Vad är index för i sql. Index i SQL Server
1) Begreppet ett index
Indexär ett verktyg som ger snabb åtkomst till raderna i en tabell baserat på värdena i en eller flera kolumner.
Det finns mycket variation i denna operatör, eftersom den inte är standardiserad, eftersom standarderna inte rör prestandafrågor.
2) Skapa index
SKAPA INDEX
PÅ()
3) Ändra och ta bort index
Operatören används för att styra indexaktivitet:
ÄNDRA INDEX
För att ta bort ett index, använd operatorn:
SLIPP INDEX
a) Regler för tabellval
1. Det är tillrådligt att indexera tabeller där högst 5 % av raderna är valda.
2. Indextabeller som inte har dubbletter i WHERE-satsen i SELECT-satsen.
3. Det är opraktiskt att indexera ofta uppdaterade tabeller.
4. Det är olämpligt att indexera tabeller som inte upptar mer än 2 sidor (för Oracle är detta färre än 300 rader), eftersom hela genomsökningen inte tar längre tid.
b) Regler för kolumnval
1. Primära och främmande nycklar - används ofta för att sammanfoga tabeller, välja data och söka. Dessa är alltid unika index med maximal användbarhet
2. Vid användning av referensintegritetsalternativen behövs alltid ett index på FK.
3. Kolumner som data ofta sorteras och/eller grupperas efter.
4. Kolumner som ofta söks i WHERE-satsen i en SELECT-sats.
5. Skapa inte index för långa beskrivande kolumner.
c) Principer för att skapa sammansatta index
1. Sammansatta index är bra om kolumnerna individuellt har få unika värden, och det sammansatta indexet ger mer unikhet.
2. Om alla värden som valts av SELECT-satsen tillhör det sammansatta indexet, väljs värdena från indexet.
3. Du bör skapa ett sammansatt index om WHERE-satsen använder två eller flera värden kombinerade med en AND-operator.
d) Det rekommenderas inte att skapa
Det rekommenderas inte att skapa index på kolumner, inklusive sammansatta, som:
1. Används sällan för att söka, slå samman och sortera frågeresultat.
2. Innehåller ofta växlande värden, vilket kräver frekvent uppdatering av indexet och saktar ner prestandan för databasen.
3. Innehåller nr Ett stort antal unika värden (mindre än 10 % m/f) eller det övervägande antalet rader med ett eller två värden (leverantörens hemstad Moskva).
4. Funktioner eller ett uttryck tillämpas på dem i WHERE-satsen, och indexet fungerar inte.
e) Glöm inte
Du bör sträva efter att minska antalet index, eftersom ett stort antal av dem minskar hastigheten för uppdatering av data. MS alltså SQL Server rekommenderar att du inte skapar fler än 16 index per tabell.
Vanligtvis skapas index för att fråga och bibehålla referensintegritet.
Om ett index inte används för frågor, bör det tas bort och referensintegritet upprätthållas med hjälp av utlösare.
Till att börja med föreslår jag att förstå vad som är täckande index, Jag kommer att ge ett utdrag ur en artikel om Habré:
Varför använda ett täckande index istället för ett sammansatt index?
Låt oss först se till att vi förstår skillnaden mellan dem.
Sammansatt index det är bara ett vanligt index som innehåller mer än en kolumn. Flera nyckelkolumner kan användas för att säkerställa att varje tabellrad är unik, det är också möjligt att primärnyckeln består av flera kolumner för att säkerställa dess unikhet, eller så försöker du optimera exekveringen av ofta anropade frågor på flera kolumner. I allmänhet gäller dock att ju fler nyckelkolumner ett index innehåller, desto mindre effektivt är indexet, och därför bör sammansatta index användas med omtanke.Som sagt kan en fråga skörda enorma fördelar om all nödvändig data omedelbart finns på bladen av indexet, precis som själva indexet. Detta är inte ett problem för ett klustrat index, som all data finns redan där (det är därför det är så viktigt att tänka noga när du skapar ett klustrat index). Men det icke-klustrade indexet på bladen innehåller bara nyckelkolumnerna. Frågeoptimeraren behöver ytterligare steg för att komma åt all annan data, vilket kan orsaka betydande extra kostnader för att köra dina frågor.
Det är där täckande index skyndar sig att hjälpa. När du definierar ett icke-klustrat index kan du ange ytterligare kolumner utöver dina nyckel.
Det täckande indexet bör alltså inte innehålla alla valbara frågekolumner i indexträdstrukturen, utan endast de som kommer att användas för att filtrera eller gruppera data i frågan, de återstående kolumnerna från SELECT-satsen ska placeras i INCLUDE-indexsektionen.
Du kanske hittar svaret i en annan fråga till hjälp.
I exemplet ovan används ett 3-fälts sammansatt index istället för ett täckande index, koden för att skapa ett täckande index skulle vara:
SKAPA INKLUSTERAT INDEX PÅ . (ASC) INKLUDERA (, ) MED (PAD_INDEX=AV, STATISTICS_NORECOMPUTE=AV, SORT_IN_TEMPDB=AV, IGNORE_DUP_KEY=AV, DROP_EXISTING=AV, ONLINE=AV, ALLOW_ROW_LOCKS=PÅ, ALLOW_PAGE)_LOON
Svarar på din fråga:
för ett täckande index, ordningen på kolumnerna i INCLUDE-satsen inte viktigt, men kolumnordningen är viktig för sammansatt index, därför att kolumndata placeras i indexträdet i kolumnordning, och frågeoptimeraren kommer inte att kunna använda ett index med 2 kolumner för att endast slå upp 2-kolumnsvärden. Du kan se ett illustrativt exempel på hur en indexstruktur med 2 kolumner (EMPLOYEE_ID, SUBSIDIARY_ID) kommer att se ut i figuren.
6. Index och prestandaoptimering
Index i databaser: syfte, påverkan på prestanda, principer för att skapa index
6.1 Varför index behövs
Index är speciella strukturer i databaser som gör att du kan påskynda sökning och sortering efter ett specifikt fält eller uppsättning fält i en tabell, och som också används för att säkerställa att data är unika. Det enklaste sättet att jämföra index är med index i böcker. Om det inte finns någon pekare måste vi titta igenom hela boken för att hitta rätt plats, och med en pekare kan samma åtgärd utföras mycket snabbare.
Vanligtvis, ju fler index, desto bättre prestanda för databasfrågor. Men med en överdriven ökning av antalet index minskar prestandan för datamodifieringsoperationer (infoga/ändra/ta bort), storleken på databasen ökar, så att lägga till index bör behandlas med försiktighet.
Några generella principer relaterat till att skapa index:
· Index måste skapas för kolumner som används i joins, som ofta söks och sorteras. Det bör noteras att index alltid skapas automatiskt för kolumner som är föremål för primärnyckelbegränsningen. Oftast skapas de också för kolumner med en främmande nyckel (i Access - automatiskt);
Indexet måste finnas i automatiskt läge skapad för kolumner som har en unik begränsning;
· Det är bäst att skapa index för de fält där - det minsta antalet dubbletter av värden och data är jämnt fördelade. Oracle har speciella bitindex för kolumner med stor mängd dubbletter av värden, SQL Server och Access tillhandahåller inte denna typ av index;
· om sökningen ständigt utförs på en viss uppsättning kolumner (samtidigt), kan det i det här fallet vara vettigt att skapa ett sammansatt index (endast i SQL Server) - ett index för en grupp kolumner;
· När ändringar görs i tabeller ändras indexen som läggs på denna tabell automatiskt. Som ett resultat kan indexet vara mycket fragmenterat, vilket påverkar prestandan. Index bör regelbundet kontrolleras för fragmentering och defragmenteras. När du laddar en stor mängd data är det ibland vettigt att först ta bort alla index, och efter att operationen är klar, skapa dem igen;
· Index kan skapas inte bara för tabeller utan även för vyer (endast i SQL Server). Fördelar - möjligheten att beräkna fält inte vid tidpunkten för begäran, utan vid tidpunkten för uppkomsten av nya värden i tabellerna.
