De ce sunt necesari indecși în sql? Indecși în SQL Server
Citeste si
1) Conceptul de index
Index este un instrument care oferă acces rapid la rândurile tabelului pe baza valorilor uneia sau mai multor coloane.
Există multă varietate în acest operator, deoarece nu este standardizat, deoarece standardele nu abordează problemele de performanță.
2) Crearea de indici
CREAȚI INDEX
PE()
3) Modificarea și ștergerea indecșilor
Pentru a controla activitatea indexului, se utilizează operatorul:
ALTER INDEX
Pentru a elimina un index, utilizați operatorul:
INDICE DE CĂDERARE
a) Reguli de selecție a mesei
1. Este recomandabil să indexați tabelele în care nu sunt selectate mai mult de 5% din rânduri.
2. Tabelele care nu au duplicate în clauza WHERE a instrucțiunii SELECT trebuie indexate.
3. Nu este practic să indexați tabelele actualizate frecvent.
4. Este nepotrivit să indexați tabelele care nu ocupă mai mult de 2 pagini (pentru Oracle aceasta este mai mică de 300 de rânduri), deoarece scanarea sa completă nu durează mai mult.
b) Reguli de selecție a coloanelor
1. Chei primare și străine - adesea folosite pentru a uni tabele, a prelua date și a căuta. Aceștia sunt întotdeauna indici unici cu utilitate maximă
2. Când utilizați opțiuni de integritate referențială, aveți întotdeauna nevoie de un index pe FK.
3. Coloane după care datele sunt adesea sortate și/sau grupate.
4. Coloane care sunt căutate frecvent în clauza WHERE a unei instrucțiuni SELECT.
5. Nu ar trebui să creați indecși pe coloane descriptive lungi.
c) Principii pentru crearea indicilor compoziţi
1. Indicii compoziți sunt buni dacă coloanele individuale au puține valori unice, dar un index compus oferă mai multă unicitate.
2. Dacă toate valorile selectate de instrucțiunea SELECT aparțin unui index compus, atunci valorile sunt selectate din index.
3. Ar trebui creat un index compus dacă clauza WHERE folosește două sau mai multe valori combinate cu operatorul AND.
d) Nu se recomandă crearea
Nu se recomandă crearea de indici pe coloane, inclusiv pe cele compuse, care:
1. Foarte rar folosit pentru căutarea, îmbinarea și sortarea rezultatelor interogărilor.
2. Conțin valori care se schimbă frecvent, ceea ce necesită actualizarea frecventă a indexului, ceea ce încetinește performanța bazei de date.
3. Nu contine număr mare valori unice (mai puțin de 10% m/f) sau un număr predominant de rânduri cu una sau două valori (orașul de reședință al furnizorului este Moscova).
4. Li se aplică funcții sau o expresie în clauza WHERE, iar indexul nu funcționează.
e) Nu trebuie să uităm
Ar trebui să vă străduiți să reduceți numărul de indici, deoarece un număr mare dintre ei reduce viteza de actualizare a datelor. Deci MS SQL Server recomandă crearea a nu mai mult de 16 indici pe tabel.
De obicei, indecșii sunt creați în scopuri de interogare și pentru a menține integritatea referențială.
Dacă indexul nu este folosit pentru interogări, ar trebui să fie șters și integritate referenţială furniza folosind declanșatoare.
Pentru început, vă sugerez să vă dați seama despre ce este vorba indice de acoperire, voi da un fragment dintr-un articol despre Habré:
De ce să folosiți un indice de acoperire în loc de un index compus?
În primul rând, să ne asigurăm că înțelegem diferența dintre cele două.
Indice compozit este doar un index obișnuit care include mai mult de o coloană. Pot fi folosite mai multe coloane de cheie pentru a vă asigura că fiecare rând dintr-un tabel este unic sau este posibil să aveți mai multe coloane pentru a vă asigura că cheia primară este unică sau este posibil să încercați să optimizați execuția interogărilor invocate frecvent pe mai multe coloane. În general, totuși, cu cât un index conține mai multe coloane cheie, cu atât indexul va fi mai puțin eficient, ceea ce înseamnă că indecșii compoziți trebuie utilizați în mod judicios.După cum sa menționat, o interogare poate beneficia foarte mult dacă toate datele necesare sunt imediat localizate pe frunzele indexului, la fel ca indexul însuși. Aceasta nu este o problemă pentru un index cluster deoarece toate datele sunt deja acolo (de aceea este atât de important să vă gândiți cu atenție când creați un index grupat). Dar un index negrupat pe frunze conține doar coloane cheie. Pentru a accesa toate celelalte date, optimizatorul de interogări necesită pași suplimentari, care pot adăuga o suprasarcină semnificativă la executarea interogărilor.
Acolo indice de acoperire se grăbește la salvare.
Astfel, indexul de acoperire nu trebuie să conțină toate coloanele selectabile ale interogării din structura arborelui indexului, ci doar cele care vor fi folosite pentru filtrarea sau gruparea datelor din interogare, coloanele rămase din secțiunea SELECT trebuie plasate în INCLUDE secțiunea indexului.
S-ar putea să găsiți util răspunsul de la o altă întrebare.
Exemplul de mai sus folosește un index compus cu 3 câmpuri, mai degrabă decât un index de acoperire, codul pentru a crea indexul de acoperire ar arăta astfel:
CREAȚI INDEXUL NONCLUSTER PE . ( ASC) INCLUDE (, ) WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE)_
Pentru a răspunde la întrebarea dvs.:
pentru un indice de acoperire, ordinea coloanelor din secțiunea INCLUDE nu important, dar ordinea coloanelor este importantă pentru un index compus, pentru că Datele coloanelor sunt plasate în arborele index în ordinea în care sunt listate coloanele, iar optimizatorul de interogări nu va putea folosi un index cu 2 coloane pentru a căuta valorile doar a 2 coloane. Puteți vedea un exemplu clar despre cum va arăta structura indexului a 2 coloane (EMPLOYEE_ID, SUBSIDIARY_ID) în figură.
6. Indici și optimizare a performanței
Indici în baze de date: scop, impact asupra performanței, principii de creare a indicilor
6.1 Pentru ce sunt indicii?
Indecșii sunt structuri speciale din bazele de date care vă permit să accelerați căutarea și sortarea după un anumit câmp sau set de câmpuri dintr-un tabel și sunt, de asemenea, utilizați pentru a asigura unicitatea datelor. Cel mai simplu mod de a compara indici este cu indici din cărți. Dacă nu există index, atunci va trebui să ne uităm prin întreaga carte pentru a găsi locul potrivit, dar cu un index aceeași acțiune poate fi efectuată mult mai rapid.
De obicei, cu cât sunt mai mulți indici, cu atât performanța interogărilor bazei de date este mai bună. Totuși, dacă numărul de indici crește excesiv, performanța operațiunilor de modificare a datelor (inserare/modificare/ștergere) scade și dimensiunea bazei de date crește, așa că adăugarea de indici trebuie tratată cu prudență.
