znakové funkcie sql. O funkciách reťazcov SQL alebo o tom, ako manipulovať s textom v databáze MySQL
Prečítajte si tiež
Tu je úplný zoznam funkcií reťazca prevzatých z BOL:
| ASCII | NCHAR | SOUNDEX |
| CHAR | PATINDEX | PRIESTOR |
| CHARINDEX | NAHRADIŤ | STR |
| ROZDIEL | QUOTENAME | VECI |
| LEFT | REPLICATE (replikovať). | SUBSTRING |
| LEN | REVERSE | UNICODE |
| NIŽŠIE | SPRÁVNY | HORNÝ |
| LTRIM | RTRIM |
Začnime dvoma vzájomne inverznými funkciami - ASCII A CHAR.
Funkcia ASCII vráti kód ASCII znaku úplne vľavo v reťazcovom výraze, ktorý je argumentom funkcie.
Tu je napríklad, ako môžete určiť, koľko rôznych písmen začína názvy lodí v tabuľke Lode:
Treba poznamenať, že podobný výsledok možno ľahšie získať pomocou inej funkcie - LEFT, ktorý má nasledujúcu syntax:
VĽAVO (<reťazcový výraz>, <celočíselný výraz>)
a odreže počet znakov zľava určený druhým argumentom z reťazca, ktorý je prvým argumentom. takže,
| VYBERTE DISTINCT LEFT(meno, 1) Z lodí OBJEDNAŤ DO 1 |
Takto môžete napríklad získať tabuľku kódov pre všetky abecedné znaky:
| SELECT CHAR(ASCII("a")+ číslo-1) písmeno, ASCII("a")+ číslo -1 OD (VYBERTE 5*5*(a-1)+5*(b-1) + c AS num FROM (VYBERTE 1 a UNION ALL VYBERTE 2 UNION ALL VYBERTE 3 UNION ALL VYBERTE 4 UNION ALL VYBERTE 5) x KRÍŽOVÉ PRIPOJENIE (VYBRAŤ 1 b UNION ALL VYBRAŤ 2 UNION ALL VYBRAŤ 3 UNION ALL VYBRAŤ 4 UNION ALL VYBRAŤ 5) y KRÍŽOVÉ PRIPOJENIE Z )X WHERE ASCII("a")+ číslo -1 MEDZI ASCII("a") A ASCII("z") |
Pre tých, ktorí ešte nevedia o generovaní číselnej postupnosti, odkazujem na príslušný článok.
Ako viete, kódy pre malé a veľké písmená sa líšia. Preto, aby ste získali celú sadu bez prepisovania požiadavky, stačí pridať podobnú do vyššie uvedeného kódu:
Myslím, že by nebolo príliš ťažké pridať tento list do tabuľky, ak to bude potrebné.
Uvažujme teraz o úlohe určiť, kde nájsť požadovaný podreťazec v reťazcovom výraze. Na to možno použiť dve funkcie - CHARINDEX A PATINDEX. Obe vrátia počiatočnú pozíciu (pozícia prvého znaku podreťazca) podreťazca v reťazci. Funkcia CHARINDEX má syntax:
CHARINDEX( vyhľadávací_výraz, reťazcový_výraz[, počiatočná_pozícia])
Tu je voliteľný celočíselný parameter počiatočná_pozícia definuje pozíciu v reťazcovom výraze, z ktorej sa vyhľadávanie vykonáva vyhľadávací_výraz. Ak je tento parameter vynechaný, vyhľadávanie sa vykonáva od začiatku reťazcový_výraz. Napríklad žiadosť
Treba si uvedomiť, že ak je hľadaný podreťazec alebo reťazcový výraz NULL, tak aj výsledok funkcie bude NULL.
Nasledujúci príklad určuje polohu prvého a druhého výskytu znaku „a“ v názve lode „California“
| SELECT CHARINDEX("a",meno) prvy_a, CHARINDEX("a", meno, CHARINDEX("a", meno)+1) druhý_a FROM Ships WHERE name="Kalifornia" |
Upozorňujeme, že pri definovaní druhého znaku vo funkcii sa používa počiatočná pozícia, čo je pozícia znaku za prvým písmenom "a" - CHARINDEX("a", meno)+1. Správnosť výsledku - 2 a 10 - si ľahko overíte :-).
Funkcia PATINDEX má syntax:
PATINDEX("% vzorka%" , reťazcový_výraz)
Hlavný rozdiel medzi touto funkciou a CHARINDEX je v tom, že hľadaný reťazec môže obsahovať zástupné znaky- % a _. V tomto prípade sú koncové znaky "%" povinné. Napríklad použitie tejto funkcie v prvom príklade by vyzeralo takto
Výsledok tohto dotazu vyzerá takto:
Skutočnosť, že skončíme s prázdnou množinou výsledkov, znamená, že v databáze nie sú žiadne takéto lode. Zoberme si kombináciu hodnôt - triedu a názov lode.
Spojenie dvoch hodnôt reťazca do jednej sa nazýva zreťazenie, a v SQL Server pre túto operáciu sa používa znamienko "+" (v štandarde "||"). takže,
Čo ak reťazcový výraz obsahuje iba jedno písmeno? Dotaz to vyvolá. Môžete si to ľahko overiť písaním
Pokračujeme v štúdiu jazyka SQL dotazy, a dnes budeme hovoriť o Funkcie reťazca SQL. Pozrieme sa na základné a bežne používané funkcie reťazca, ako napríklad: ZNÍŽIŤ, LTRIM, VYMENIŤ a ďalšie, všetko zvážime, samozrejme, na príkladoch.