Ett av de viktigaste sätten att uppnå hög prestanda SQL Serverär användningen av index. Ett index påskyndar frågeprocessen genom att ge snabb åtkomst till rader med data i en tabell, ungefär som ett index i en bok hjälper dig att snabbt hitta den information du behöver. I den här artikeln kommer jag att ge kort recension index i SQL Server och förklara hur de är organiserade i databasen och hur de hjälper till att påskynda databasfrågor.Index skapas på kolumner i tabeller och vyer. Index ger ett sätt att snabbt slå upp data baserat på värdena i dessa kolumner. Om du till exempel skapar ett index på primärnyckeln och sedan slår upp dataraden med hjälp av primärnyckelvärdena, SQL Server hittar först indexvärdet och använder sedan indexet för att snabbt hitta hela raden med data. Utan ett index kommer en fullständig uppslagning (skanning) av alla tabellrader att utföras, vilket kan ha en betydande inverkan på prestandan.
Du kan skapa ett index för de flesta kolumner i en tabell eller vy. Undantaget är främst kolumner med datatyper för lagring av stora objekt ( LOBB), Till exempel bild, text eller varchar(max). Du kan också skapa index på kolumner som är avsedda att lagra data i formatet XML, men dessa index är ordnade lite annorlunda än de vanliga och deras övervägande ligger utanför ramen för denna artikel. Dessutom tar inte artikeln hänsyn kolumnbutik index. Istället fokuserar jag på de index som är vanligast i databaser. SQL Server.
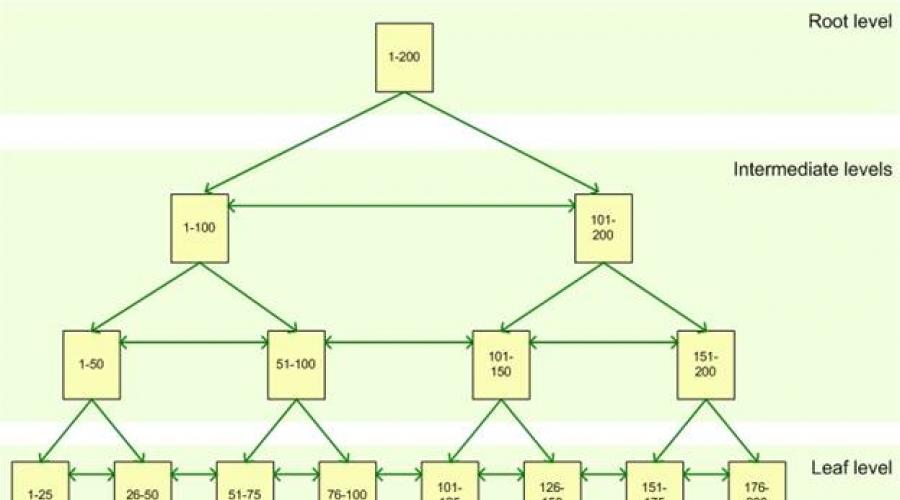
Ett index består av en uppsättning sidor, indexnoder, som är organiserade i en trädstruktur - balanserat träd. Denna struktur är hierarkisk till sin natur och börjar med en rotnod överst i hierarkin och slutnoder, blad, längst ner, som visas i figuren: 
När du frågar en indexerad kolumn startar frågemotorn överst i rotnoden och flyttar sig gradvis ner genom mellanliggande noder, där varje lager i mellanlagret innehåller mer detaljerad information om data. Frågeundersystemet fortsätter att röra sig genom indexets noder tills det når bottennivån med indexets blad. Om du till exempel letar efter värdet 123 i en indexerad kolumn, kommer frågemotorn först att fastställa sidan på rotnivån på den första mellannivån. I det här fallet pekar den första sidan på ett värde från 1 till 100 och den andra sidan pekar på ett värde från 101 till 200, så sökmotorn kommer att hänvisa till den andra sidan på denna mellannivå. Därefter kommer det att klargöras att du bör hänvisa till den tredje sidan på nästa mellannivå. Därifrån kommer frågeundersystemet att läsa på bottennivån värdet på själva indexet. Indexblad kan innehålla både själva tabelldata och bara en pekare till rader med data i tabellen, beroende på typ av index: klustrade eller icke-klustrade.
Klustrat index
Ett klustrat index lagrar de faktiska raderna med data i indexets blad. För att återgå till föregående exempel betyder detta att raden med data som är associerad med nyckelvärdet 123 kommer att lagras i själva indexet. En viktig egenskap Ett klustrat index är att alla värden är sorterade i en viss ordning, antingen stigande eller fallande. Således kan en tabell eller vy bara ha ett klustrat index. Dessutom bör det noteras att data i tabellen lagras i en sorterad form endast om ett klustrat index har skapats för denna tabell.En tabell utan ett klustrat index kallas en heap.
Icke-klustrade index
Till skillnad från ett klustrat index innehåller bladen i ett icke-klustrat index endast dessa kolumner ( nyckel), enligt vilken givet index, och innehåller även en pekare till rader med faktiska data i tabellen. Detta innebär att subquery-systemet behöver ytterligare en operation för att lokalisera och hämta de data som krävs. Innehållet i datapekaren beror på hur data lagras: en klustrad tabell eller en heap. Om pekaren pekar på en klustrad tabell, så pekar den på ett klustrat index som kan användas för att hitta den verkliga datan. Om pekaren hänvisar till en hög pekar den på en specifik dataradidentifierare. Icke-klustrade index kan inte sorteras, till skillnad från klustrade, däremot kan du skapa mer än ett icke-klustrat index på en tabell eller vy, upp till 999. Det betyder inte att du ska skapa så många index som möjligt. Index kan antingen förbättra eller försämra systemets prestanda. Förutom att du kan skapa flera icke-klustrade index, kan du även inkludera ytterligare kolumner ( inkluderad kolumn) till dess index: bladen på indexet kommer att lagra inte bara värdet på de indexerade kolumnerna själva, utan också värdena för dessa icke-indexerade ytterligare kolumner. Detta tillvägagångssätt låter dig kringgå några av de restriktioner som läggs på indexet. Du kan till exempel aktivera en icke-indexerad kolumn eller förbigå gränsen för indexlängd (900 byte i de flesta fall).Indextyper
Förutom att vara antingen klustrade eller icke-klustrade, kan ett index konfigureras ytterligare som ett sammansatt index, ett unikt index eller ett täckande index.Sammansatt index
Ett sådant index kan innehålla mer än en kolumn. Du kan inkludera upp till 16 kolumner i ett index, men deras totala längd är begränsad till 900 byte. Både klustrade och icke-klustrade index kan vara sammansatta.Unikt index
Ett sådant index säkerställer att varje värde i den indexerade kolumnen är unikt. Om indexet är sammansatt, gäller unikhet för alla kolumner i indexet, men inte för varje enskild kolumn. Till exempel om du skapar ett unikt index på kolumner NAMN Och EFTERNAMN, då måste det fullständiga namnet vara unikt, men dubbletter i för- eller efternamn är möjliga separat.Ett unikt index skapas automatiskt när du definierar kolumnbegränsningar: primärnyckel eller unik värdebegränsning:
- primärnyckel
När du definierar en primärnyckelrestriktion på en eller flera kolumner då SQL Server skapar automatiskt ett unikt klustrat index om ett klustrat index inte har skapats tidigare (i det här fallet skapas ett unikt icke-klustrat index av primärnyckeln) - Värderingars unika
När du definierar en begränsning för unika värden, då SQL Server skapar automatiskt ett unikt icke-klustrat index. Du kan ange att ett unikt klustrat index ska skapas om inget klustrat index ännu har skapats i tabellen
Täckande index
Ett sådant index tillåter en specifik fråga att omedelbart få all nödvändig data från indexets blad utan ytterligare anrop till själva tabellens poster.Indexdesign
Så användbara som index kan vara, måste de vara noggrant utformade. Eftersom index kan ta upp mycket diskutrymme vill du inte skapa fler index än du behöver. Dessutom uppdateras index automatiskt när själva dataraden uppdateras, vilket kan leda till ytterligare resursoverhead och prestandaförsämring. När man designar index finns det flera överväganden angående databasen och frågor mot den.Databas
Som nämnts tidigare kan index förbättra systemets prestanda eftersom de de ger frågemotorn ett snabbt sätt att hitta data. Du måste dock också ta hänsyn till hur ofta du ska infoga, uppdatera eller radera data. När du ändrar data måste indexen också ändras för att återspegla motsvarande åtgärder på data, vilket avsevärt kan försämra systemets prestanda. Tänk på följande riktlinjer när du planerar din indexeringsstrategi:- För tabeller som uppdateras ofta, använd så få index som möjligt.
