communication channel. Decoding is the restoration of a received message from its encoded form into a form accessible to the consumer.
Topic 5.2. Alphabetic coding In general, the coding problem can be represented as follows. Let two alphabets A and B be given, consisting of a finite number of characters: and. The elements of the alphabet are called letters. Let us call an ordered set in the alphabet A a word, where we denote it by p =l()=| |. , the number n shows the number of letters in the word and is called the length of the word. An empty word is denoted by: For a word, the letter a1 is called the beginning, or prefix, of the word, the letter an is the ending, or postfix, of the word. , and Words can be combined. To do this, the prefix of the second word must immediately follow the postfix of the first, and in the new word they naturally lose their status, unless one of the words was empty. A combination of words and is denoted, a combination of n identical words is denoted by, and. We denote the set of all non-empty words of the alphabet A as A*: Set A is called the message alphabet, and set B is called the encoding alphabet. We denote the set of words composed in the alphabet B as B*.
Let us denote by F the mapping of words from alphabet A to alphabet B. Then we call the word a word code. Coding is called universal method displaying information during its storage, transmission and processing in the form of a system of correspondences between message elements and signals with the help of which these elements can be recorded. Thus, a code is a rule for unambiguously transforming (i.e., a function) a message from one symbolic form of representation (source alphabet A) to another (object alphabet B), usually without any loss of information. The process of transforming F: A* B*→ words of the original alphabet A into alphabet B is called information encoding. The process of transforming a word back is called decoding. Thus, decoding is the inverse function of F, i.e. F1. to word Since for any encoding a decoding operation must be performed, the mapping must be invertible (bijection). If |B|= m, then F is called mic encoding, the most common case is B = (0, 1) binary coding. It is this case that is considered further. If all codewords have the same length, then the code is called uniform, or block. Alphabetical (or letter-by-letter) encoding can be specified using a code table. The code or encoding function will be some kind of substitution. Then, where, . This letter-by-letter coding is called a set of elementary codes. Alphabetic encoding can be used for any set of messages. Thus, alphabetic encoding is the simplest and can always be introduced on non-empty alphabets. . Lots of letter codes
EXAMPLE Let the alphabets A = (0, 1, 2, 3, 4, 5, 6, 7, 8, 9) B = (0, 1) be given. Then the coding table can be a substitution: . This is binary decimal encoding, it is one-to-one and therefore can be decoded. However, the scheme is not one-to-one. For example, the set of six ones 111111 could match either the word 333 or 77, as well as 111111, 137, 3311, or 7111 plus any permutation. An alphabetic encoding scheme is called prefix if the elementary code of one letter is not a prefix of the elementary code of another letter. An alphabetic coding scheme is called separable if any word composed of elementary codes can be decomposed into elementary codes in a unique way. Alphabetic encoding with a separable scheme allows decoding. It can be proven that the prefix circuit is separable. In order for an alphabetic encoding scheme to be separable, the lengths of the elementary codes must satisfy a relationship known as McMillan's inequality. MacMillan's inequality If an alphabetic coding scheme
is separable, then the inequality is true. EXAMPLE The alphabetic coding scheme A = ( a, b) and B = (0, 1) is separable, because , and, therefore, McMillan’s inequality is satisfied This scheme is not a prefix, because the elementary code of the letter a is a prefix of the elementary code of the letter b. Topic 5.3. Coding with minimal redundancy In practice, it is important that message codes be as short as possible. Alphabetic coding is suitable for any messages, but if nothing is known about the set of all words of the alphabet A, then it is difficult to accurately formulate the optimization problem. However, in practice it is often available Additional Information. For example, for messages submitted to natural language, such additional information could be the probability distribution of letters appearing in the message. Then the problem of constructing an optimal code acquires an exact mathematical formulation and a rigorous solution.