Unele principii generale legate de crearea indexurilor:
· trebuie creați indecși pentru coloanele care sunt utilizate în îmbinări, care sunt adesea folosite pentru operațiuni de căutare și sortare. Vă rugăm să rețineți că indecșii sunt întotdeauna creați automat pentru coloanele care sunt supuse unei constrângeri de cheie primară. Cel mai adesea sunt create pentru coloane cu cheie străină(în Acces - automat);
· indexul este necesar în modul automat creat pentru coloanele care au o constrângere unică;
· Cel mai bine este să creați indici pentru acele câmpuri în care există un număr minim de valori repetate și datele sunt distribuite uniform. Oracle are indecși speciali de biți pe coloane cu un număr mare valori duplicate, SQL Server și Access nu oferă acest tip de index;
· dacă căutarea este efectuată în mod constant pe un anumit set de coloane (simultan), atunci în acest caz poate avea sens să se creeze un index compus (numai în SQL Server) - un index pentru un grup de coloane;
· Când se fac modificări la tabele, indecșii suprapusi pe acest tabel sunt modificați automat. Ca rezultat, indicele poate deveni foarte fragmentat, ceea ce are un impact asupra performanței. Ar trebui să verificați periodic gradul de fragmentare a indexului și să le defragmentați. Când încărcați o cantitate mare de date, uneori este logic să ștergeți mai întâi toți indecșii și să-i creați din nou după finalizarea operației;
· indecșii pot fi creați nu numai pentru tabele, ci și pentru vizualizări (doar în SQL Server). Avantaje - capacitatea de a calcula câmpuri nu în momentul solicitării, ci în momentul în care apar valori noi în tabele.
Una dintre cele mai importante moduri de a obține o productivitate ridicată SQL Server este utilizarea indicilor. Un index accelerează procesul de interogare, oferind acces rapid la rândurile de date dintr-un tabel, similar modului în care un index dintr-o carte vă ajută să găsiți rapid informatiile necesare. In acest articol voi da scurtă prezentare generală indici în SQL Serverși explicați cum sunt organizate în baza de date și cum ajută la accelerarea interogărilor bazei de date.Indecii sunt creați pe coloanele de tabel și vizualizare. Indecșii oferă o modalitate de a căuta rapid date pe baza valorilor din acele coloane. De exemplu, dacă creați un index pe o cheie primară și apoi căutați un rând de date folosind valorile cheii primare, atunci SQL Server va găsi mai întâi valoarea indexului și apoi va folosi indexul pentru a găsi rapid întregul rând de date. Fără un index, va fi efectuată o scanare completă a tuturor rândurilor din tabel, ceea ce poate avea un impact semnificativ asupra performanței.
Puteți crea un index pe majoritatea coloanelor dintr-un tabel sau vizualizare. Excepția sunt în principal coloanele cu tipuri de date pentru stocarea obiectelor mari ( LOB), ca imagine, text sau varchar(max). De asemenea, puteți crea indecși pe coloanele concepute pentru a stoca date în format XML, dar acești indici sunt structurați puțin diferit față de cei standard și luarea în considerare a acestora depășește domeniul de aplicare al acestui articol. De asemenea, articolul nu discută columnstore indici. În schimb, mă concentrez pe acei indecși care sunt utilizați cel mai frecvent în bazele de date SQL Server.
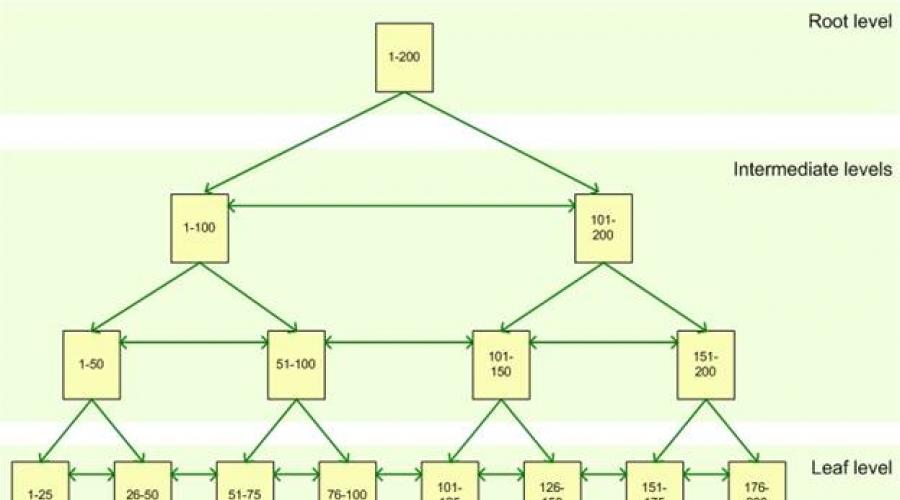
Un index constă dintr-un set de pagini, noduri de index, care sunt organizate într-o structură arborescentă - arbore echilibrat. Această structură este de natură ierarhică și începe cu un nod rădăcină în partea de sus a ierarhiei și noduri frunză, frunzele, în partea de jos, așa cum se arată în figură: 
Când interogați o coloană indexată, motorul de interogare pornește în partea de sus a nodului rădăcină și își parcurge drumul în jos prin nodurile intermediare, fiecare strat intermediar conținând informații mai detaliate despre date. Motorul de interogare continuă să se deplaseze prin nodurile de index până când ajunge la nivelul de jos cu frunzele de index. De exemplu, dacă căutați valoarea 123 într-o coloană indexată, motorul de interogare va determina mai întâi pagina la primul nivel intermediar la nivelul rădăcină. În acest caz, prima pagină indică o valoare de la 1 la 100, iar a doua de la 101 la 200, astfel încât motorul de interogare va accesa a doua pagină a acestui nivel intermediar. În continuare, veți vedea că ar trebui să treceți la a treia pagină a următorului nivel intermediar. De aici, subsistemul de interogări va citi valoarea indexului însuși la un nivel inferior. Frunzele de index pot conține fie datele tabelului în sine, fie pur și simplu un pointer către rânduri cu date în tabel, în funcție de tipul de index: clustered sau nonclustered.
Index grupat
Un index grupat stochează rândurile reale de date în frunzele indexului. Revenind la exemplul anterior, aceasta înseamnă că rândul de date asociat cu valoarea cheie de 123 va fi stocat în indexul însuși. Caracteristica importanta Un index grupat este că toate valorile sunt sortate într-o anumită ordine, fie crescător, fie descrescător. Prin urmare, un tabel sau o vizualizare poate avea un singur index grupat. În plus, trebuie remarcat faptul că datele dintr-un tabel sunt stocate în formă sortată numai dacă pe acest tabel a fost creat un index grupat.Un tabel care nu are un index grupat se numește heap.