VYBERTE meno || priezvisko AKO FIO Z tabuľky
Alebo ak chcete oddeliť medzerou, zadajte
VYBERTE meno || " " || priezvisko AKO FIO Z tabuľkytie. dva zvislé pruhy spájajú dva stĺpce do jedného a aby som ich oddelil medzerou, vložil som medzi ne medzeru ( Môžete použiť ľubovoľný znak, napríklad pomlčku alebo dvojbodku) v apostrofoch a tiež v kombinácii s dvoma zvislými čiarami ( Transact-SQL používa znak + namiesto dvoch zvislých čiar).
Funkcia INITCAP
To, čo nasleduje, je tiež veľmi užitočná funkcia, INITCAP– ktorý vráti hodnotu v reťazci, v ktorom každé slovo začína veľkým písmenom a pokračuje malými písmenami. Je to potrebné, ak nedodržiavate pravidlá vyplnenia v jednom alebo druhom stĺpci a aby sa celá záležitosť zobrazila nádherný výhľad túto funkciu môžete použiť napríklad vo svojich tabuľkových záznamoch v stĺpci názov nasledujúci typ: IVAN Ivanov alebo Petr Petrov, používate túto funkciu.
SELECT INITCAP (meno) AS FIO FROM tabuľky
A dostanete to takto.
Funkcia UPPER
Podobná funkcia, ale vráti všetky znaky s veľkým písmenom HORNÝ.
SELECT UPPER (name) AS FIO FROM table
- názov – názov stĺpca;
- 20 – počet znakov ( dĺžka poľa);
- „-“ je symbol, ktorý je potrebné doplniť na požadovaný počet znakov.
Funkcia RPAD
Pozrime sa hneď na inverznú funkciu. RPAD– akcia a syntax sú rovnaké ako LPAD, len znaky vpravo sú doplnené ( v LPAD vľavo).
VYBERTE RPAD (meno, 20, "-") AKO názov FROM tabuľky
| Ivan—————- |
| Sergey----- |
Funkcia LTRIM
Ďalej prichádza funkcia, ktorá je v niektorých prípadoch tiež užitočná, LTRIM– Táto funkcia odstráni znaky úplne vľavo, ktoré určíte. Napríklad máte v databáze stĺpec „mesto“, v ktorom je mesto označené ako „Moskva“ a existujú aj mestá, ktoré sú označené jednoducho ako „Moskva“. Musíte však zobraziť správu iba vo forme „Moskva“ bez „g.“, ale ako to urobiť, ak existujú také a také? Stačí zadať nejaký druh vzoru "g." a ak znaky úplne vľavo začínajú písmenom „g“, potom sa tieto znaky jednoducho nevypíšu.
SELECT LTRIM (mesto, "g.") AS mesto z tabuľky
Táto funkcia sa pozerá na znaky vľavo, ak vo vzore na začiatku riadku nie sú žiadne znaky, tak vráti pôvodnú hodnotu bunky a ak sú, vymaže ich.
Funkcia RTRIM
Tiež sa okamžite pozrime na inverznú funkciu. RTRIM– rovnako ako LTRIM, iba znaky sa hľadajú vpravo.
Poznámka! V Transact-SQL funkcie RTRIM a LTRIM odstraňujú medzery vpravo a vľavo.
Funkcia REPLACE
Teraz sa pozrime na toto zaujímavá vlastnosť Ako NAHRADIŤ– vráti reťazec, v ktorom sú všetky zodpovedajúce znaky nahradené vašimi znakmi, ktoré určíte. Prečo sa to dá použiť, máte napríklad v databáze stĺpce, ktoré obsahujú určité oddeľovacie znaky, napríklad „/“. Napríklad Ivan/Ivanov a chcete zobraziť Ivan-Ivanov, potom napíšte
VYBERTE REPLACE (názov, "/", "-") Z tabuľky
a budete mať náhradu postáv.
Táto funkcia nahrádza iba úplnú zhodu znakov, ak napríklad zadáte „—“, t.j. tri pomlčky bude hľadať iba tri pomlčky a nenahradí každú jednotlivú pomlčku, na rozdiel od nasledujúcej funkcie.
Funkcia TRANSLATE
PRELOŽIŤ– funkcia reťazca, ktorá nahrádza všetky znaky v reťazci znakmi, ktoré určíte. Podľa názvu funkcie môžete uhádnuť, že ide o kompletný riadkový posuv. Rozdiel medzi touto funkciou a REPLACE je v tom, že nahrádza každý znak, ktorý zadáte, t.j. Máte tri znaky, povedzme abc a pomocou TRANSLATE ho môžete nahradiť abc, takže máte a=a, b=b, c=c a podľa tohto princípu budú nahradené všetky zodpovedajúce znaky. A ak ste nahradili pomocou REPLACE, potom ste hľadali iba úplnú zhodu znakov abc umiestnených v rade.
Funkcia SUBSTR
SUBSTR – túto funkciu, vráti iba rozsah znakov, ktorý určíte. Inými slovami, povedzme reťazec 10 znakov, ale nepotrebujete všetkých desať, ale povedzme, že potrebujete iba 3-8 ( z tretieho na ôsme). Pomocou tejto funkcie to môžete jednoducho urobiť. Napríklad máte vo svojej databáze nejaký identifikátor pevnej dĺžky (napríklad AA-BB-55-66-CC) a každá kombinácia znakov niečo znamená. A v jednom okamihu vám bolo povedané, aby ste zobrazili iba 2. a 3. kombináciu znakov, na tento účel napíšete požiadavku nasledujúceho typu.