- Om tabellen innehåller en stor mängd data, men deras ändringar är obetydliga, använd så många index som behövs för att förbättra prestandan för dina frågor. Tänk dock noga efter innan du använder index på små tabeller, som kanske kan det ta längre tid att använda en indexsökning än att bara skanna alla rader.
- För klustrade index, försök att hålla fälten så korta som möjligt. Den bästa praxisen skulle vara att använda ett klustrat index på kolumner som har unika värden och inte tillåter null. Det är därför den primära nyckeln ofta används som ett klustrat index.
- Det unika hos värdena i en kolumn påverkar indexets prestanda. Generellt gäller att ju fler dubbletter du har i en kolumn, desto sämre presterar indexet. Å andra sidan, ju mer unika värden, desto bättre hälsa har indexet. Använd ett unikt index när det är möjligt.
- För ett sammansatt index, ta hänsyn till ordningen på kolumnerna i indexet. Kolumner som används i uttryck VAR(Till exempel, WHERE FirstName = "Charlie") måste vara först i indexet. Efterföljande kolumner bör listas enligt unikheten hos deras värden (kolumner med det högsta antalet unika värden kommer först).
- Du kan också ange ett index på beräknade kolumner om de uppfyller vissa krav. Till exempel måste uttryck som används för att få värdet på en kolumn vara deterministiska (lämnar alltid samma resultat för en given uppsättning indataparametrar).
Databasfrågor
Ett annat övervägande när man utformar index är vilka frågor som görs mot databasen. Som nämnts tidigare måste du överväga hur ofta uppgifterna ändras. Dessutom bör följande principer användas:- Försök att infoga eller ändra så många rader som möjligt i en enda fråga, istället för att göra det i flera enstaka frågor.
- Skapa ett icke-klustrat index på kolumner som ofta används i dina frågor som söktermer i VAR och anslutningar i ANSLUTA SIG.
- Överväg att indexera kolumner som används i radsökningar för exakt värdematchning.
Och nu faktiskt:
14 SQL Server-indexfrågor som du var för generad för att ställa
Varför kan en tabell inte ha två klustrade index?
Vill du ha ett kort svar? Det klustrade indexet är tabellen. När du skapar ett klustrat index på en tabell, sorterar lagringsundersystemet alla rader i tabellen i stigande eller fallande ordning, enligt definitionen av index. Ett klustrat index är inte en separat enhet som andra index, utan en mekanism för att sortera data i en tabell och underlätta snabb åtkomst till datalinjer.Låt oss föreställa oss att du har en tabell som innehåller historiken för försäljningstransaktioner. Försäljningstabellen innehåller information som order-ID, artikelposition i ordern, artikelnummer, artikelkvantitet, ordernummer och datum och så vidare. Du skapar ett klustrat index på kolumner OrderID Och LineID, sorterade i stigande ordning som visas nedan T-SQL koda:
SKAPA UNIKT CLUSTERED INDEX ix_oriderid_lineid PÅ dbo.Sales(OrderID, LineID);
När du kör det här skriptet kommer alla rader i tabellen att sorteras fysiskt först efter OrderID-kolumnen och sedan efter LineID, men själva data kommer att finnas kvar i ett enda logiskt block, tabellen. Av denna anledning kan du inte skapa två klustrade index. Det kan bara finnas en tabell med samma data, och den tabellen kan bara sorteras en gång i en viss ordning.
Om en klustrad tabell ger många fördelar, varför använda en hög?
Du har rätt. Klustrade tabeller är olika och de flesta av dina frågor kommer att fungera bättre på tabeller som har ett klustrat index. Men i vissa fall kanske du vill lämna borden i naturligt tillstånd, dvs. som en hög, och skapa endast icke-klustrade index för att hålla dina frågor igång.Kom ihåg att högen lagrar data i slumpmässig ordning. Vanligtvis lägger lagringsundersystemet till data till en tabell i den ordning som det infogas, men lagringsundersystemet gillar också att flytta runt rader för effektivare lagring. Som ett resultat har du ingen chans att förutsäga i vilken ordning informationen kommer att lagras.
Om frågemotorn behöver hitta data utan fördelarna med ett icke-klustrat index, kommer den att göra en fullständig tabellskanning för att hitta de rader den behöver. På väldigt små bord är detta vanligtvis inget problem, men när högen växer i storlek sjunker prestandan snabbt. Naturligtvis kan ett icke-klustrat index hjälpa till genom att använda en pekare till filen, sidan och raden där den nödvändiga informationen lagras - vanligtvis mycket. bästa alternativet tabellskanning. Trots det är det svårt att jämföra med fördelarna med ett klustrat index när man överväger frågeprestanda.
Högen kan dock hjälpa till att förbättra prestandan i vissa situationer. Tänk på en tabell med många infogningar men få uppdateringar eller borttagningar. Till exempel används en loggtabell främst för att infoga värden tills den arkiveras. På en heap kommer du inte att se sidnumrering och datafragmentering som du skulle göra med ett klustrat index, eftersom raderna helt enkelt läggs till i slutet av högen. För mycket sidseparation kan ha en betydande inverkan på prestanda, och inte på bästa sätt. I allmänhet gör heapen att infoga data relativt smärtfritt och du behöver inte ta itu med lagrings- och underhållskostnaderna för ett klustrat index.
Men bristen på att uppdatera och radera data bör inte anses vara den enda anledningen. Sättet som data samplas är också en viktig faktor. Till exempel bör du inte använda en heap om du ofta frågar efter dataintervall, eller om den begärda informationen ofta behöver sorteras eller grupperas.
Allt detta betyder är att du bara bör överväga att använda heapen när du arbetar med extra små tabeller eller så är all din interaktion med tabellen begränsad till att infoga data och dina frågor är extremt enkla (och du använder fortfarande icke-klustrade index). Annars, håll dig till ett väldesignat klustrade index, till exempel ett som definieras i ett enkelt inkrementerande nyckelfält, som en mycket använd kolumn med IDENTITET.
Hur ändrar man standardvärdet för indexfyllningsfaktorn?