Index negrupat
Spre deosebire de un index grupat, frunzele unui index nonclustered conțin doar acele coloane ( cheie) prin care se determină acest indice, și conține, de asemenea, un indicator către rânduri cu date reale din tabel. Aceasta înseamnă că sistemul de subinterogare necesită o operațiune suplimentară pentru a localiza și a prelua datele necesare. Conținutul indicatorului de date depinde de modul în care sunt stocate datele: tabel în cluster sau heap. Dacă un indicator indică un tabel grupat, acesta indică un index grupat care poate fi utilizat pentru a găsi datele reale. Dacă un pointer se referă la un heap, atunci indică un anumit identificator de rând de date. Indecșii nonclustered nu pot fi sortați ca indici clustered, dar puteți crea mai mult de un index nonclustered pe un tabel sau vizualizare, până la 999. Acest lucru nu înseamnă că ar trebui să creați cât mai mulți indecși posibil. Indicii pot fie îmbunătăți, fie pot degrada performanța sistemului. Pe lângă faptul că puteți crea mai mulți indecși non-cluster, puteți include și coloane suplimentare ( coloana inclusă) în indexul dvs.: frunzele indexului vor stoca nu numai valoarea coloanelor indexate în sine, ci și valorile acestor coloane suplimentare neindexate. Această abordare vă va permite să ocoliți unele dintre restricțiile impuse indexului. De exemplu, puteți include o coloană neindexabilă sau puteți ocoli limita de lungime a indexului (900 de octeți în majoritatea cazurilor).Tipuri de indici
Pe lângă faptul că este fie grupat, fie non-cluster, indexul mai poate fi configurat ca index compus, index unic sau index de acoperire.Indice compozit
Un astfel de index poate conține mai mult de o coloană. Puteți include până la 16 coloane într-un index, dar lungimea lor totală este limitată la 900 de octeți. Atât indecșii grupați, cât și cei care nu sunt grupați pot fi compuși.Index unic
Acest index asigură că fiecare valoare din coloana indexată este unică. Dacă indexul este compus, atunci unicitatea se aplică tuturor coloanelor din index, dar nu fiecărei coloane individuale. De exemplu, dacă creați un index unic pe coloane NUMEŞi PRENUME, Asta Numele complet trebuie să fie unice, dar sunt posibile duplicate în numele prenumelui.Un index unic este creat automat atunci când definiți o constrângere de coloană: cheie primară sau constrângere de valoare unică:
- Cheie primară
Atunci când definiți o constrângere a cheii primare pe una sau mai multe coloane, atunci SQL Server creează automat un index cluster unic dacă nu a fost creat anterior un index cluster (în acest caz, un index unic non-cluster este creat pe cheia primară) - Unicitatea valorilor
Atunci când definiți o constrângere asupra unicității valorilor, atunci SQL Server creează automat un index unic non-cluster. Puteți specifica crearea unui index cluster unic dacă nu a fost încă creat niciun index cluster pe tabel
Index de acoperire
Un astfel de index permite unei interogări specifice să obțină imediat toate datele necesare din frunzele indexului fără acces suplimentar la înregistrările tabelului în sine.Proiectarea indicilor
Oricât de utili pot fi indicii, ei trebuie proiectați cu atenție. Deoarece indexurile pot ocupa un spațiu semnificativ pe disc, nu doriți să creați mai mulți indecși decât este necesar. În plus, indecșii sunt actualizați automat atunci când rândul de date în sine este actualizat, ceea ce poate duce la supraîncărcare suplimentară a resurselor și la degradarea performanței. La proiectarea indexurilor trebuie luate în considerare mai multe considerații referitoare la baza de date și interogările împotriva acesteia.Baza de date
După cum sa menționat mai devreme, indexurile pot îmbunătăți performanța sistemului deoarece acestea oferă motorului de interogări o modalitate rapidă de a găsi date. Cu toate acestea, ar trebui să țineți cont și de cât de des intenționați să introduceți, să actualizați sau să ștergeți datele. Când modificați datele, indecșii trebuie, de asemenea, modificați pentru a reflecta acțiunile corespunzătoare asupra datelor, ceea ce poate reduce semnificativ performanța sistemului. Luați în considerare următoarele linii directoare atunci când vă planificați strategia de indexare:- Pentru tabelele care sunt actualizate frecvent, utilizați cât mai puțini indecși.
- Dacă tabelul conține o cantitate mare de date, dar modificările sunt minore, atunci utilizați cât mai mulți indecși este necesar pentru a îmbunătăți performanța interogărilor dvs. Cu toate acestea, gândiți-vă bine înainte de a utiliza indici pe tabele mici, deoarece... Este posibil ca utilizarea unei căutări index să dureze mai mult decât simpla scanare a tuturor rândurilor.
- Pentru indecșii grupați, încercați să păstrați câmpurile cât mai scurte posibil. Cea mai bună abordare este să folosiți un index grupat pe coloanele care au valori unice și nu permit NULL. Acesta este motivul pentru care o cheie primară este adesea folosită ca index grupat.
- Unicitatea valorilor dintr-o coloană afectează performanța indexului. În general, cu cât aveți mai multe duplicate într-o coloană, cu atât indexul are performanțe mai slabe. Pe de altă parte, cu cât sunt mai multe valori unice, cu atât performanța indicelui este mai bună. Folosiți un index unic ori de câte ori este posibil.
- Pentru un index compus, luați în considerare ordinea coloanelor din index. Coloane care sunt folosite în expresii UNDE(de exemplu, WHERE Prenume = „Charlie”) trebuie să fie primul în index. Coloanele ulterioare ar trebui listate pe baza unicității valorilor lor (coloanele cu cel mai mare număr de valori unice vin pe primul loc).
- De asemenea, puteți specifica un index pe coloanele calculate dacă acestea îndeplinesc anumite cerințe. De exemplu, expresiile folosite pentru a obține valoarea unei coloane trebuie să fie deterministe (se returnează întotdeauna același rezultat pentru un set dat de parametri de intrare).
Interogări baze de date
O altă considerație la proiectarea indicilor este ce interogări sunt executate în baza de date. După cum am menționat mai devreme, trebuie să luați în considerare cât de des se schimbă datele. În plus, trebuie utilizate următoarele principii:- Încercați să introduceți sau să modificați într-o singură cerere cât mai mult posibil mai multe linii mai degrabă decât să o facă în mai multe cereri individuale.
- Creați un index negrupat pe coloanele care sunt utilizate frecvent ca termeni de căutare în interogările dvs. UNDEși conexiuni în ÎNSCRIEȚI-VĂ.
- Luați în considerare indexarea coloanelor utilizate în interogările de căutare a rândurilor pentru potriviri exacte ale valorii.
Și acum, de fapt:
14 întrebări despre indecși în SQL Server pe care ați fost jenat să le puneți
De ce nu poate un tabel să aibă doi indici grupați?
Vrei un răspuns scurt? Un index grupat este un tabel. Când creați un index grupat pe un tabel, motorul de stocare sortează toate rândurile din tabel în ordine crescătoare sau descrescătoare, conform definiției indexului. Un index grupat nu este o entitate separată ca alți indecși, ci un mecanism pentru sortarea datelor într-un tabel și facilitarea acces rapid la liniile de date.Să ne imaginăm că aveți un tabel care conține istoricul tranzacțiilor de vânzare. Tabelul de vânzări include informații precum ID-ul comenzii, poziția articolului în comandă, numărul articolului, cantitatea articolului, numărul și data comenzii etc. Creați un index grupat pe coloane ID comandăŞi LineID, sortate în ordine crescătoare, după cum se arată în continuare T-SQL cod:
CREAȚI INDEXUL UNIC CLUSTERED ix_oriderid_lineid PE dbo.Sales(OrderID, LineID);
Când rulați acest script, toate rândurile din tabel vor fi sortate fizic mai întâi după coloana OrderID și apoi după LineID, dar datele în sine vor rămâne într-un singur bloc logic, tabelul. Din acest motiv, nu puteți crea doi indecși grupați. Poate exista un singur tabel cu o singură dată și acel tabel poate fi sortat o singură dată într-o anumită ordine.
Dacă un tabel grupat oferă multe beneficii, atunci de ce să folosiți un heap?
ai dreptate. Tabelele grupate sunt excelente și majoritatea interogărilor dvs. vor avea performanțe mai bune pe tabelele care au un index grupat. Dar, în unele cazuri, este posibil să doriți să lăsați mesele în starea lor naturală, curată, de exemplu. sub forma unui heap și creați numai indecși non-cluster pentru a vă menține interogările în funcțiune.Heap-ul, după cum vă amintiți, stochează datele în ordine aleatorie. De obicei, subsistemul de stocare adaugă date la un tabel în ordinea în care sunt introduse, dar subsistemul de stocare îi place, de asemenea, să mute rândurile pentru o stocare mai eficientă. Ca urmare, nu aveți nicio șansă să preziceți în ce ordine vor fi stocate datele.
Dacă motorul de interogări trebuie să găsească date fără a beneficia de un index neclustrat, atunci va face scanare completă tabele pentru a găsi rândurile de care are nevoie. Pe mesele foarte mici, aceasta nu este de obicei o problemă, dar pe măsură ce grămada crește în dimensiune, performanța scade rapid. Desigur, un index non-cluster poate ajuta folosind un indicator către fișierul, pagina și linia în care sunt stocate datele necesare - de obicei, aceasta este mult mai mult cea mai bună alternativă scanând tabelul. Chiar și așa, este dificil să compari beneficiile unui index grupat atunci când luăm în considerare performanța interogărilor.