Let some separable alphabetic coding scheme be given. Then any scheme where the ordered set is a permutation of the ordered set will also be separable. In this case, if the lengths of the elementary code sets are equal, then their rearrangement in the scheme does not affect the length of the encoded message. If the lengths of elementary codes are different, then the length of the message code directly depends on which elementary codes are assigned to which letters, and on the composition of the letters in the message. If a specific message and a specific encoding scheme are given, then it is possible to select a permutation of codes in which the length of the message code will be minimal. Algorithm for assigning elementary codes, in which the length of the fixed message code S will be minimal for a fixed scheme: ۞ sort the letters in descending order of the number of occurrences; ۞ sort elementary codes in ascending order of length; ۞ match the codes to the letters in the prescribed order. Let the alphabet and the probabilities of letters appearing in the message be given:
Where pi is the probability of occurrence of the letter ai, and letters with a zero probability of appearing in the message are excluded and the letters are ordered in descending order of probability of their occurrence. For a separable alphabetic coding scheme with a probability distribution P, there is a so-called average price, or coding length, - this is the mathematical expectation of the length of the encoded message, which is designated and defined as EXAMPLE. For a separable alphabetic coding scheme A = (a, b), B = (0,1), with a probability distribution, the coding cost is and with a probability distribution, the coding cost is
Topic 5.4. Huffman Coding This algorithm was invented in 1952 by David Huffman. Topic 5.5. Arithmetic Coding As with the Huffman algorithm, it all starts with a table of elements and corresponding probabilities. Let's say the input alphabet consists of only three elements: a1, a2 and a3, and at the same time P(a1) = 1/2 P(a2) = 1/3 P(a3) = 1/6 Let's also assume that we need to encode sequence a1, a1, a2, a3 . Let's split the half-interval, where p is some fixed number, 0<р<(r1)/2r, а "мощностная" граница где Tr(p)=p logr(p/(r 1))(1р)logr(l p), существенно улучшена. Имеется предположение, чт о верхняя граница полученная методом случайного выбора кода, является асимптотически точной, т. е. Ir(п,[ рп])~пТ r(2р).Доказательство или опровержение этого предположения одна из центральны х задач теории кодирования. Большинство конструкций помехоустойчивых кодов являются эффективными, когда длин а пкода достаточновелика. В связи с этим особое значение приобретают вопросы, связанны е со сложностью устройств,осуществляющих кодирование и декодирование (кодера и деко дера). Ограничения на допустимый типдекодера или его сложность могут приводить к увел ичению избыточности, необходимой для обеспечениязаданной помехоустойчивости. Напр., минимальная избыточность кода в В n 2, для крого существует декодер,состоящий из регист
ra shift and one majority element and correcting one error, has order (cf. (2)). As a mathematical Encoder and decoder models are usually considered from a diagram of functional elements and complexity is understood as the number of elements in the circuit. For known error-correcting class codes, a study of possible K and D algorithms was carried out and upper bounds on the complexity of the encoder and decoder were obtained. Unknown relationships have also been found between the coding transmission rate, coding noise immunity and decoder complexity (see). Another direction of research in coding theory is related to the fact that many results (for example, Shannon’s theorem and bound (3)) are not “constructive”, but represent theorems of the existence of infinite sequences of (Kn) codes. In this regard, efforts are being made To prove these results in the class of such sequences of (Kn) codes, for them there is a Turing machine that recognizes that an arbitrary word of length l belongs to a time set that has a slow growth order relative to l (for example, llog l). Several new constructions and methods for obtaining boundaries developed in coding theory have led to significant progress in issues that, at first glance, are very far from the traditional problems of coding theory. Here we should point out the use of a maximal code with one error correction in a symptotically optimal method for implementing logic algebra functions by contact circuits; in principle, an improvement in the upper bound for the packing density of a redimensional Euclidean space by equal balls; on the use of inequality (1) when assessing the complexity of the implementation by formulas of one class of logical algebra functions. The ideas and results of coding theory find their further development in problems of synthesizing self-correcting schemes and reliable schemes from unreliable elements. Lit.: Shannon K., Works on information theory and cybernetics, trans. from English, M., 1963; Berlekamp E., Algebraic coding theory, trans. from English, M., 1971; Peterson W., Weldon E., Error Correcting Codes, trans. from English, 2nd ed., M., 1976; Discrete mathematics and mathematical problems of cybernetics, vol. 1, M., 1974, section 5; Bassalygo L. A., Zyablov V. V., Pinsker M. S., "Problem of information transmission", 1977, v. 13, no. 3, p. 517; [In] Sidelnikov V.M., "Mathematical collection", 1974, vol. 95, century. 1, p. 148 58. V. I. Levenshtein.
