Какво е ansi? Защо вместо руски букви в конзолното приложение се показва боклук.
Често при уеб програмирането и оформлението на html страници трябва да помислите за кодирането на редактирания файл - в крайна сметка, ако кодирането е избрано неправилно, тогава има шанс браузърът да не може да го определи автоматично и като резултат потребителят ще види т.нар. "Кракозябри".
Може би вие сами сте виждали на някои сайтове вместо нормален текст неразбираеми символии въпросителни знаци. Всичко това се случва, когато кодирането на html страницата и кодирането на самия файл на тази страница не съвпадат.
Изобщо, какво е кодиране на текст?Това е просто набор от знаци на английски "charset" (набор от знаци).Има нужда от това, за да текстова информацияда бъдат преобразувани в битове данни и предадени, например, по интернет.
Всъщност основните параметри, които отличават кодировките, са броят на байтовете и наборът от специални знаци, в които се преобразува всеки знак от изходния текст.
Кратка история на кодировките:
Един от първите, които предават цифрова информация, беше появата на ASCII кодирането - Американски стандартен код за обмен на информация - американска стандартна кодова таблица,приет от Американския национален институт по стандартизация - Американски национален институт по стандартизация (ANSI).
Тези съкращения могат да бъдат объркващи.За практиката е важно да се разбере, че изходното кодиране на създадените текстови файлове може да не поддържа всички знаци на някои азбуки (например йероглифи), така че има тенденция да се премине към т.н. Наречен. стандартен Уникод (Уникод), който поддържа универсални кодировки − utf-8, utf-16, utf-32и т.н.
Най-популярното Unicode кодиране е Utf-8. Обикновено страниците на сайта вече се набират в него и се пишат различни скриптове. Тя ви позволява лесно да показвате различни йероглифи, гръцки букви и други възможни и немислими знаци (размер на символа до 4 байта). По-специално, всички файлове на WordPress и Joomla са написани в това кодиране. Освен това някои уеб технологии (по-специално AJAX) могат да обработват нормално само utf-8 символи.

Задаване на кодировки текстов файлкогато го създавате с обикновен бележник. Може да се кликне
В Runet все още можете да намерите сайтове, написани с очакване за кодиране Windows-1251 (или cp-1251).Това е специално кодиране, предназначено специално за кирилица.
ANSI-лумен (lm, lm), единицата е...
ANSI лумени е мерна единица за осветеност в мултимедийни проектори, създадена от лампа, когато тя свети през леща. „Lumen“ на латински означава „светлина“, ANSI означава „Американски национален институт по стандартизация“. Това е стандарт за измерване на светлинния поток, използван за сравняване на проектори.
Този параметър е въведен през 1992 г. от Американския национален институт по стандартизация като единица, която характеризира средния светлинен поток на 40" контролен екран при минималното фокусно разстояние на вариообектива на проектора.
Измерването се извършва на напълно бяла картина (пълно бяло), осветеността на екрана се измерва с помощта на луксметър в лукс (Lux) в 9 контролни точки на екрана. Стойността на светлинния поток се изчислява като средната стойност от тези 9 измервания - умножена по неговата площ и осреднена.
Получената светлинна енергия на екрана на квадратен метър се посочва в луксове и се намира по формулата: лукс = лумен / m². Но измерването на лумени/лукс варира в зависимост от околната среда, настройката на осветителното тяло и проектираното изображение, поради което ANSI лумени на използваемия светлинен поток днес се превърна в стандарт.
Такова измерване позволява да се оцени равномерността на разпределението на светлинния поток върху повърхността на екрана. Намаляването на яркостта на изображението в неговите краища се нарича "Гореща точка" или светло петно. Еднородността на разпределението на светлинния поток се изчислява като съотношението на най-малкото и най-голямото от получените измервания на осветеност. При добрите проектори тази стойност не пада под 70%.