Att ändra standardindexfyllningsfaktorn är en sak. Att förstå hur standardförhållandet fungerar är en annan sak. Men först ett par steg tillbaka. Indexfyllningsfaktorn bestämmer mängden utrymme per sida för att lagra indexet på den lägsta nivån (bladnivån) innan du börjar fylla på. ny sida. Till exempel, om koefficienten är inställd på 90, när indexet växer, kommer det att uppta 90% på sidan, och sedan gå till nästa sida.Som standard räknas värdet på indexfyllningen in SQL Serverär 0, vilket är lika med 100. Som ett resultat kommer alla nya index automatiskt att ärva denna inställning, såvida du inte specifikt anger ett värde som skiljer sig från systemets standard i koden eller ändrar standardbeteendet. Du kan använda SQL Server Management Studio för att justera standardvärdet eller köra en systemlagrad procedur sp_configure. Till exempel följande uppsättning T-SQL kommando ställer in koefficientvärdet till 90 (du måste först växla till läget för avancerade inställningar):
EXEC sp_configure "visa avancerade alternativ", 1; GÅ ÅTERKONFIGURERA; GO EXEC sp_configure "fyllfaktor", 90; GÅ ÅTERKONFIGURERA; GÅ
Efter att ha ändrat värdet på indexfyllningsfaktorn måste du starta om tjänsten SQL Server. Du kan nu kontrollera det inställda värdet genom att köra sp_configure utan att det andra argumentet anges:
EXEC sp_configure "fyllfaktor" GO
Detta kommando bör returnera värdet 90. Som ett resultat kommer alla nyskapade index att använda detta värde. Du kan testa detta genom att skapa ett index och fråga efter fyllfaktorvärdet:
ANVÄND AdventureWorks2012; -- din databas GÅ SKAPA INKLUSTERAT INDEX ix_people_lastname ON Person.Person(LastName); GÅ VÄLJ fill_factor FRÅN sys.indexes WHERE object_id = object_id("Person.Person") OCH name="ix_people_lastname";
I detta exempel vi har skapat ett icke-klustrat index på tabellen person i databasen AdventureWorks 2012. Efter att ha skapat indexet kan vi få fyllningsfaktorvärdet från systemtabellerna sys.indexes. Begäran bör returnera 90.
Låt oss dock föreställa oss att vi tappade indexet och skapade det igen, men nu angav vi ett specifikt fyllfaktorvärde:
SKAPA INKLUSTERAT INDEX ix_people_efternamn PÅ Person.Person(Efternamn) MED (fillfactor=80); GÅ VÄLJ fill_factor FRÅN sys.indexes WHERE object_id = object_id("Person.Person") OCH name="ix_people_lastname";
Den här gången har vi lagt till instruktioner MED och alternativ fyllnadsfaktor för vårt indexskapande SKAPA INDEX och specificerade ett värde på 80. Operatör VÄLJ returnerar nu motsvarande värde.
Hittills har det gått ganska rakt fram. Där du verkligen kan bränna dig i hela processen är när du skapar ett index med standardfaktorvärdet, förutsatt att du känner till värdet. Till exempel, någon bråkar med serverinställningarna och är så envis att han sätter indexfyllningsfaktorvärdet till 20. Under tiden fortsätter du att skapa index, med antagandet att standardvärdet är 0. Tyvärr har du inget sätt att ta reda på koefficientvärdet förrän du skapar ett index, och sedan kontrollera värdet, som vi gjorde i våra exempel. Annars måste du vänta tills frågeprestandan sjunker så mycket att du börjar misstänka något.
Ett annat problem du bör vara medveten om är indexombyggnad. Som med indexskapande kan du ange indexets fyllningsfaktorvärde när du bygger om det. Men till skillnad från skapa index-kommandot använder rebuild inte standardserverinställningarna, även om det kan verka så. Ännu mer, om du inte specifikt anger ett indexfyllningsfaktorvärde, då SQL Server kommer att använda värdet på koefficienten som detta index fanns med innan det byggdes om. Till exempel följande operation ÄNDRA INDEX bygger om indexet vi just skapade:
ALTER INDEX ix_people_lastname ON Person.Person REBUILD; GÅ VÄLJ fill_factor FRÅN sys.indexes WHERE object_id = object_id("Person.Person") OCH name="ix_people_lastname";
När vi kontrollerar fyllfaktorvärdet får vi ett värde på 80, eftersom det var vad vi angav när vi senast skapade indexet. Standardvärdet ignoreras.
Som du kan se är det inte så svårt att ändra värdet på indexfyllningsfaktorn. Mycket svårare att veta nuvarande värde och förstå när det gäller. Om du alltid anger ett specifikt förhållande när du skapar och bygger om index, vet du alltid det specifika resultatet. Såvida du inte måste se till att någon annan inte förstör serverinställningarna igen, vilket gör att alla index byggs om med en löjligt låg indexfyllningsfaktor.
Är det möjligt att skapa ett klustrat index på en kolumn som innehåller dubbletter?
Ja och nej. Ja, du kan skapa ett klustrat index på en nyckelkolumn som innehåller dubbletter av värden. Nej, värdet på en nyckelkolumn kan inte förbli i ett icke-unikt tillstånd. Låt mig förklara. Om du skapar ett icke-unikt klustrat index på en kolumn, lägger lagringsundersystemet till ett heltalsvärde (uniquifier) till dubblettvärdet för att säkerställa unikhet och följaktligen för att säkerställa att varje rad i den klustrade tabellen kan identifieras.Till exempel kan du välja att skapa ett klustrat index i kunddatatabellen i kolumnen efternamn med efternamnet. Kolumnen innehåller värden som Franklin, Hancock, Washington och Smith. Du klistrar sedan in värdena Adams, Hancock, Smith och Smith igen. Men värdet på nyckelkolumnen måste vara unikt, så lagringsundersystemet kommer att ändra värdet på duplikaten så att de ser ut ungefär så här: Adams, Franklin, Hancock, Hancock1234, Washington, Smith, Smith4567 och Smith5678.
Vid första anblicken verkar detta tillvägagångssätt vara normalt, men ett heltalsvärde ökar nyckelns storlek, vilket kan bli ett problem med ett stort antal dubbletter, och dessa värden kommer att bli grunden för ett icke-klustrat index eller referens främmande nyckel. Av dessa skäl bör du alltid försöka skapa unika klustrade index när det är möjligt. Om detta inte är möjligt, försök åtminstone använda kolumner med ett mycket högt innehåll av unika värden.
Hur lagras tabellen om inget klustrat index har skapats?
SQL Server stöder två typer av tabeller: klustrade tabeller som har ett klustrat index, och heaptabeller eller bara heaps. Till skillnad från klustrade tabeller sorteras inte data i högen på något sätt. I själva verket är detta en hög (hög) av data. Om du lägger till en rad i en sådan tabell kommer lagringsundersystemet helt enkelt att lägga till den i slutet av sidan. När sidan är fylld med data läggs den till på den nya sidan. I de flesta fall vill du skapa ett klustrat index på en tabell för att dra fördel av sorterings- och frågehastighet (försök att föreställa dig att hitta telefonnummer V adressbok, inte sorterad efter någon princip). Men om du väljer att inte skapa ett klustrat index, kan du fortfarande skapa ett icke-klustrat index på högen. I det här fallet kommer varje indexrad att ha en pekare till en högrad. Indexet inkluderar fil-ID, sidnummer och dataradnummer.Vad är förhållandet mellan unika värdebegränsningar och primärnyckel med tabellindex?
En primärnyckel och en unik begränsning säkerställer att värdena i en kolumn är unika. Du kan bara skapa en primärnyckel per tabell och den kan inte innehålla värden. NULL. Du kan skapa flera begränsningar för det unika värdet av en tabell, och var och en av dem kan ha en enda post med NULL.När du skapar en primärnyckel skapar lagringsundersystemet också ett unikt klustrat index om inget klustrat index redan har skapats. Du kan dock åsidosätta standardbeteendet och sedan skapas ett icke-klustrat index. Om ett klustrat index finns när du skapar den primära nyckeln, kommer ett unikt icke-klustrat index att skapas.