Cu toate acestea, grămada poate ajuta la îmbunătățirea performanței în anumite situații. Luați în considerare un tabel cu multe inserări, dar puține actualizări sau ștergeri. De exemplu, un tabel care stochează un jurnal este folosit în primul rând pentru a insera valori până când este arhivat. Pe heap, nu veți vedea paginarea și fragmentarea datelor așa cum ați face cu un index grupat, deoarece rândurile sunt pur și simplu adăugate la sfârșitul heap-ului. Împărțirea prea mult a paginilor poate avea un impact semnificativ asupra performanței și nu într-un mod bun. În general, heap-ul vă permite să inserați date relativ fără durere și nu va trebui să vă ocupați de costurile de stocare și întreținere pe care le-ați face cu un index cluster.
Dar lipsa actualizării și ștergerii datelor nu ar trebui considerată singurul motiv. Modul în care datele sunt eșantionate este, de asemenea, un factor important. De exemplu, nu ar trebui să utilizați o grămadă dacă interogați frecvent intervale de date sau datele pe care le interogați adesea trebuie să fie sortate sau grupate.
Toate acestea înseamnă că ar trebui să luați în considerare utilizarea heap-ului numai atunci când lucrați cu tabele foarte mici sau toată interacțiunea cu tabelul este limitată la inserarea de date și interogările sunt extrem de simple (și utilizați indecși non-cluster). oricum). În caz contrar, rămâneți cu un index grupat bine conceput, cum ar fi unul definit pe un câmp cheie ascendent simplu, cum ar fi o coloană utilizată pe scară largă cu IDENTITATE.
Cum modific factorul de umplere implicit al indexului?
Modificarea factorului de umplere implicit al indexului este un lucru. Înțelegerea modului în care funcționează raportul implicit este o altă chestiune. Dar mai întâi, fă câțiva pași înapoi. Factorul de umplere a indexului determină cantitatea de spațiu pe pagină pentru a stoca indexul la nivelul de jos (nivelul frunzei) înainte de a începe umplerea noua pagina. De exemplu, dacă coeficientul este setat la 90, atunci când indicele crește, acesta va ocupa 90% din pagină și apoi va trece la pagina următoare.În mod implicit, valoarea factorului de umplere a indexului este în SQL Server este 0, care este la fel cu 100. Ca urmare, toți indecșii noi moștenesc automat această setare, cu excepția cazului în care specificați în mod specific o valoare în codul dvs. care este diferită de valoarea standard a sistemului sau modificați comportamentul implicit. Puteți folosi SQL Server Management Studio pentru a ajusta valoarea implicită sau pentru a rula o procedură stocată în sistem sp_configure. De exemplu, următorul set T-SQL comenzi setează valoarea coeficientului la 90 (mai întâi trebuie să comutați la modul setări avansate):
EXEC sp_configure „show advanced options”, 1; GO RECONFIGURĂ; GO EXEC sp_configure „factor de umplere”, 90; RECONFIGURAȚI; MERGE
După modificarea valorii factorului de umplere a indexului, trebuie să reporniți serviciul SQL Server. Acum puteți verifica valoarea setată rulând sp_configure fără al doilea argument specificat:
EXEC sp_configure „factor de umplere” GO
Această comandă ar trebui să returneze o valoare de 90. Ca rezultat, toți indecșii nou creați vor folosi această valoare. Puteți testa acest lucru creând un index și interogând valoarea factorului de umplere:
UTILIZAȚI AdventureWorks2012; -- baza de date GO CREATE NONCLUSTERED INDEX ix_people_lastname ON Person.Person(LastName); GO SELECT fill_factor FROM sys.indexes WHERE object_id = object_id("Person.Person") AND name="ix_people_lastname";
ÎN în acest exemplu am creat un index non-cluster pe tabel Persoanăîn baza de date AdventureWorks2012. După crearea indexului, putem obține valoarea factorului de umplere din tabelele de sistem sys.indexes. Interogarea ar trebui să returneze 90.
Cu toate acestea, să ne imaginăm că am șters indexul și l-am creat din nou, dar acum am specificat o anumită valoare a factorului de umplere:
CREATE NONCLUSTERED INDEX ix_people_lastname ON Person.Person(LastName) WITH (fillfactor=80); GO SELECT fill_factor FROM sys.indexes WHERE object_id = object_id("Person.Person") AND name="ix_people_lastname";
De data aceasta am adăugat instrucțiuni CUși opțiunea factor de umplere pentru operația noastră de creare a indexului CREAȚI INDEXși a specificat valoarea 80. Operator SELECTA acum returnează valoarea corespunzătoare.
Până acum, totul a fost destul de simplu. Unde vă puteți arde cu adevărat în întregul proces este atunci când creați un index care utilizează o valoare implicită a coeficientului, presupunând că cunoașteți acea valoare. De exemplu, cineva modifică setările serverului și este atât de încăpățânat încât a stabilit factorul de umplere a indexului la 20. Între timp, continuați să creați indici, presupunând că valoarea implicită este 0. Din păcate, nu aveți cum să aflați umplerea factor până când nu creați un index și apoi verificați valoarea așa cum am făcut în exemplele noastre. În caz contrar, va trebui să așteptați momentul în care performanța interogărilor scade atât de mult încât începeți să bănuiți ceva.
O altă problemă de care ar trebui să fii conștient este reconstruirea indicilor. Ca și în cazul creării unui index, puteți specifica valoarea factorului de umplere a indexului atunci când îl reconstruiți. Cu toate acestea, spre deosebire de comanda create index, reconstrucția nu folosește setările implicite ale serverului, în ciuda a ceea ce poate părea. Chiar mai mult, dacă nu specificați în mod specific valoarea factorului de umplere a indicelui, atunci SQL Server va folosi valoarea coeficientului cu care exista acest indice înainte de restructurarea lui. De exemplu, următoarea operație ALTER INDEX reconstruiește indexul pe care tocmai l-am creat:
ALTER INDEX ix_people_lastname ON Person.Person RECONSTRUIRE; GO SELECT fill_factor FROM sys.indexes WHERE object_id = object_id("Person.Person") AND name="ix_people_lastname";
Când verificăm valoarea factorului de umplere, vom obține o valoare de 80, deoarece aceasta este ceea ce am specificat când am creat ultima dată indexul. Valoarea implicită este ignorată.
După cum puteți vedea, modificarea valorii factorului de umplere a indicelui nu este atât de dificilă. Mult mai greu de știut valoarea curentăși înțelegeți când este folosit. Dacă specificați întotdeauna în mod specific coeficientul atunci când creați și reconstruiți indici, atunci știți întotdeauna rezultatul specific. Cu excepția cazului în care trebuie să vă faceți griji pentru a vă asigura că altcineva nu strica setările serverului din nou, determinând ca toți indexurile să fie reconstruite cu un factor de umplere ridicol de scăzut.
Este posibil să creați un index grupat pe o coloană care conține duplicate?
Da si nu. Da, puteți crea un index grupat pe o coloană cheie care conține valori duplicate. Nu, valoarea unei coloane cheie nu poate rămâne într-o stare non-unica. Lasă-mă să explic. Dacă creați un index grupat neunic pe o coloană, motorul de stocare adaugă un unificator la valoarea duplicată pentru a asigura unicitatea și, prin urmare, pentru a putea identifica fiecare rând din tabelul grupat.De exemplu, puteți decide să creați un index grupat pe o coloană care conține date despre clienți Nume păstrând numele de familie. Coloana conține valorile Franklin, Hancock, Washington și Smith. Apoi inserați din nou valorile Adams, Hancock, Smith și Smith. Dar valoarea coloanei cheie trebuie să fie unică, astfel încât motorul de stocare va schimba valoarea duplicatelor astfel încât acestea să arate cam așa: Adams, Franklin, Hancock, Hancock1234, Washington, Smith, Smith4567 și Smith5678.