Тази техника точно описва реда, в който се правят измерванията. При строго определени условия заобикаляща средаи настройките на устройството, проектираното на екрана изображение се разделя на девет равни части, като във всяка от тях се определя светлинната енергия. Средната стойност, получена от всичките девет измервания и умножена по площта на екрана в m², дава стойността на ANSI лумена.
Интересно е, че светлинният поток, за разлика от осветеността (измерена в ANSI лумени), не зависи от проектираната площ. В допълнение, посочените от производителя ANSI лумени често се основават на референтни максимални настройки, които рядко се използват на практика.
Освен това често стойността на лумените по ANSI е само средна стойност, така че е трудно да се каже от нея колко добре или зле проекторът разпределя светлината по повърхността на екрана.
ANSI лумена за цифрови проектори може да варира от 900 ANSI лумена за по-старите модели до 4700 ANSI лумена за днешните осветителни тела с висока мощност. Един добър цифров проектор за домашно кино трябва да бъде около 2000 ANSI лумена.
Reg.ru: домейни и хостинг
Най-големият регистратор и хостинг доставчик в Русия.
Над 2 милиона имена на домейни в услуга.
Промоция, поща за домейн, решения за бизнеса.
Повече от 700 хиляди клиенти по света вече са направили своя избор.
*Задръжте курсора на мишката, за да спрете превъртането на пауза.
Назад напред
Кодировки: полезна информация и кратка ретроспекция
Реших да напиша тази статия като малък преглед на проблема с кодировките.
Ще разберем какво е кодирането като цяло и ще се докоснем малко до историята на това как са се появили по принцип.
Ще говорим за някои от техните характеристики и също така ще разгледаме точките, които ни позволяват да работим с кодировките по-съзнателно и да избягваме т.нар. кракозябров, т.е. нечетливи знаци.
Така че да тръгваме...
Какво е кодиране?
Просто казано, кодиранее таблица със съпоставяния на знаци, които можем да видим на екрана, към определени цифрови кодове.
Тези. всеки знак, който въвеждаме от клавиатурата или виждаме на екрана на монитора, е кодиран определена последователностбитове (нули и единици). 8 бита, както вероятно знаете, са равни на 1 байт информация, но повече за това по-късно.
Външният вид на самите символи се определя от файловете с шрифтовекоито са инсталирани на вашия компютър. Следователно процесът на показване на текст на екрана може да се опише като постоянно съпоставяне на поредици от нули и единици към някои специфични знаци, които са част от шрифта.
Може да се счита за прародител на всички съвременни кодировки ASCII.
Това съкращение означава Американски стандартен код за обмен на информация(Американска стандартна кодираща таблица за печатни знаци и някои специални кодове).
Това еднобайтово кодиране, който първоначално съдържаше само 128 знака: букви от латинската азбука, арабски цифри и др.

По-късно той беше разширен (първоначално не използваше всичките 8 бита), така че стана възможно да се използват не 128, а 256 (2 до 8) различни символа, които могат да бъдат кодирани в един байт информация.
Това подобрение направи възможно добавянето към ASCII символи на националните езици, в допълнение към вече съществуващата латиница.
Има много опции за разширено ASCII кодиране, поради факта, че има и много езици в света. Мисля, че много от вас са чували за такова кодиране като KOI8-R също е разширено ASCII кодиране, проектиран да работи с руски знаци.
Следваща стъпка в развитието на кодировките може да се счита появата на т.нар ANSI кодировки.
По същество те бяха еднакви разширени версии на ASCII, но от тях бяха премахнати различни псевдографични елементи и бяха добавени типографски символи, за които преди това нямаше достатъчно „свободни пространства“.
Пример за такова ANSI кодиране е добре познатото Windows-1251. В допълнение към типографските символи, това кодиране включваше и букви от азбуките на езици, близки до руския (украински, беларуски, сръбски, македонски и български).