När du skapar en unik begränsning skapar lagringsmotorn ett unikt icke-klustrat index. Du kan dock välja att skapa ett unikt klustrat index om det inte redan har skapats.
I allmänhet är en unik värderestriktion och ett unikt index samma sak.
Varför kallas klustrade och icke-klustrade index B-Tree i SQL Server?
Grundläggande index i SQL Server, oavsett om de är klustrade eller icke-klustrade, är spridda över uppsättningar av sidor som kallas indexnoder. Dessa sidor är organiserade i en specifik hierarki med en trädstruktur som kallas ett balanserat träd. På högsta nivånär rotnoden, på botten, lövnoder, med mellanliggande noder mellan topp- och bottennivån, som visas i figuren:Rotnoden utgör huvudingångspunkten för frågor som försöker hämta data genom ett index. Med utgångspunkt från denna nod initierar frågemotorn en hierarkisk genomgång ner till den lämpliga slutnoden som innehåller data.
Anta till exempel att det finns en begäran om att hämta rader som innehåller nyckelvärdet 82. Frågeundersystemet startar vid rotnoden, som pekar på en lämplig mellannod, i vårt fall 1-100. Från den mellanliggande noden 1-100 sker en övergång till noden 51-100 och därifrån till den slutliga noden 76-100. Om det är ett klustrat index, så innehåller nodens blad data för raden som är associerad med nyckeln lika med 82. Om det är ett icke-klustrat index, så innehåller indexbladet en pekare till en klustrad tabell eller en specifik rad i högen.
Hur i allmänhet kan ett index förbättra frågeprestanda om du måste gå igenom alla dessa indexnoder?
För det första förbättrar index inte alltid prestandan. För många felaktigt skapade index gör systemet till ett träsk och försämrar frågeprestanda. Det skulle vara mer korrekt att säga att om index tillämpas noggrant kan de ge betydande prestandavinster.Tänk på en enorm bok tillägnad prestandajustering SQL Server(papper, inte den elektroniska versionen). Föreställ dig att du vill hitta information om hur du konfigurerar resursregulatorn. Du kan flytta ditt finger sida för sida genom hela boken, eller öppna innehållsförteckningen och ta reda på det exakta sidnumret för informationen du letar efter (förutsatt att boken är korrekt indexerad och innehållsförteckningen har rätt register). Detta kommer naturligtvis att spara mycket tid för dig, trots att du först måste hänvisa till en helt annan struktur (index) för att få den information du behöver från den primära strukturen (boken).
Liksom bokregistret, indexet in SQL Server låter dig utföra exakta frågor till önskad data istället för en fullständig genomsökning av alla data som finns i tabellen. För små tabeller är en fullständig genomsökning vanligtvis inte ett problem, men stora tabeller tar upp många sidor med data, vilket kan resultera i avsevärda exekveringstider för frågor om det inte finns något index på plats för att tillåta frågemotorn att omedelbart få rätt dataplats. Föreställ dig att du går vilse på en vägkorsning på flera nivåer framför en stor metropol utan karta och du kommer att få idén.
Om index är så bra, varför inte bara skapa dem på varje kolumn?
Ingen god gärning ska förbli ostraffad. Åtminstone är det fallet med index. Självklart är index bra så länge du gör hämtningsfrågor med operatören VÄLJ, men så snart det frekventa samtalet av operatörer FÖRA IN, UPPDATERING Och RADERA så landskapet förändras väldigt snabbt.När du initierar en dataförfrågan från en operatör VÄLJ, hittar frågemotorn indexet, rör sig genom dess trädstruktur och hittar de data som den letar efter. Vad kan vara lättare? Men saker och ting förändras om man utfärdar ett förändringsmeddelande som t.ex UPPDATERING. Ja, för den första delen av uttalandet kan frågemotorn återigen använda indexet för att hitta raden som ändras - det är goda nyheter. Och om det finns en enkel dataändring i en rad som inte påverkar ändringen i nyckelkolumner, kommer ändringsprocessen att vara helt smärtfri. Men vad händer om ändringen resulterar i en uppdelning av sidor som innehåller data, eller om värdet på en nyckelkolumn ändras, vilket gör att den flyttas till en annan indexnod - detta kommer att leda till att indexet kan behöva omorganiseras, vilket påverkar alla associerade index och operationer, som ett resultat kommer det att bli en omfattande prestandaförsämring.
Liknande processer inträffar när man ringer operatören RADERA. Indexet kan hjälpa till att lokalisera data som raderas, men raderingen av själva data kan leda till sidbyte. Angående operatören FÖRA IN, huvudfienden till alla index: du börjar lägga till mycket data, vilket leder till att index ändras och omorganiseras, och alla lider.
Så överväg vilka typer av frågor som gäller din databas när du överväger vilken typ av index och hur många du ska skapa. Mer betyder inte bättre. Innan du lägger till ett nytt index i en tabell, överväg inte bara kostnaden för grundläggande frågor, utan även kostnaden för diskutrymme, underhållskostnader och index, vilket kan leda till en dominoeffekt för andra operationer. Din strategi för indexdesign är en av de viktigaste aspekterna av din implementering och bör inkludera många överväganden, från storleken på indexet, antalet unika värden, till den typ av frågor som stöds av indexet.
Är det nödvändigt att skapa ett klustrat index på en primärnyckelkolumn?
Du kan skapa ett klustrat index på valfri kolumn som uppfyller de villkor som krävs. Det är sant att ett klustrat index och en primärnyckelbegränsning är gjorda för varandra och deras äktenskap görs i himlen, så omfamna det faktum att när du skapar en primärnyckel kommer ett klustrat index automatiskt att skapas vid den tidpunkten om det inte redan har skapats. Du kan dock bestämma dig för att ett klustrat index skulle fungera bättre någon annanstans, och ofta kommer ditt beslut att vara motiverat.Huvudsyftet med ett klustrat index är att sortera alla rader i din tabell baserat på nyckelkolumnen som angavs när indexet definierades. Detta ger snabbsökning Och lätt tillgång att tabellera data.
En tabells primärnyckel kan vara ett bra val eftersom den unikt identifierar varje rad i tabellen utan att behöva lägga till extra data. I vissa fall det bästa valet det kommer att finnas en surrogatprimärnyckel som inte bara är unik, utan också liten i storlek, och vars värden ökar sekventiellt, vilket gör icke-klustrade index baserade på detta värde mer effektiva. Frågeoptimeraren gillar också den här kombinationen av ett klustrat index och en primärnyckel eftersom det går snabbare att sammanfoga tabeller än att gå med på något annat sätt som inte använder primärnyckeln och det tillhörande klustrade indexet. Som jag sa, detta är ett äktenskap gjort i himlen.
I slutändan är det dock värt att notera att när man skapar ett klustrat index måste flera aspekter beaktas: hur många icke-klustrade index som kommer att baseras på det, hur ofta värdet på indexnyckelkolumnen kommer att ändras och hur stort. När värdet i kolumnerna i ett klustrat index ändras eller indexet inte fungerar som förväntat, kan alla andra index i tabellen påverkas. Ett klustrat index bör baseras på den mest stabila kolumnen, vars värden ökar i en viss ordning, men inte ändras slumpmässigt. Indexet måste stödja frågor om tabellens mest använda data, så frågor drar full nytta av att ha data sorterad och tillgänglig vid rotnoderna, indexets blad. Om den primära nyckeln passar detta scenario, använd den. Om inte, välj en annan uppsättning kolumner.
Men vad händer om du indexerar en vy, kommer den fortfarande att vara en vy?