La prima vedere, această abordare pare în regulă, dar o valoare întreagă mărește dimensiunea cheii, ceea ce poate deveni o problemă dacă există un număr mare de duplicate, iar aceste valori vor deveni baza unui index neclustrat sau a unui index străin. referință cheie. Din aceste motive, ar trebui să încercați întotdeauna să creați indecși grupați unici ori de câte ori este posibil. Dacă acest lucru nu este posibil, atunci cel puțin încercați să utilizați coloane cu un conținut de valoare unică foarte mare.
Cum este stocat tabelul dacă nu a fost creat un index cluster?
SQL Server acceptă două tipuri de tabele: tabele grupate care au un index grupat și tabele heap sau doar heaps. Spre deosebire de tabelele grupate, datele din heap nu sunt sortate în niciun fel. În esență, acesta este o grămadă de date. Dacă adăugați un rând la un astfel de tabel, motorul de stocare îl va adăuga pur și simplu la sfârșitul paginii. Când pagina este plină cu date, aceasta va fi adăugată la o pagină nouă. În cele mai multe cazuri, veți dori să creați un index grupat pe un tabel pentru a profita de capabilitățile de sortare și de interogări mai rapide (încercați să vă imaginați găsirea număr de telefon V agenda de adrese, nesortate după niciun principiu). Cu toate acestea, dacă alegeți să nu creați un index cluster, puteți crea în continuare un index nonclustered pe heap. În acest caz, fiecare rând index va avea un pointer către un rând heap. Indexul include ID-ul fișierului, numărul paginii și numărul liniei de date.Care este relația dintre constrângerile unicității valorii și o cheie primară cu indici de tabel?
O cheie primară și o constrângere unică asigură că valorile dintr-o coloană sunt unice. Puteți crea doar o cheie primară pentru un tabel și nu poate conține valori NUL. Puteți crea mai multe restricții privind unicitatea unei valori pentru un tabel și fiecare dintre ele poate avea o singură intrare cu NUL.Când creați o cheie primară, motorul de stocare creează, de asemenea, un index cluster unic dacă nu a fost deja creat un index cluster. Cu toate acestea, puteți suprascrie comportamentul implicit și va fi creat un index non-cluster. Dacă există un index grupat atunci când creați cheia primară, va fi creat un index unic nonclustrat.
Când creați o constrângere unică, motorul de stocare creează un index unic, necluster. Cu toate acestea, puteți specifica crearea unui index cluster unic dacă unul nu a fost creat anterior.
În general, o constrângere asupra unei valori unice și un indice unic sunt unul și același.
De ce indexurile grupate și non-cluster sunt numiți B-tree în SQL Server?
Indecșii de bază din SQL Server, în cluster sau necluster, sunt distribuiți în seturi de pagini numite noduri de index. Aceste pagini sunt organizate într-o ierarhie specifică cu o structură arborescentă numită arbore echilibrat. Pe nivel superior există un nod rădăcină, în partea de jos, noduri frunze terminale, cu noduri intermediare între nivelurile de sus și de jos, așa cum se arată în figură:Nodul rădăcină oferă punctul de intrare principal pentru interogările care încearcă să recupereze date prin index. Pornind de la acest nod, motorul de interogare inițiază o navigare în jos în structura ierarhică până la nodul frunză corespunzător care conține datele.
De exemplu, imaginați-vă că a fost primită o solicitare de selectare a rândurilor care conțin o valoare cheie de 82. Subsistemul de interogare începe să funcționeze de la nodul rădăcină, care se referă la un nod intermediar potrivit, în cazul nostru 1-100. De la nodul intermediar 1-100 există o tranziție la nodul 51-100, iar de acolo la nodul final 76-100. Dacă acesta este un index grupat, atunci frunza nodului conține datele rândului asociat cheii egale cu 82. Dacă acesta este un index negrupat, atunci frunza index conține un pointer către tabelul grupat sau un anumit rând din grămada.
Cum poate un index chiar să îmbunătățească performanța interogării dacă trebuie să traversați toate aceste noduri de index?
În primul rând, indicii nu îmbunătățesc întotdeauna performanța. Prea mulți indecși creați incorect transformă sistemul într-un mocir și degradează performanța interogărilor. Este mai corect să spunem că, dacă indicii sunt aplicați cu atenție, aceștia pot oferi câștiguri semnificative de performanță.Gândiți-vă la o carte uriașă dedicată reglajului performanței SQL Server(versiune pe hârtie, nu versiune electronică). Imaginați-vă că doriți să găsiți informații despre configurarea Resource Governor. Puteți trage cu degetul pagină cu pagină prin întreaga carte, sau deschideți cuprinsul și aflați numărul exact al paginii cu informațiile pe care le căutați (cu condiția ca cartea să fie indexată corect și conținutul să aibă indecșii corecti). Acest lucru cu siguranță vă va economisi timp semnificativ, chiar dacă mai întâi trebuie să accesați o structură complet diferită (indexul) pentru a obține informațiile de care aveți nevoie din structura primară (carte).
Ca un index de carte, un index în SQL Server vă permite să efectuați interogări exacte la datele dorite în loc să scanați complet toate datele conținute în tabel. Pentru tabelele mici, o scanare completă nu este de obicei o problemă, dar tabelele mari ocupă multe pagini de date, ceea ce poate duce la un timp semnificativ de execuție a interogării, cu excepția cazului în care există un index pentru a permite motorului de interogare să obțină imediat locația corectă a datelor. Imaginați-vă că vă pierdeți la o intersecție rutieră cu mai multe niveluri în fața unei metropole importante fără o hartă și veți înțelege ideea.
Dacă indexurile sunt atât de grozave, de ce să nu creați unul pe fiecare coloană?
Nicio faptă bună nu trebuie să rămână nepedepsită. Cel puțin așa este în cazul indicilor. Desigur, indecșii funcționează excelent atâta timp cât rulați interogări de preluare a operatorului SELECTA, dar de îndată ce încep apelurile frecvente către operatori INTRODUCE, UPDATEŞi ŞTERGE, așa că peisajul se schimbă foarte repede.Când inițiați o solicitare de date de către operator SELECTA, motorul de interogare găsește indexul, se deplasează prin structura sa arborescentă și descoperă datele pe care le caută. Ce poate fi mai simplu? Dar lucrurile se schimbă dacă inițiezi o declarație de modificare cum ar fi UPDATE. Da, pentru prima parte a declarației, motorul de interogare poate folosi din nou indexul pentru a localiza rândul care este modificat - aceasta este o veste bună. Și dacă există o simplă modificare a datelor într-un rând care nu afectează modificările în coloanele cheie, atunci procesul de modificare va fi complet nedureros. Dar dacă modificarea face ca paginile care conțin datele să fie împărțite sau valoarea unei coloane cheie este schimbată, ceea ce face ca aceasta să fie mutată într-un alt nod de index - acest lucru va avea ca rezultat ca indexul să aibă nevoie de o reorganizare care afectează toți indecșii și operațiunile asociate. , ducând la o scădere pe scară largă a productivității.
Procese similare apar la apelarea unui operator ŞTERGE. Un index poate ajuta la localizarea datelor care sunt șterse, dar ștergerea datelor în sine poate duce la remanierea paginii. Referitor la operator INTRODUCE, principalul inamic al tuturor indicilor: începi să adaugi o cantitate mare de date, ceea ce duce la modificări ale indicilor și reorganizarea acestora și toată lumea are de suferit.