Mathematical encyclopedia. - M.: Soviet Encyclopedia. I. M. Vinogradov. 1977-1985. ALPHABETIC CODING COEUCLIDian SPACE See also in other dictionaries: DECODING - see Encoding and Decoding... Mathematical Encyclopedia Encoding of audio information - This article should be Wikified. Please format it according to the article formatting rules. The basis of sound coding using a PC is the process of converting air vibrations into electrical vibrations ... Wikipedia CODING - (from the French code - a set of laws, rules) - display (transformation) of certain objects (events, states) into a system of structural objects (called code images), performed according to a definition. rules, a set of so-called code K.,... ...Philosophical Encyclopedia INFORMATION CODING - establishing correspondence between message elements and signals, with the help of which these elements can be recorded. Let B be a set of message elements, A be an alphabet with symbols, Let a finite sequence of symbols be called in a word... ... Physical Encyclopedia OPTIMAL CODING - (in engineering psychology) (English optimal coding) the creation of codes that ensure maximum speed and reliability of receiving and processing information about an object controlled by a human operator (see Information Reception, Decoding). Problem of K. o.... ... Great psychological encyclopedia DECODING (in engineering psychology) - (English decoding) the final operation of the process of receiving information by a human operator, consisting of re-encoding the parameters characterizing the state of the control object, and translating them into the image of the controlled object ( see Coding... ... Great Psychological Encyclopedia
Decoding - restoration of a message encoded by transmitted and received signals (see Coding) ... Economics and mathematics dictionary CODING - CODING. One of the stages of speech generation, while “decoding” is reception and interpretation, the process of understanding a speech message. See psycholinguistics... New dictionary of methodological terms and concepts (theory and practice of language teaching) CODING - (English coding). 1. Conversion of a signal from one energy form to another. 2. Conversion of one system of signals or signs into another, which is often also called “recoding”, “code change” (for speech “translation”). 3. K. (mnemonic)… … Great psychological encyclopedia Decoding - This article is about code in information theory, for other meanings of this word, see code (meanings). The code is a rule (algorithm) for matching each specific message with a strictly defined combination of symbols (signs) (or signals). A code is also called... ... Optimal encoding The same message can be encoded in different ways. We will consider the optimally encoded code to be one in which the minimum time is spent transmitting messages. If the same time is spent on transmitting each elementary symbol (0 or 1), then the optimal code will be one that has the minimum possible length. Example 1. Let there be a random variable X(x1,x2,x3,x4,x5,x6,x7,x8) having eight states with a probability distribution. To encode an alphabet of eight letters without taking into account probabilities with a uniform binary code, we need three symbols: This 000, 001, 010, 011, 100, 101, 110, 111 To answer whether this code is good or not, you need to compare it with the optimal value, that is, determine the entropy
Having determined the redundancy L using the formula L=1H/H0=12.75/3=0.084, we see that it is possible to reduce the code length by 8.4%. The question arises: is it possible to create a code in which there are, on average, fewer elementary symbols per letter? Such codes exist. These are ShannonFano and Huffman codes. The principle of constructing optimal codes: 1. Each elementary character must carry the maximum amount of information; for this it is necessary that the elementary characters (0 and 1) in the encoded text occur on average equally often. Entropy in this case will be maximum. 2. It is necessary to assign shorter code words of the secondary alphabet to letters of the primary alphabet that have a high probability.
04/04/2006 Leonid Chernyak Category:Technology
“Open systems” The creation of computers would have been impossible if, simultaneously with their appearance, the theory of signal coding had not been created. Coding theory is one of those areas of mathematics that significantly influenced the development of computing.
"Open Systems"
The creation of computers would have been impossible if the theory of signal coding had not been created at the same time as their appearance.