Presentation är virtuellt bord En som genererar data från en eller flera tabeller. Det är i huvudsak en namngiven fråga som hämtar data från de underliggande tabellerna när du frågar den vyn. Du kan förbättra frågeprestanda genom att skapa ett klustrat index och icke-klustrade index i den här vyn, liknande hur du skapar index på en tabell, men huvudförbehållet är att du först skapar ett klustrat index och sedan kan du skapa ett icke-klustrat.När en indexerad vy (materialiserad vy) skapas, förblir själva vydefinitionen en separat enhet. Det är trots allt bara ett hårt kodat uttalande VÄLJ Den lagras i databasen. Men indexet är en helt annan historia. När du skapar ett klustrat eller icke-klustrat index på en vy, lagras data fysiskt på disken, precis som ett vanligt index. Dessutom, när data ändras i de underliggande tabellerna, ändras indexet för vyn automatiskt (vilket innebär att du kanske vill undvika att indexera vyerna för tabeller som ändras ofta). Vyn förblir i alla fall en vy - en titt på tabellerna, men bara gjort in det här ögonblicket, med index som motsvarar det.
Innan du kan skapa ett index på en vy måste den uppfylla några begränsningar. Till exempel kan en vy bara referera till bastabeller, inte andra vyer, och dessa tabeller måste finnas i samma databas. Faktum är att det finns många andra begränsningar, så se till att hänvisa till dokumentationen för SQL Server för alla smutsiga detaljer.
Varför använda ett täckande index istället för ett sammansatt index?
Låt oss först se till att vi förstår skillnaden mellan dem. Ett sammansatt index är bara ett normalt index som innehåller mer än en kolumn. Flera nyckelkolumner kan användas för att säkerställa att varje tabellrad är unik, det är också möjligt att primärnyckeln består av flera kolumner för att säkerställa dess unikhet, eller så försöker du optimera exekveringen av ofta anropade frågor på flera kolumner. I allmänhet gäller dock att ju fler nyckelkolumner ett index innehåller, desto mindre effektivt är indexet, och därför bör sammansatta index användas med omtanke.Som sagt kan en fråga skörda enorma fördelar om all nödvändig data omedelbart finns på bladen av indexet, precis som själva indexet. Detta är inte ett problem för ett klustrat index, som all data finns redan där (det är därför det är så viktigt att tänka noga när du skapar ett klustrat index). Men det icke-klustrade indexet på bladen innehåller bara nyckelkolumnerna. Frågeoptimeraren behöver ytterligare steg för att komma åt all annan data, vilket kan orsaka betydande extra kostnader för att köra dina frågor.
Det är här det täckande indexet kommer till undsättning. När du definierar ett icke-klustrat index kan du ange ytterligare kolumner utöver dina nyckel. Låt oss till exempel säga att din applikation ofta begär kolumndata. OrderID Och Orderdatum i bordet Försäljning:
VÄLJ OrderID, OrderDate FROM Sales WHERE OrderID = 12345;
Du kan skapa ett sammansatt icke-klustrat index på båda kolumnerna, men OrderDate-kolumnen kommer bara att läggas till omkostnaderna för att underhålla indexet och kommer inte att fungera som en särskilt användbar nyckelkolumn. Den bästa lösningen skulle vara att skapa ett täckande index med en nyckelkolumn OrderID och en ytterligare inkluderad kolumn Orderdatum:
CREATE ECKLUSTERED INDEX ix_orderid ON dbo.Sales(OrderID) INCLUDE(OrderDate);
Genom att göra det slipper du nackdelarna med att indexera redundanta kolumner samtidigt som du behåller fördelarna med att lagra data på bladen när du kör frågor. Den inkluderade kolumnen är inte en del av nyckeln, utan data lagras exakt på slutnoden, indexbladet. Detta kan förbättra frågeprestanda utan extra kostnad. Dessutom finns det färre begränsningar för kolumner som ingår i ett täckande index än för nyckelkolumner i ett index.
Spelar antalet dubbletter i en nyckelkolumn någon roll?
När du skapar ett index måste du försöka minska antalet dubbletter i dina nyckelkolumner. Eller mer exakt: försök att hålla dubblettvärdet så lågt som möjligt.Om du arbetar med ett sammansatt index gäller dubbleringen för alla nyckelkolumner som helhet. En enskild kolumn kan innehålla många dubbletter av värden, men upprepning mellan alla kolumner i ett index bör hållas till ett minimum. Till exempel skapar du ett sammansatt icke-klustrat index på kolumner Förnamn Och efternamn, du kan ha många John Doe och många gör, men du vill ha så få John Doe som möjligt, eller ännu bättre bara en John Doe.
Unikitetskoefficienten för värdena i nyckelkolumnen kallas indexets selektivitet. Ju fler unika värden, desto högre selektivitet: ett unikt index har högsta möjliga selektivitet. Frågemotorn är mycket förtjust i kolumner med ett högt selektivitetsvärde, särskilt om dessa kolumner finns i WHERE-satserna i dina vanligast körda frågor. Ju högre indexselektivitet, desto snabbare kan frågemotorn minska storleken på den resulterande datamängden. Nackdelen är förstås att kolumner med relativt få unika värden sällan är bra kandidater för indexering.
Är det möjligt att skapa ett icke-klustrat index på endast en specifik delmängd av en nyckelkolumns data?
Som standard innehåller ett icke-klustrat index en rad för varje tabellrad. Naturligtvis kan du säga detsamma om ett klustrat index, med tanke på att indexet är tabellen. Men när det gäller det icke-klustrade indexet är en-till-en-relationen ett viktigt begrepp, eftersom, sedan version SQL Server 2008, har du möjlighet att skapa ett filtrerbart index som begränsar raderna som ingår i det. Ett filtrerat index kan förbättra frågeprestanda eftersom den är mindre och innehåller filtrerad, mer exakt statistik än alla i tabellform - detta resulterar i bättre genomförandeplaner. Ett filtrerat index kräver också mindre lagringsutrymme och lägre underhållskostnader. Indexet uppdateras endast när data som matchar filtret ändras.Dessutom är ett filtrerbart index lätt att skapa. I operatör SKAPA INDEX du behöver bara specificera VAR filtreringsvillkor. Till exempel kan du filtrera bort alla rader som innehåller NULL från indexet, som visas i koden:
SKAPA INKLUSTERAT INDEX ix_trackingnumber ON Sales.SalesOrderDetail(CarrierTrackingNumber) WHERE CarrierTrackingNumber INTE ÄR NULL;
Vi kan faktiskt filtrera bort all data som inte är viktig i kritiska frågor. Men var försiktig, för. SQL Server inför flera begränsningar för filtrerbara index, till exempel oförmågan att skapa ett filtrerbart index på en vy, så läs dokumentationen noggrant.
Det kan också hända att du kan uppnå liknande resultat genom att skapa en indexerad vy. Ett filtrerat index har dock flera fördelar, såsom möjligheten att minska underhållskostnaderna och förbättra kvaliteten på dina genomförandeplaner. Filtrerade index kan också byggas om online. Prova med en indexerad vy.
Och återigen lite från översättaren
Syftet med uppkomsten av denna översättning på Habrahabrs sidor var att berätta eller påminna dig om SimpleTalk-bloggen från redgate.
Den publicerar många underhållande och intressanta bidrag.
Jag är inte ansluten till företagets produkter redgate, inte heller med deras försäljning.