Deci, luați în considerare tipurile de interogări către baza de date atunci când vă gândiți ce tip de indici și câți să creați. Mai mult nu înseamnă mai bine. Înainte de a adăuga un nou index la un tabel, calculați costul nu numai al interogărilor de bază, ci și al spațiului ocupat spațiu pe disc,costul de menținere a sănătății și a indicilor, care poate duce la un efect de domino asupra altor operațiuni. Strategia dumneavoastră de proiectare a indexului este unul dintre cele mai importante aspecte ale implementării dumneavoastră și ar trebui să includă multe considerații, de la dimensiunea indexului, numărul de valori unice până la tipul de interogări pe care indexul le va accepta.
Este necesar să se creeze un index grupat pe o coloană cu o cheie primară?
Puteți crea un index grupat pe orice coloană care îndeplinește condițiile necesare. Este adevărat că un index grupat și o constrângere a cheii primare sunt făcute unul pentru celălalt și sunt o potrivire făcută în rai, așa că înțelegeți faptul că atunci când creați o cheie primară, atunci un index grupat va fi creat automat dacă nu a fost unul. creat înainte. Cu toate acestea, puteți decide că un index grupat ar avea rezultate mai bune în altă parte și adesea decizia dvs. va fi justificată.Scopul principal al unui index grupat este de a sorta toate rândurile din tabel pe baza coloanei cheie specificate la definirea indexului. Aceasta oferă căutare rapidăŞi acces facil la datele tabelului.
Cheia primară a unui tabel poate fi o alegere bună, deoarece identifică în mod unic fiecare rând din tabele, fără a fi nevoie să adăugați date suplimentare. În unele cazuri cea mai buna alegere Va exista o cheie primară surogat care nu este doar unică, ci și de dimensiuni reduse și ale cărei valori cresc secvențial, ceea ce face ca indecșii non-cluster bazați pe această valoare să fie mai eficienți. Optimizatorul de interogări îi place, de asemenea, această combinație de index grupat și cheie primară, deoarece unirea tabelelor este mai rapidă decât alăturarea într-un alt mod care nu utilizează o cheie primară și indexul grupat asociat. După cum am spus, este un meci făcut în rai.
În cele din urmă, totuși, merită remarcat faptul că atunci când se creează un index grupat, există mai multe aspecte de luat în considerare: câți indici non-clusteri se vor baza pe acesta, cât de des se va schimba valoarea coloanei indexului cheie și cât de mare. Când valorile din coloanele unui index grupat se modifică sau indexul nu funcționează conform așteptărilor, atunci toți ceilalți indici de pe tabel pot fi afectați. Un index grupat ar trebui să se bazeze pe cea mai persistentă coloană ale cărei valori cresc într-o anumită ordine, dar nu se modifică în mod aleatoriu. Indexul trebuie să accepte interogări față de datele cel mai frecvent accesate ale tabelului, astfel încât interogările profită din plin de faptul că datele sunt sortate și accesibile la nodurile rădăcină, frunzele indexului. Dacă cheia primară se potrivește acestui scenariu, atunci utilizați-o. Dacă nu, atunci alegeți un alt set de coloane.
Ce se întâmplă dacă indexați o vizualizare, este încă o vizualizare?
Prezentarea este masă virtuală, care generează date din unul sau mai multe tabele. În esență, este o interogare numită care preia date din tabelele subiacente atunci când interogați acea vizualizare. Puteți îmbunătăți performanța interogărilor prin crearea unui index grupat și a indecșilor nonclustered în această vizualizare, similar modului în care creați indecși într-un tabel, dar principalul avertisment este că mai întâi creați un index grupat și apoi puteți crea unul nonclustered.Când este creată o vedere indexată (vizualizare materializată), atunci definiția vederii în sine rămâne o entitate separată. Acesta este, până la urmă, doar un operator codificat SELECTA, stocat în baza de date. Dar indexul este o cu totul altă poveste. Când creați un index cluster sau nonclustered pe un furnizor, datele sunt salvate fizic pe disc, la fel ca un index obișnuit. În plus, atunci când datele se modifică în tabelele de bază, indexul vizualizării se schimbă automat (aceasta înseamnă că este posibil să doriți să evitați indexarea vizualizărilor pe tabelele care se modifică frecvent). În orice caz, vizualizarea rămâne o vedere - o privire asupra tabelelor, dar executată cu precizie în în acest moment, cu indici corespunzători acestuia.
Înainte de a putea crea un index pe o vizualizare, acesta trebuie să îndeplinească mai multe constrângeri. De exemplu, o vizualizare poate face referire numai la tabele de bază, dar nu și la alte vederi, iar acele tabele trebuie să fie în aceeași bază de date. Există de fapt multe alte restricții, așa că asigurați-vă că verificați documentația SQL Server pentru toate detaliile murdare.
De ce să folosiți un indice de acoperire în loc de un index compus?
În primul rând, să ne asigurăm că înțelegem diferența dintre cele două. Un index compus este pur și simplu un index obișnuit care conține mai mult de o coloană. Pot fi folosite mai multe coloane cu cheie pentru a vă asigura că fiecare rând dintr-un tabel este unic sau este posibil să aveți mai multe coloane pentru a vă asigura că cheia primară este unică sau este posibil să încercați să optimizați execuția interogărilor executate frecvent pe mai multe coloane. În general, totuși, cu cât un index conține mai multe coloane cheie, cu atât indexul va fi mai puțin eficient, ceea ce înseamnă că indecșii compoziți trebuie utilizați în mod judicios.După cum sa menționat, o interogare poate beneficia foarte mult dacă toate datele necesare sunt imediat localizate pe frunzele indexului, la fel ca indexul însuși. Aceasta nu este o problemă pentru un index cluster deoarece toate datele sunt deja acolo (de aceea este atât de important să vă gândiți cu atenție când creați un index grupat). Dar un index negrupat pe frunze conține doar coloane cheie. Pentru a accesa toate celelalte date, optimizatorul de interogări necesită pași suplimentari, care pot adăuga o suprasarcină semnificativă la executarea interogărilor.
Aici indicele de acoperire vine în ajutor. Când definiți un index neclustrat, puteți specifica coloane suplimentare pentru coloanele cheie. De exemplu, să presupunem că aplicația dvs. interogează frecvent datele coloanei ID comandăŞi Data comandeiîn tabel Vânzări:
SELECT ID comandă, Data comandă FROM Vânzări WHERE ID comandă = 12345;
Puteți crea un index compus non-cluster pe ambele coloane, dar coloana OrderDate va adăuga doar costul general de întreținere a indexului, fără a servi ca o coloană cheie deosebit de utilă. Cea mai bună soluție ar fi crearea unui index de acoperire pe coloana cheie ID comandăși coloană inclusă în plus Data comandei:
CREATE NONCLUSTERED INDEX ix_orderid ON dbo.Sales(OrderID) INCLUDE (OrderDate);
Acest lucru evită dezavantajele indexării coloanelor redundante, menținând în același timp beneficiile stocării datelor în frunze atunci când rulează interogări. Coloana inclusă nu face parte din cheie, dar datele sunt stocate exact pe nodul frunză, frunza index. Acest lucru poate îmbunătăți performanța interogărilor fără nicio suprasolicitare suplimentară. În plus, coloanele incluse în indexul de acoperire sunt supuse la mai puține restricții decât coloanele cheie ale indexului.
Numărul de duplicate dintr-o coloană cheie contează?