SELECT SUBSTR (ident, "4", "8") FROM tabuľky
tie. zobrazujeme všetky znaky začínajúce od 4 do 8 a po tejto požiadavke uvidíte toto:
Funkcia LENGTH – dĺžka reťazca
Nasledujúca funkcia môže tiež prísť vhod, to je DĹŽKA– ktorý jednoducho počíta počet znakov v riadku. Napríklad, musíte zistiť, koľko znakov je v každej bunke stĺpca, povedzte „meno“, tabuľka vyzerá takto.
SELECT LENGTH (meno) FROM tabuľkypo tejto žiadosti dostanete toto.
| 4 |
| 6 |
| 7 |
Pozreli sme sa teda na základné reťazcové funkcie SQL. V nasledujúcich článkoch budeme pokračovať v štúdiu SQL.
Posledná aktualizácia: 29.07.2017
Na prácu s reťazcami v T-SQL možno použiť nasledujúce funkcie:
LEN: Vráti počet znakov v riadku. Ako parameter je funkcii odovzdaný reťazec, ktorého dĺžku treba nájsť:
SELECT LEN("Apple") -- 5
LTRIM: Odstráni úvodné medzery z reťazca. Berie reťazec ako parameter:
SELECT LTRIM("Jablko")
RTRIM: Odstraňuje koncové medzery z reťazca. Berie reťazec ako parameter:
SELECT RTRIM(" Apple ")
CHARINDEX: Vráti index, v ktorom sa nachádza prvý výskyt podreťazca v reťazci. Podreťazec sa odovzdá ako prvý parameter a reťazec, v ktorom sa má hľadať, sa odovzdá ako druhý:
SELECT CHARINDEX("pl", "Apple") -- 3
PATINDEX: Vráti index, na ktorom sa nachádza prvý výskyt konkrétneho vzoru v reťazci:
SELECT PATINDEX("%p_e%", "Apple") -- 3
VĽAVO: rezy od začiatku riadku určité množstvo postavy. Prvý parameter funkcie je reťazec a druhý je počet znakov, ktoré je potrebné odrezať od začiatku reťazca:
SELECT LEFT("Apple", 3) -- App
VPRAVO: Vystrihne zadaný počet znakov z konca reťazca. Prvý parameter funkcie je reťazec a druhý je počet znakov, ktoré je potrebné odrezať od začiatku reťazca:
SELECT RIGHT("Apple", 3) -- prosím
PODREŤAZEC: Oddelí podreťazec špecifikovanej dĺžky z reťazca, začínajúc na konkrétnom indexe. Prvý parameter funkcie je reťazec, druhý je počiatočný index pre rezanie a tretí parameter je počet znakov na rezanie:
SELECT SUBSTRING("Galaxy S8 Plus", 8, 2) -- S8
REPLACE: Nahradí jeden podreťazec iným v rámci reťazca. Prvý parameter funkcie je reťazec, druhý je podreťazec, ktorý sa má nahradiť, a tretí je podreťazec, ktorý sa má nahradiť:
SELECT REPLACE("Galaxy S8 Plus", "S8 Plus", "Note 8") -- Galaxy poznámka 8
REVERSE : obráti reťazec:
SELECT REVERSE("123456789") -- 987654321
CONCAT: Spája dva reťazce do jedného. Ako parameter akceptuje 2 alebo viac reťazcov, ktoré je potrebné pripojiť:
SELECT CONCAT("Tom", " ", "Smith") -- Tom Smith
LOWER : Skonvertuje reťazec na malé písmená:
SELECT LOWER("Apple") -- jablko
UPPER: prevedie reťazec na veľké písmená
SELECT UPPER("Apple") -- APPLE
SPACE: vráti reťazec, ktorý obsahuje zadaný počet medzier
Zoberme si napríklad tabuľku:
CREATE TABLE Products (Id INT IDENTITY PRIMÁRNY KEY, ProductName NVARCHAR(30) NOT NULL, Manufacturer NVARCHAR(20) NOT NULL, ProductCount INT DEFAULT 0, Price MONEY NOT NULL);
A pri získavaní údajov použijeme reťazcové funkcie:
SELECT UPPER(LEFT(Manufacturer,2)) AS Skratka, CONCAT(ProductName, " - ", Manufacturer) AS FullProdName FROM Products ORDER BY skratka
Funkcie reťazca SQL
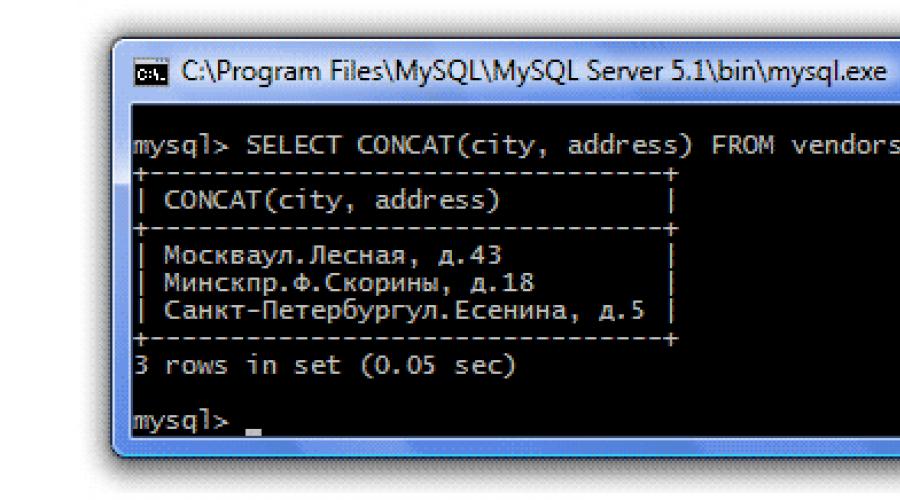
Táto skupina funkcií vám umožňuje manipulovať s textom. Reťazcových funkcií je veľa, my sa pozrieme na tie najbežnejšie.- CONCAT(str1,str2...) Vráti reťazec vytvorený zreťazením argumentov (argumenty sú v zátvorkách - str1,str2...). Napríklad v našej tabuľke Dodávatelia sú stĺpce Mesto a stĺpec Adresa. Predpokladajme, že chceme, aby výsledná tabuľka mala adresu a mesto v rovnakom stĺpci, t.j. chceme spojiť údaje z dvoch stĺpcov do jedného. Na to použijeme funkciu reťazca CONCAT() a ako argumenty uvedieme názvy stĺpcov, ktoré sa majú skombinovať – mesto a adresa:
SELECT CONCAT(mesto, adresa) FROM predajcov;