Som utlovat, böcker för den som vill veta mer
Jag kommer att rekommendera tre mycket bra böcker från mig själv (länkar leder till tända versioner i butiken Amazon):
 |
Microsoft SQL Server 2012 T-SQL Fundamentals (referens för utvecklare) Författare Itzik Ben-Gan Publiceringsdatum: 15 juli 2012 Författaren, en mästare på sitt hantverk, ger grundläggande kunskaper om att arbeta med databaser. Om du glömt allt eller aldrig visste, så är det definitivt värt att läsa. | I princip kan du öppna enkla index
I detta material databasobjekt kommer att beaktas Microsoft SQL Server Hur index, Du kommer att lära dig vad index är, vilka typer av index är, hur man skapar, optimerar och tar bort dem.
Vad är index i en databas?
Indexär ett databasobjekt som är en datastruktur som består av nycklar baserade på en eller flera kolumner i en tabell eller vy och pekare som mappar till platsen där den givna datan är lagrad. Index är utformade för att snabbare hämta rader från en tabell, med andra ord ger index snabba uppslagningar av data i en tabell, vilket avsevärt förbättrar fråge- och applikationsprestanda. Index kan också användas för att säkerställa unika rader i en tabell, och därigenom garantera dataintegritet.
Indextyper i Microsoft SQL Server
Följande typer av index finns i Microsoft SQL Server:
- klustrade (klustrade) är ett index som lagrar tabelldata sorterad efter indexnyckelns värde. En tabell kan bara ha ett klustrat index eftersom data bara kan sorteras i en ordning. När det är möjligt bör varje tabell ha ett klustrat index, om en tabell inte har ett klustrat index kallas en sådan tabell " knippa". Ett klustrat index skapas automatiskt när man skapar PRIMÄRNYCKEL-begränsningar ( primärnyckel) och UNIQUE om det klustrade indexet i tabellen ännu inte har definierats. I fallet med att skapa ett klustrat index på en tabell ( högar) som har icke-klustrade index, måste alla byggas om efter skapandet.
- icke-klustrade (icke-klustrade) är ett index som innehåller nyckelns värde och en pekare till datasträngen som innehåller nyckelns värde. En tabell kan ha flera icke-klustrade index. Icke-klustrade index kan skapas på tabeller med eller utan ett klustrat index. Det är den här typen av index som används för att förbättra prestandan för ofta använda frågor, eftersom icke-klustrade index ger snabb uppslagning och tillgång till data genom nyckelvärden;
- filtrerbar (filtreras) är ett optimerat icke-klustrat index som använder ett filterpredikat för att indexera en del av raderna i en tabell. Om den är väl utformad kan den här typen av index förbättra frågeprestandan och minska indexunderhålls- och lagringskostnaderna jämfört med index med fullständiga tabeller;
- Unik (Unik) är ett index som säkerställer att det inte finns några dubbletter ( identisk) indexera nyckelvärden, vilket garanterar radernas unika karaktär med given nyckel. Både klustrade och icke-klustrade index kan vara unika. Om du skapar ett unikt index på flera kolumner, garanterar indexet att varje kombination av värden i nyckeln är unik. När du skapar PRIMÄRKEY eller UNIKA begränsningar skapar SQL Server automatiskt ett unikt index på nyckelkolumner. Ett unikt index kan bara skapas om tabellen för närvarande inte har några dubbletter av värden för nyckelkolumner;
- pelar- (kolumnbutik) är ett index baserat på kolumnär datalagringsteknik. Den här typen Ett index är effektivt för stora datalager eftersom det kan öka prestandan för lagringsfrågor med upp till 10 gånger och även minska datastorleken med upp till 10 gånger, eftersom data i Columnstore-indexet komprimeras. Det finns både klustrade kolumnära index och icke-klustrade;
- Full text (Full text) är en speciell typ av index som ger effektivt stöd för komplexa orduppslagningar på teckensträngsdata. Processen att skapa och underhålla ett fulltextindex kallas " fyllning". Det finns sådana typer av fyllning som: full fyllning och fyllning baserad på förändringsspårning. Som standard fyller SQL Server helt i ett nytt fulltextindex så snart det skapas, men detta kan vara ganska resurskrävande beroende på tabellens storlek, så det är möjligt att fördröja hela populationen. Ändringsspårningssådd används för att upprätthålla ett fulltextindex efter att det initialt har fyllts i fullt;
- Rumslig (Rumslig) är ett index som möjliggör mer effektiv användning av specifika operationer på funktioner på kolumner med en geometri- eller geografidatatyp. Den här typen av index kan bara skapas på en rumslig kolumn, och tabellen för vilken ett rumsligt index är definierat måste innehålla en primärnyckel ( PRIMÄRNYCKEL);
- XMLär en annan speciell typ av index som är designad för kolumner med typ XML-data. XML-indexet förbättrar effektiviteten i fråga om XML-kolumner. Det finns två typer av XML-index: primärt och sekundärt. Det primära XML-indexet indexerar alla taggar, värden och sökvägar som lagras i XML-kolumnen. Den kan bara skapas om tabellen har ett klustrat index på primärnyckeln. Ett sekundärt XML-index kan bara skapas om tabellen har ett primärt XML-index och används för att förbättra frågeprestanda på en viss typ av XML-kolumnåtkomst, så det finns flera typer av sekundära index: PATH, VALUE och PROPERTY;
- Det finns även speciella index för minnesoptimerade tabeller ( In-Memory OLTP) såsom: Hash ( Hash) index och minnesoptimerade icke-klustrade index som skapas för intervallskanningar och ordnade skanningar.
Skapa och släppa index i Microsoft SQL Server
Innan du börjar skapa ett index måste det vara väl utformat för att effektivt kunna använda detta index, eftersom dåligt utformade index inte kan öka prestandan, utan snarare minska den. Till exempel minskar ett stort antal index i en tabell prestandan för INSERT-, UPDATE-, DELETE- och MERGE-satser eftersom när data i tabellen ändras måste alla index ändras i enlighet med detta. Allmänna rekommendationer vi kommer att överväga indexdesign i en separat artikel, men låt oss nu gå vidare till processen att skapa och ta bort index.
Notera! Min SQL-server är Microsoft SQL Server 2016 Express.
Skapa index
För att skapa index i Microsoft SQL Server finns det två sätt: det första är att använda det grafiska gränssnittet i SQL Server Management Studio-miljön (SSMS), och det andra är att använda Transact-SQL-språket, vi kommer att analysera båda metoderna.
Initial data för exempel
Låt oss föreställa oss att vi har en produkttabell som heter TestTable som har tre kolumner:
- ProductId - produktidentifierare;
- Produktnamn - produktnamn;
- CategoryID - produktkategori.
Exempel på att skapa ett klustrat index
Som sagt skapas ett klustrat index automatiskt om vi till exempel när vi skapar en tabell anger en specifik kolumn som primärnyckel ( PRIMÄRNYCKEL), men eftersom vi inte gjorde det, låt oss titta på ett exempel på hur du skapar ett klustrat index själv.
För att skapa ett klustrat index kan vi ange en primärnyckel för en tabell, och därmed skapas ett klustrat index automatiskt, eller så kan vi skapa ett klustrat index separat.
Låt oss till exempel bara skapa ett klustrat index utan att skapa en primärnyckel. Låt oss göra det först med Förvaltning studio.
Öppna SSMS och i objektutforskaren hitta önskad tabell och högerklicka på objektet " Index", välj " Skapa index" och indextyp, i vårt fall " klustrade».

Formuläret öppnas Nytt index”, där vi måste ange namnet på det nya indexet ( den måste vara unik i tabellen), anger vi också om detta index kommer att vara unikt, om vi pratar om produktidentifieraren i produkttabellen så måste det naturligtvis vara unikt. Välj sedan kolumnen indexnyckel), på grundval av vilket vi kommer att skapa ett klustrat index, dvs. rader med data i tabellen kommer att sorteras med knappen " Lägg till».

När du har angett alla nödvändiga parametrar klickar du på " OK”, som ett resultat kommer ett klustrat index att skapas.