Coding theory is one of those areas of mathematics that has significantly influenced the development of computing. Its scope extends to data transmission over real (or noisy) channels, and its subject is to ensure the correctness of the transmitted information. In other words, it studies how best to package data so that once the signal is transmitted, useful information can be reliably and easily extracted from the data. Sometimes coding theory is confused with encryption, but this is incorrect: cryptography solves the inverse problem, its goal is to make it difficult to obtain information from data.
The need to encode data was first encountered more than a hundred and fifty years ago, shortly after the invention of the telegraph. The channels were expensive and unreliable, which made it urgent to minimize the cost and increase the reliability of telegram transmission. The problem became even more acute due to the laying of transatlantic cables. Since 1845, special code books came into use; With their help, telegraph operators manually performed “compression” of messages, replacing common sequences of words with shorter codes. At the same time, parity control began to be used to check the correctness of the transmission, a method that was used to check the correctness of entering punched cards also in computers of the first and second generations. To do this, a specially prepared card with a checksum was inserted last into the input deck. If the input device was not very reliable (or the deck was too large), then an error could occur. To correct it, the entry procedure was repeated until the calculated checksum coincided with the amount stored on the card. Not only is this scheme inconvenient, it also allows double errors. With the development of communication channels, a more effective control mechanism was required.
The first theoretical solution to the problem of data transmission over noisy channels was proposed by Claude Shannon, the founder of statistical information theory. Shannon was a star of his time, he was one of the academic elite of the United States. As a graduate student of Vannevar Bush, in 1940 he received the Nobel Prize (not to be confused with the Nobel Prize!), awarded to scientists under 30 years of age. While at Bell Labs, Shannon wrote A Mathematical Theory of Message Transmission (1948), where he showed that if the channel capacity is greater than the entropy of the message source, then the message can be encoded so that it is transmitted without unnecessary delays. This conclusion is contained in one of the theorems proved by Shannon; its meaning boils down to the fact that if there is a channel with sufficient bandwidth, a message can be transmitted with some time delays. In addition, he showed the theoretical possibility of reliable transmission in the presence of noise in the channel. The formula C = W log ((P+N)/N), carved on a modest monument to Shannon in his hometown in Michigan, has been compared in value to Albert Einstein's formula E = mc 2.
Shannon's works provided food for many further studies in the field of information theory, but they had no practical engineering applications. The transition from theory to practice was made possible thanks to the efforts of Richard Hamming, Shannon's colleague at Bell Labs, who became famous for the discovery of a class of codes that came to be called “Hamming codes.” There is a legend that Hamming was prompted to invent his codes by the inconvenience of working with punched cards on the Bell Model V relay adding machine in the mid-40s. He was given time to work on the machine on weekends when there were no operators and he had to fiddle with the input himself. Be that as it may, Hamming proposed codes capable of correcting errors in communication channels, including in data transmission lines in computers, primarily between the processor and memory. Hamming codes became evidence of how the possibilities pointed out by Shannon's theorems could be practically realized.
Hamming published his paper in 1950, although internal reports date his coding theory to 1947. Therefore, some believe that Hamming, not Shannon, should be considered the father of coding theory. However, in the history of technology it is useless to look for the first.
What is certain is that it was Hamming who first proposed “error-correcting codes” (Error-Correcting Code, ECC). Modern modifications of these codes are used in all data storage systems and for exchange between the processor and RAM. One of their variants, Reed-Solomon codes, is used in compact discs, allowing recordings to be played without squeaks and noise that could cause scratches and dust particles. There are many versions of Hamming codes, they differ in coding algorithms and the number of check bits. Such codes have acquired particular importance in connection with the development of deep space communications with interplanetary stations; for example, there are Reed-Muller codes, where there are 32 control bits for seven information bits, or 26 for six.
Among the newest ECC codes are LDPC (Low-Density Parity-check Code). In fact, they have been known for about thirty years, but particular interest in them has emerged in recent years, when high-definition television began to develop. LDPC codes are not 100% accurate, but the error rate can be adjusted to the desired level while maximizing the use of channel capacity. “Turbo Codes” are close to them; they are effective when working with objects located in deep space and with limited channel capacity.