Upozorňujeme, že k zlúčeniu došlo bez rozdelenia, čo nie je príliš čitateľné. Upravme náš dotaz tak, aby medzi stĺpcami, ktoré sa spájajú, bola medzera:
SELECT CONCAT(mesto, " ", adresa) FROM predajcov;

Ako vidíte, medzera sa tiež považuje za argument a je označená oddelená čiarkou. Ak by bolo viac stĺpcov, ktoré sa majú zlúčiť, zadávanie medzier zakaždým by bolo iracionálne. V tomto prípade je možné použiť funkciu string CONCAT_WS(oddeľovač, str1,str2...), ktorý umiestni oddeľovač medzi zreťazené reťazce (oddeľovač je uvedený ako prvý argument). Náš dopyt potom bude vyzerať takto:
SELECT CONCAT_WS(" ", mesto, adresa) FROM predajcov;
Výsledok sa externe nezmenil, ale ak by sme spojili 3 alebo 4 stĺpce, kód by sa výrazne zmenšil.
- INSERT(str, poz, dĺžka, nový_str) Vráti reťazec str, ktorého podreťazec začína na pozícii poz a má dĺžku znakov len nahradenú podreťazcom new_str. Predpokladajme, že sa rozhodneme nezobrazovať prvé 3 znaky v stĺpci Adresa (skratky st., pr. atď.), potom ich nahradíme medzerami:
SELECT INSERT(adresa, 1, 3, " ") FROM dodávateľov;