På liknande sätt skulle man kunna skapa ett klustrat index med hjälp av T-SQL uttalande SKAPARINDEX till exempel så här
SKAPA UNIKT CLUSTERED INDEX IX_Clustered ON TestTable (ProductId ASC) GO
Eller, som vi redan har sagt, man kan också använda instruktionen för att skapa en primärnyckel, till exempel
ALTER TABLE TestTable ADD CONSTRAINT PK_TestTable PRIMARY KEY CLUSTERED (ProductId ASC) GO
Exempel på att skapa ett icke-klustrat index med inkluderade kolumner
Låt oss nu titta på ett exempel på att skapa ett icke-klustrat index, medan vi anger kolumnerna som inte kommer att vara nyckeln, utan kommer att ingå i indexet. Detta är användbart när du skapar ett index för specifik begäran, till exempel för att indexet helt ska täcka frågan, dvs. innehöll alla kolumner ( detta kallas "Request Coverage"). Frågetäckning förbättrar prestandan eftersom frågeoptimeraren kan hitta alla kolumnvärden i ett index utan att behöva komma åt tabelldata, vilket resulterar i färre disk I/O. Men tänk på att inkludering av icke-nyckelkolumner i ett index resulterar i en ökning av indexets storlek, d.v.s. indexlagring kommer att kräva mer diskutrymme och kan också resultera i prestandaförsämring för operationerna INSERT, UPDATE, DELETE och MERGE på bastabellen.
För att skapa ett icke-klustrat index med det grafiska gränssnittet i Management Studio, hittar vi också önskat tabell- och indexobjekt, bara i det här fallet väljer vi " Skapa -> Nonclustered Index».

Efter att ha öppnat formuläret Nytt index» vi anger namnet på indexet, lägger till en nyckelkolumn eller kolumner med knappen « Lägg till”, till exempel, för vårt testfall, låt oss specificera CategoryID.

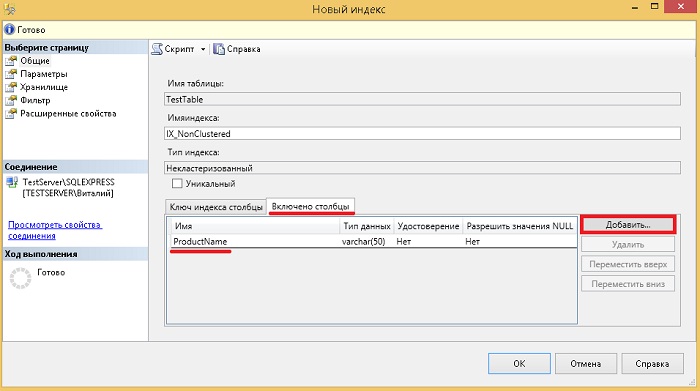
I Transact-SQL skulle det se ut så här.
SKAPA INKLUSTERAD INDEX IX_NonClustered ON TestTable (CategoryID ASC) INCLUDE (ProductName) GO
Ett exempel på att ta bort ett index i Microsoft SQL Server
För att ta bort ett index, högerklicka på önskat index och klicka på " Radera", bekräfta sedan din åtgärd genom att trycka på " OK».

eller så kan du också använda uttalandet SLIPP INDEX, Till exempel
DROP INDEX IX_NonClustered ON TestTable
Observera att DROP INDEX-satsen inte gäller för index som skapades genom att skapa PRIMARY KEY och UNIQUE-begränsningar. I det här fallet måste du använda ALTER TABLE-satsen med satsen DROP CONSTRAINT för att ta bort indexet.
Optimera index i Microsoft SQL Server
Som ett resultat av att uppdatera, lägga till eller ta bort data i tabeller gör SQL Server automatiskt lämpliga ändringar av index, men med tiden kan alla dessa ändringar orsaka datafragmentering i indexet, d.v.s. de kommer att vara utspridda i databasen. Fragmentering av index innebär en minskning av frågeprestanda, därför är det periodiskt nödvändigt att utföra indexunderhållsoperationer, nämligen defragmentering, såsom indexomorganisering och återuppbyggnadsoperationer.
När ska man använda indexomorganisering och när ska man bygga om?
För att svara på denna fråga måste du först bestämma graden av indexfragmentering, eftersom beroende på fragmenteringen av indexet kommer en eller annan defragmenteringsmetod att vara att föredra och effektivare. För att avgöra hur fragmenterat ett index är kan du använda systemtabellfunktionen sys.dm_db_index_physical_stats En som returnerar detaljerad information om indexstorlek och fragmentering. Med hjälp av följande fråga kan du till exempel ta reda på graden av indexfragmentering för alla tabeller i den aktuella databasen.
VÄLJ OBJECT_NAME(T1.object_id) AS NameTable, T1.index_id AS IndexId, T2.name AS IndexName, T1.avg_fragmentation_in_percent AS Fragmentation FRÅN sys.dm_db_index_physical_stats (DB_ID(), NULL, NULL)NULL, NULL, T index T NULL, NULL. object_id = T2.object_id OCH T1.index_id = T2.index_id
I det här fallet är vi intresserade av kolumnen avg_fragmentation_in_percent, dvs. procentandel av logisk fragmentering.
- Om graden av fragmentering är mindre än 5 %, bör omorganisationen eller ombyggnaden av indexet inte köras alls;
- Om graden av fragmentering är från 5 till 30%, är det vettigt att genomföra en indexomorganisation, eftersom denna operation använder minimala systemresurser och kräver inte långtidslåsning;
- Om graden av fragmentering är mer än 30%, är det nödvändigt att bygga om indexet, eftersom denna operation, med betydande fragmentering, har en större effekt än indexomorganiseringsoperationen.
Själv kan jag lägga till följande om du har ett litet företag och databasen inte kräver maximal effektivitet i 24/7-läge, d.v.s. Eftersom det inte är en superaktiv databas kan du på ett säkert sätt utföra en återuppbyggnad av indexet regelbundet utan att ens bestämma graden av fragmentering.
Indexomläggning
Indexomläggningär en indexdefragmenteringsprocess som defragmenterar bladnivån för klustrade och icke-klustrade index på tabeller och vyer, och fysiskt omordnar bladnivåsidorna enligt den logiska ordningen ( från vänster till höger) slutnoder.
Du kan använda antingen ett grafiskt SSMS-verktyg eller en Transact-SQL-sats för att omorganisera ett index.
Omorganisera ett index med Management Studio

Indexomorganisation med Transact-SQL
ALTER INDEX IX_NonClustered ON TestTable OMORGANISERA GO
Återuppbygga index
Index ombyggnadär den process genom vilken det gamla indexet släpps och ett nytt skapas, vilket resulterar i eliminering av fragmentering.
Det finns två sätt att bygga om index.
Först. Genom att använda ALTER INDEX-satsen med REBUILD-satsen. Denna sats ersätter DBCC DBREINDEX-satsen. Detta är vanligtvis metoden som används för bulkindexombyggnader.
Exempel
ALTER INDEX IX_NonClustered ON TestTable REBUILD GO
Och den andra, med CREATE INDEX-satsen med DROP_EXISTING-satsen. Det kan till exempel användas för att bygga om ett index med ändrad definition, d.v.s. lägga till eller ta bort nyckelkolumner.
Exempel
SKAPA INKLUSTERAT INDEX IX_NonClustered ON TestTable (CategoryID ASC) WITH(DROP_EXISTING = ON) GO
Ombyggnadsfunktioner finns också i Management Studio. Högerklicka vid önskat index Återuppbygga».

Detta avslutar materialet om grunderna för index i Microsoft SQL Server, om du är intresserad T-SQL-språk Jag rekommenderar att läsa min bok