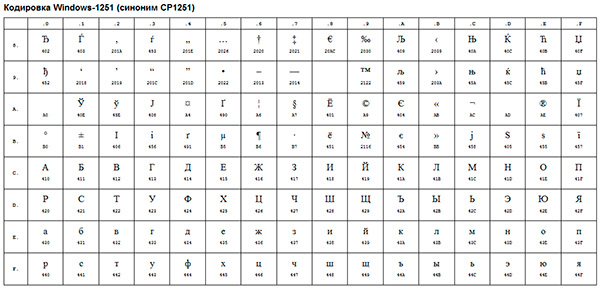
ANSI кодирането е общото име за. Всъщност действителното кодиране при използване на ANSI ще се определя от това, което е посочено в системния регистър на вашия операционна система Windows. В случай на руски това ще бъде Windows-1251, но за други езици ще бъде различен вид ANSI.
Както разбирате, куп кодировки и липсата на единен стандарт не доведоха до добро, което беше причината за честите срещи с т.нар. кракозябри- нечетлив безсмислен набор от знаци.
Причината за появата им е проста - тя е опитайте се да покажете знаци, кодирани с една таблица за кодиране, като използвате друга таблица за кодиране.
В контекста на уеб разработката може да срещнем грешки, когато напр. Руският текст е записан погрешно в грешното кодиране, което се използва на сървъра.
Разбира се, това не е единственият случай, когато можем да получим нечетлив текст - тук има много опции, особено като имате предвид, че има и база данни, в която информацията също се съхранява в определено кодиране, има връзка с база данни картографиране и др.
Появата на всички тези проблеми послужи като стимул за създаване на нещо ново. Предполагаше се, че това е кодиране, което може да кодира всеки език в света (в края на краищата, с помощта на еднобайтови кодировки, с цялото желание е невъзможно да се опишат всички знаци, да речем, на китайския език, където очевидно има повече от 256), всякакви допълнителни специални символи и типография.
С една дума, беше необходимо да се създаде универсално кодиране, което ще реши проблема с грешките веднъж завинаги.
Unicode - универсално кодиране на текст (UTF-32, UTF-16 и UTF-8)
Самият стандарт е предложен през 1991 г. от организация с нестопанска цел "Консорциум Unicode"(Unicode Consortium, Unicode Inc.), а първият резултат от неговата работа е създаването на кодиране UTF-32.
Между другото съкр UTFозначава Unicode формат за трансформация(Формат за конвертиране на Unicode).
При това кодиране, за да се кодира един знак, трябваше да се използват колкото се може повече 32 бита, т.е. 4 байта информация. Ако сравним това число с еднобайтови кодировки, тогава ще стигнем до просто заключение: за да кодирате 1 знак в това универсално кодиране, трябва 4 пъти повече бита, което "претегля" файла 4 пъти.
Също така е очевидно, че броят на знаците, които потенциално биха могли да бъдат описани с помощта на това кодиране, надхвърля всички разумни ограничения и е технически ограничен до число, равно на 2 на степен 32. Ясно е, че това беше явно прекаляване и прахосничество по отношение на теглото на файловете, така че това кодиране не беше широко използвано.
Той беше заменен от нова разработка - UTF-16.
Както подсказва името, в това кодиране се кодира един знак вече не 32 бита, а само 16(т.е. 2 байта). Очевидно това прави всеки знак два пъти "по-лек" отколкото в UTF-32, но и два пъти по-"тежък" от всеки знак, кодиран с помощта на еднобайтово кодиране.
Броят на наличните знаци за кодиране в UTF-16 е най-малко 2 на степен 16, т.е. 65536 знака. Всичко изглежда наред, освен това крайната стойност на кодовото пространство в UTF-16 е разширена до повече от 1 милион знака.
Това кодиране обаче не задоволи напълно нуждите на разработчиците. Да речем, че ако пишете, използвайки изключително латински символи, тогава след преминаване от разширената версия на ASCII кодирането към UTF-16, теглото на всеки файл се удвоява.
Като резултат, беше направен още един опит да се създаде нещо универсално, и това нещо се превърна в добре познатото UTF-8 кодиране.