Când creați un index, trebuie să încercați să reduceți numărul de duplicate din coloanele cheie. Sau mai precis: incearca sa pastrezi rata de repetare cat mai scazuta.Dacă lucrați cu un index compus, atunci duplicarea se aplică tuturor coloanelor cheie în ansamblu. O singură coloană poate conține multe valori duplicate, dar ar trebui să existe o repetiție minimă între toate coloanele index. De exemplu, creați un index compus nonclustered pe coloane PrenumeŞi Nume, puteți avea multe valori John Doe și multe valori Doe, dar doriți să aveți cât mai puține valori John Doe posibil, sau de preferință doar o singură valoare John Doe.
Raportul de unicitate al valorilor unei coloane cheie se numește selectivitate index. Cu cât sunt mai multe valori unice, cu atât selectivitatea este mai mare: un indice unic are cea mai mare selectivitate posibilă. Motorului de interogări îi plac foarte mult coloanele cu valori de selectivitate ridicate, mai ales dacă acele coloane sunt incluse în clauzele WHERE ale interogărilor executate cel mai frecvent. Cu cât indexul este mai selectiv, cu atât mai rapid motorul de interogare poate reduce dimensiunea setului de date rezultat. Dezavantajul, desigur, este că coloanele cu relativ puține valori unice vor fi rareori candidați buni pentru indexare.
Este posibil să se creeze un index non-cluster doar pe un anumit subset al datelor unei coloane cheie?
În mod implicit, un index nonclustered conține câte un rând pentru fiecare rând din tabel. Desigur, puteți spune același lucru despre un index grupat, presupunând că un astfel de index este un tabel. Dar când vine vorba de un index non-clustered, relația unu-la-unu este un concept important deoarece, începând cu versiunea SQL Server 2008, aveți opțiunea de a crea un index filtrabil care limitează rândurile incluse în acesta. Un index filtrat poate îmbunătăți performanța interogării deoarece... are dimensiuni mai mici și conține statistici filtrate, mai precise decât toate cele tabelare - acest lucru duce la crearea unor planuri de execuție îmbunătățite. Un index filtrat necesită, de asemenea, mai puțin spațiu de stocare și costuri de întreținere mai mici. Indexul este actualizat numai atunci când datele care corespund filtrului se modifică.În plus, un index filtrabil este ușor de creat. În operator CREAȚI INDEX trebuie doar să indicați în UNDE starea filtrului. De exemplu, puteți filtra toate rândurile care conțin NULL din index, așa cum se arată în cod:
CREATE NONCLUSTERED INDEX ix_trackingnumber ON Sales.SalesOrderDetail(CarrierTrackingNumber) WHERE CarrierTrackingNumber NU ESTE NULL;
Putem, de fapt, să filtram orice date care nu sunt importante în interogările critice. Dar ai grijă, pentru că... SQL Server impune mai multe restricții asupra indecșilor filtrabili, cum ar fi incapacitatea de a crea un index filtrabil pe o vizualizare, deci citiți cu atenție documentația.
De asemenea, se poate obține rezultate similare prin crearea unei vizualizări indexate. Cu toate acestea, un index filtrat are mai multe avantaje, cum ar fi capacitatea de a reduce costurile de întreținere și de a îmbunătăți calitatea planurilor dumneavoastră de execuție. Indexurile filtrate pot fi reconstruite și online. Încercați acest lucru cu o vizualizare indexată.
Și din nou puțin de la traducător
Scopul apariției a acestei traduceri pe paginile lui Habrahabr era pentru a vă spune sau a vă aminti despre blogul SimpleTalk din RedGate.
Publică multe postări distractive și interesante.
Nu sunt afiliat cu niciun produs al companiei RedGate, nici cu vânzarea lor.
După cum am promis, cărți pentru cei care vor să afle mai multe
Recomand trei cărți foarte bune de la mine (linkurile duc la aprinde versiuni în magazin Amazon):
 |
Noțiuni fundamentale pentru Microsoft SQL Server 2012 T-SQL (referință pentru dezvoltatori) Autorul Itzik Ben-Gan Data publicării: 15 iulie 2012 Autorul, un maestru al meșteșugului său, oferă cunoștințe de bază despre lucrul cu bazele de date. Dacă ai uitat totul sau nu ai știut niciodată, cu siguranță merită citit. | În principiu, puteți deschide indecși simpli
ÎN acest material astfel de obiecte de bază de date vor fi luate în considerare Microsoft SQL Server Cum indici Veți afla ce sunt indecșii, ce tipuri de indici există, cum să îi creați, să-i optimizați și să-i ștergeți.
Ce sunt indecșii dintr-o bază de date?
Index este un obiect de bază de date care este o structură de date constând din chei construite din una sau mai multe coloane ale unui tabel sau vizualizare și pointeri care se mapează la locul în care sunt stocate datele specificate. Indecii sunt proiectați pentru a prelua mai rapid rândurile dintr-un tabel, cu alte cuvinte, indecșii permit căutarea rapidă a datelor într-un tabel, ceea ce îmbunătățește foarte mult performanța interogărilor și a aplicației. De asemenea, indecșii pot fi utilizați pentru a asigura rânduri unice într-un tabel, asigurând astfel integritatea datelor.
Tipuri de indexuri în Microsoft SQL Server
În Microsoft SQL Server există următoarele tipuri de indici:
- Grupate (Grupate) este un index care stochează date de tabel sortate după valoarea cheii de index. Un tabel poate avea un singur index grupat deoarece datele pot fi sortate doar într-o singură ordine. Dacă este posibil, fiecare tabel ar trebui să aibă un index cluster dacă un tabel nu are un index cluster, tabelul se numește "; într-o grămadă" Un index grupat este creat automat atunci când creați constrângeri PRIMARY KEY ( cheie primară) și UNIQUE dacă un index grupat pe tabel nu a fost încă definit. Dacă creați un index grupat pe un tabel ( grămezi) care conține indecși non-cluster, apoi toți trebuie reconstruiți după creare.
- Negrupat (Negrupate) este un index care conține valoarea unei chei și un pointer către un rând de date care conține valoarea acelei chei. Un tabel poate avea mai mulți indecși non-cluster. Indicii non-cluster pot fi creați pe tabele cu sau fără un index cluster. Acest tip de index este utilizat pentru a îmbunătăți performanța interogărilor frecvent utilizate, deoarece indecșii non-cluster oferă căutare rapidă și acces la date după valorile cheie;
- Filtrabil (Filtrată) este un index optimizat nonclustered care utilizează un predicat de filtru pentru a indexa un subset de rânduri dintr-un tabel. Dacă este proiectat bine, acest tip de index poate îmbunătăți performanța interogărilor și, de asemenea, poate reduce costurile de întreținere și stocare a indexului în comparație cu indecșii cu tabel complet;
- Unic (Unic) este un index care asigură că nu există duplicate ( identic) indexează valorile cheilor, garantând astfel unicitatea rândurilor conform această cheie. Atât indecșii grupați cât și cei care nu sunt în cluster pot fi unici. Dacă creați un index unic pe mai multe coloane, indexul asigură că fiecare combinație de valori din cheie este unică. Când creați constrângeri PRIMARY KEY sau UNIQUE, serverul SQL creează automat un index unic pe coloanele cheie. Un index unic poate fi creat numai dacă tabelul nu are în prezent valori duplicate în coloanele cheie;
- Columnar (Magazin de coloane) este un index bazat pe tehnologia de stocare a datelor în coloană. Acest tip Indexul este eficient pentru depozitele mari de date deoarece poate crește performanța interogărilor către magazin de până la 10 ori și, de asemenea, poate reduce dimensiunea datelor de până la 10 ori, deoarece datele din indexul Columnstore sunt comprimate. Există atât indecși de coloane grupați, cât și non-cluster;
- Text complet (Text integral) este un tip special de index care oferă suport eficient pentru căutări complexe de cuvinte pe datele șirurilor de caractere. Procesul de creare și menținere a unui index full-text se numește „ umplere" Există astfel de tipuri de umplere precum: umplere completă și umplere bazată pe urmărirea modificărilor. În mod implicit, SQL Server populează complet un nou index full-text imediat după ce acesta este creat, dar acest lucru poate necesita o cantitate semnificativă de resurse, în funcție de dimensiunea tabelului, astfel încât este posibil să se întârzie populația completă. Seeding-ul bazat pe urmărirea modificărilor este utilizat pentru a menține indexul de text complet după ce este inițial completat;
- Spațial (Spațial) este un index care vă permite să utilizați mai eficient operațiuni specifice asupra obiectelor spațiale în coloane de tipul de date geometrie sau geografie. Acest tip de index poate fi creat doar pe o coloană spațială, iar tabelul pe care este definit indexul spațial trebuie să conțină o cheie primară ( CHEIA PRIMARĂ);
- XML este un alt tip special de index care este conceput pentru coloane de tip date XML. Indexul XML îmbunătățește eficiența procesării interogărilor împotriva coloanelor XML. Există două tipuri de index XML: primar și secundar. Un index XML primar indexează toate etichetele, valorile și căile stocate într-o coloană XML. Poate fi creat numai dacă tabelul are un index grupat pe cheia primară. Un index XML secundar poate fi creat doar dacă tabelul are un index XML primar și este folosit pentru a îmbunătăți performanța interogărilor pe un anumit tip de acces la coloana XML, în acest sens, există mai multe tipuri de indecși secundari: PATH , VALOARE și PROPRIETATE;
- Există, de asemenea, indecși speciali pentru tabelele optimizate pentru memorie ( OLTP în memorie) cum ar fi: Hash ( Hash) indecși optimizați pentru memorie și indecși non-cluster care sunt creați pentru scanări de interval și scanări ordonate.