To znamená, že tri znaky, počnúc prvým, sú nahradené tromi medzerami.
- LPAD(str, dĺžka, dop_str) Vráti reťazec str, vľavo doplnený dop_str na dĺžku len. Povedzme, že chceme zobraziť dodávateľské mestá napravo a vyplniť prázdne miesto bodkami:
SELECT LPAD(mesto, 15, ".") OD predajcov;

- RPAD(str, dĺžka, dop_str) Vráti reťazec str vpravo doplnený o dop_str na dĺžku len. Povedzme, že chceme zobraziť mestá dodávateľov vľavo a vyplniť prázdne miesto bodkami:
SELECT RPAD(mesto, 15, ".") OD predajcov;

Upozorňujeme, že hodnota len obmedzuje počet zobrazených znakov, t.j. ak je názov mesta dlhší ako 15 znakov, bude skrátený.
- LTRIM(str) Vráti reťazec str s odstránenými všetkými medzerami na začiatku. Táto funkcia reťazca je vhodná na správne zobrazenie informácií v prípadoch, keď sú pri zadávaní údajov povolené náhodné medzery:
SELECT LTRIM(mesto) FROM predajcov;
- RTRIM(str) Vráti reťazec str bez všetkých koncových medzier:
SELECT RTRIM(mesto) FROM predajcov;
V našom prípade extra priestory nebolo, takže výsledok navonok neuvidíme.
- TRIM(str) Vráti reťazec str s odstránenými všetkými medzerami na začiatku a na konci:
SELECT TRIM(mesto) FROM predajcov;
- LOWER(str) Vráti reťazec str so všetkými znakmi skonvertovanými na malé písmená. S ruskými písmenami to nefunguje správne, takže je lepšie ho nepoužívať. Použime napríklad túto funkciu na stĺpec mesta:
SELECT mesto, LOWER(mesto) FROM predajcov;
 Pozrite sa, aká hlúposť to bola. Ale všetko je v poriadku s latinskou abecedou:
Pozrite sa, aká hlúposť to bola. Ale všetko je v poriadku s latinskou abecedou: SELECT LOWER("MESTO");

- UPPER(str) Vráti reťazec str so všetkými znakmi skonvertovanými na veľké písmená. Tiež je lepšie ho nepoužívať s ruskými písmenami. Ale všetko je v poriadku s latinskou abecedou:
VYBERTE UPPER (e-mail) OD zákazníkov;

- LENGTH(str) Vráti dĺžku reťazca str. Napríklad, zistime, koľko znakov je v adresách našich dodávateľov:
SELECT adresu, LENGTH(adresa) FROM predajcov;

- LEFT(str, dĺžka) Vráti znaky vľavo v reťazci str. Nech sa napríklad v dodávateľských mestách zobrazia iba prvé tri znaky:
SELECT meno, LEFT(mesto, 3) FROM predajcov;

- RIGHT(str, dĺžka) Vráti len pravé znaky reťazca str. Napríklad v dodávateľských mestách nech sa zobrazia len posledné tri znaky: SELECT LOAD_FILE("C:/proverka");
 Upozorňujeme, že musíte zadať absolútnu cestu k súboru.
Upozorňujeme, že musíte zadať absolútnu cestu k súboru.