UTF-8- Това многобайтово кодиране на знаци с променлива дължина на знаците. Гледайки името, може да си помислите, по аналогия с UTF-32 и UTF-16, че 8 бита се използват за кодиране на един знак, но това не е така. По-точно, не съвсем така.
Това е така, защото UTF-8 осигурява най-добрата съвместимост с по-стари системи, които използват 8-битови знаци. За кодиране на един знак в действителност се използва UTF-8 1 до 4 байта(хипотетично е възможно до 6 байта).
В UTF-8 всички латински знаци са кодирани с 8 бита, точно както при ASCII кодирането.. С други думи, основната част от ASCII кодирането (128 знака) се премести в UTF-8, което ви позволява да "прекарате" само 1 байт за тяхното представяне, като същевременно запазите универсалността на кодирането, за което всичко е започнато.
Така че, ако първите 128 знака са кодирани с 1 байт, тогава всички останали символи вече са кодирани с 2 байта или повече. По-конкретно, всеки знак на кирилица е кодиран с точно 2 байта.
По този начин получихме универсално кодиране, което ни позволява да покрием всички възможни знаци, които трябва да бъдат показани, без излишни "по-тежки" файлове.
С BOM или без BOM?
Ако сте работили с текстови редактори(от редактори на кодове), например Notepad++, phpDesigner, бърз PHPи т.н., тогава вероятно са обърнали внимание на факта, че когато задавате кодирането, в което ще бъде създадена страницата, обикновено можете да изберете 3 опции:
ANSI
-UTF-8
- UTF-8 без BOM



Веднага трябва да кажа, че винаги си струва да изберете последната опция - UTF-8 без BOM.
И така, какво е BOM и защо не ни трябва?
BOMозначава Марка за ред на байтове. Това е специален Unicode символ, използван за указване на реда на байтовете на текстов файл. Според спецификацията използването му не е задължително, но ако BOMсе използва, той трябва да бъде зададен в началото на текстовия файл.
Няма да навлизаме в детайли на работата BOM. За нас основният извод е следният: използването на този служебен символ заедно с UTF-8 не позволява на програмите да четат нормално кодирането, което води до грешки в скрипта.
ANSI е институция за стандартизация на индустриални методи и технологии. Член е на Международната организация по стандартизация (ISO). В Германия има аналог на такава организация - Германският институт по стандартизация (DIN), в Австрия - Австрийският институт по стандартизация (ASI), в Швейцария - Швейцарската асоциация по стандартизация (SNV).
Въпреки че ANSI кодовете се намират в много индустриални области, компютърното съкращение "ANSI" се отнася до специфична група знаци, базирани на ASCII. Няма истински стандарт ANSI, но проектите на ANSI плавно са приели стандарта ISO 8859.
ANSI задачи
Основната задача на Американския национален институт по стандартизация (ANSI) е разпространението и прилагането на националните стандарти на САЩ по света, в предприятията във всички страни.
В допълнение, работата на този институт решава проблемите от глобален мащаб:
- защита на околната среда,
- индустриална безопасност,
- безопасност на домакинството.
Известно е, че в Съединените щати, както и в Русия, стандартите се регулират предимно от държавата (въпреки че ANSI се позиционира като неправителствена организация с нестопанска цел), така че желанието да се запълни тази ниша и да се пренесат всички норми в Америка знаменател е напълно логична и последователна мисъл. Всъщност чрез стандартите е възможно да се разпространяват не само чисто технически иновации, но и да се провежда държавна външна политика на глобализация и световна интеграция.
Голям бюджет се изразходва за подкрепа на програмата ANSI от държавата, която се изразходва главно за оптимизиране, актуализиране и реорганизация на производствените методи. В стоманодобивната промишленост стандартите ANSI отдавна са се утвърдили като едни от най-добрите в света.
Нашата компания също така желае да работи в производството на фланцови продукти, които се продават в огромни количества на промишлени предприятия в Русия и страните от ОНД.