The name of Vladimir Aleksandrovich Kotelnikov is firmly inscribed in the history of coding theory. In 1933, in “Materials on Radio Communications for the First All-Union Congress on the Technical Reconstruction of Communications,” he published the work “On the Bandwidth of the Air? and?wires? Kotelnikov's name is included as an equal in the title of one of the most important theorems of coding theory. This theorem defines the conditions under which the transmitted signal can be restored without loss of information.
This theorem is called by many names, including the "WKS theorem" (the abbreviation WKS is taken from Whittaker, Kotelnikov, Shannon). Some sources use both the Nyquist-Shannon sampling theorem and the Whittaker-Shannon sampling theorem, and in domestic university textbooks, simply “Kotelnikov’s theorem” is most often found. In fact, the theorem has a longer history. Its first part was proved in 1897 by the French mathematician Emile Borel. Edmund Whittaker made his contribution in 1915. In 1920, the Japanese Kinnosuki Ogura published amendments to Whittaker's research, and in 1928, the American Harry Nyquist clarified the principles of digitization and restoration of an analog signal.

Claude Shannon(1916 - 2001) from his school years showed equal interest in mathematics and electrical engineering. In 1932, he entered the University of Michigan, in 1936 - the Massachusetts Institute of Technology, from which he graduated in 1940, receiving two degrees - a master's degree in electrical engineering and a doctorate in mathematics. In 1941, Shannon joined Bell Laboratories. Here he began to develop ideas that later resulted in information theory. In 1948, Shannon published the article “Mathematical Theory of Communication,” where the basic ideas of the scientist were formulated, in particular, determining the amount of information through entropy, and also proposed a unit of information that determines the choice of two equally probable options, that is, what was later called a bit . In 1957-1961, Shannon published papers proving the theorem on the capacity of noisy communication channels, which now bears his name. In 1957, Shannon became a professor at the Massachusetts Institute of Technology, from where he retired after 21 years. During his “well-deserved retirement,” Shannon completely devoted himself to his long-time hobby of juggling. He built several juggling machines and even created a general theory of juggling.

Richard Hamming(1915 - 1998) began his education at the University of Chicago, where he received a bachelor's degree in 1937. He received a master's degree from the University of Nebraska in 1939 and a doctorate in mathematics from the University of Illinois. In 1945, Hamming began working as part of the Manhattan Project, a large-scale government research effort to create an atomic bomb. In 1946, Hamming went to work at Bell Telephone Laboratories, where he worked, among other things, with Claude Shannon. In 1976, Hamming received a chair at the Naval Postgraduate School at Monterey in California.
The work that made him famous, a fundamental study of error detection and correction codes, was published by Hamming in 1950. In 1956, he was involved in work on one of the early IBM 650 mainframe computers. His work laid the foundation for a programming language that later evolved into high-level programming languages. In recognition of Hamming's contributions to computer science, the IEEE established a medal for outstanding achievements in the development of computer science and systems theory, which was named after him.

Vladimir Kotelnikov(1908 - 2005) in 1926 he entered the Electrical Engineering Faculty of the Moscow Higher Technical School named after N. E. Bauman (MVTU), but became a graduate of the Moscow Power Engineering Institute (MPEI), which separated from the Moscow Higher Technical School as an independent institute. During his graduate studies (1931-1933), Kotelnikov mathematically precisely formulated and proved the “reference theorem,” which was later named after him. After graduating from graduate school in 1933, Kotelnikov, while remaining teaching at MPEI, went to work at the Central Scientific Research Institute of Communications (TsNIIS). In 1941, V. A. Kotelnikov formulated a clear statement about what requirements a mathematically indecipherable system must satisfy and provided proof of the impossibility of deciphering it. In 1944, Kotelnikov took the position of professor and dean of the radio engineering faculty of Moscow Power Engineering Institute, where he worked until 1980. In 1953, at the age of 45, Kotelnikov was immediately elected a full member of the USSR Academy of Sciences. From 1968 to 1990, V. A. Kotelnikov was also a professor and head of the department at the Moscow Institute of Physics and Technology.
The Birth of Coding Theory