Crearea și ștergerea indecșilor în Microsoft SQL Server
Înainte de a începe să creați un index, este necesar să îl proiectați bine pentru a utiliza indexul în mod eficient, deoarece indecșii proiectați prost pot să nu îmbunătățească performanța, ci mai degrabă să o reducă. De exemplu, a avea un număr mare de indici pe un tabel reduce performanța instrucțiunilor INSERT, UPDATE, DELETE și MERGE deoarece atunci când datele din tabel se modifică, toți indecșii trebuie actualizați corespunzător. Recomandări generale Ne vom uita la proiectarea indexurilor într-un material separat, dar acum să trecem direct la luarea în considerare a procesului de creare și ștergere a indexurilor.
Nota! Serverul meu SQL este Microsoft SQL Server 2016 Express.
Crearea de indici
Există două moduri de a crea indici în Microsoft SQL Server: prima este utilizarea interfeței grafice a mediului SQL Server Management Studio (SSMS), iar a doua este utilizarea limbajului Transact-SQL, vom analiza ambele metode.
Date sursă pentru exemple
Să ne imaginăm că avem un tabel de produse numit TestTable, care are trei coloane:
- ProductId – identificator de produs;
- ProductName – numele produsului;
- CategoryID – categorie de produs.
Exemplu de creare a unui index grupat
După cum am spus deja, un index grupat este creat automat dacă, de exemplu, la crearea unui tabel, specificăm o anumită coloană ca cheie primară ( CHEIA PRIMARĂ), dar din moment ce nu am făcut asta, să ne uităm la un exemplu de creare a unui index cluster.
Pentru a crea un index cluster, putem specifica o cheie primară pentru tabel și astfel indexul cluster va fi creat automat, sau putem crea separat un index cluster.
De exemplu, să creăm un index grupat, fără a crea o cheie primară. Să o facem mai întâi cu folosind Management Studio.
Deschideți SSMS și găsiți tabelul dorit în browserul de obiecte și faceți clic dreapta pe elementul „ Indici", selectați " Creați index" și tipul de index, în cazul nostru " Grupate».

Forma „ Index nou", unde trebuie să specificăm numele noului index ( trebuie să fie unic în tabel), indicăm și dacă acest index va fi unic dacă vorbim despre identificatorul de produs din tabelul de produse, atunci, desigur, trebuie să fie unic; Apoi selectați coloana ( cheie de index), pe baza căruia vom crea un index grupat, i.e. rândurile de date din tabel vor fi sortate folosind „ Adăuga».

După introducerea tuturor parametrilor necesari, faceți clic pe „ Bine", eventual va fi creat un index cluster.

În mod similar, se poate crea un index cluster folosind o instrucțiune T-SQL INDEXUL CREATURII, de exemplu, așa
CREATE UNIQUE CLUSTERED INDEX IX_Clustered ON TestTable (ProductId ASC) GO
Sau, așa cum am spus deja, am putea folosi și o declarație pentru a crea o cheie primară, de exemplu
ALTER TABLE TestTable ADD CONSTRAINT PK_TestTable PRIMARY KEY CLUSTERED (ProductId ASC) GO
Exemplu de creare a unui index nonclustered cu coloane incluse
Acum să ne uităm la un exemplu de creare a unui index neclustrat, în care vom indica coloanele care nu vor fi cheie, dar vor fi incluse în index. Acest lucru este util în cazurile în care creați un index pentru cerere specifică, de exemplu, astfel încât indexul să acopere complet interogarea, i.e. conținea toate coloanele ( aceasta se numește „Solicitare acoperire”). Acoperirea interogărilor îmbunătățește performanța deoarece optimizatorul de interogări poate găsi toate valorile coloanelor din index fără a accesa datele din tabel, ceea ce duce la mai puține operațiuni I/O pe disc. Dar amintiți-vă că includerea coloanelor non-cheie în index implică o creștere a dimensiunii indexului, de exemplu. stocarea indexului va necesita mai mult spațiu pe disc și poate duce, de asemenea, la o performanță redusă pentru operațiunile INSERT, UPDATE, DELETE și MERGE din tabelul de bază.
Pentru a crea un index non-cluster folosind GUI Management Studio, găsim și tabelul dorit și elementul Indexes, doar că în acest caz selectăm „ Creare -> Index non-clustered».

După deschiderea formularului " Index nou"specificăm numele indexului, adăugăm o coloană sau coloane cheie folosind butonul " Adăuga", de exemplu, pentru cazul nostru de testare, să specificăm CategoryID.

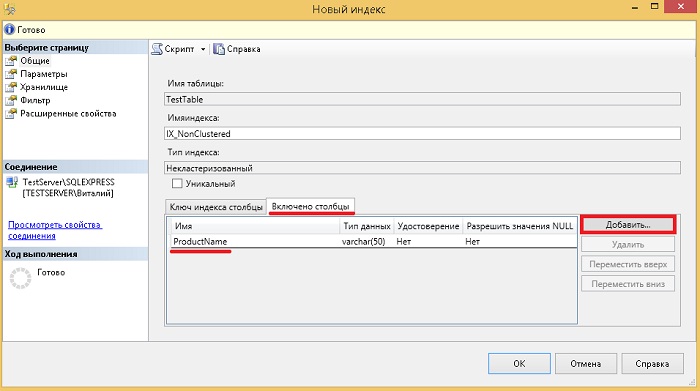
În Transact-SQL ar arăta așa.
CREATE NONCLUSTERED INDEX IX_NonClustered ON TestTable (CategoryID ASC) INCLUDE (ProductName) GO
Exemplu de ștergere a unui index în Microsoft SQL Server
Pentru a șterge un index, puteți face clic dreapta pe indexul dorit și faceți clic pe „ Şterge", apoi confirmați acțiunile dvs. făcând clic pe „ Bine».

sau puteți folosi și instrucțiunile INDICE DE CĂDERARE, De exemplu
DROP INDEX IX_NonClustered ON TestTable
Trebuie remarcat faptul că instrucțiunea DROP INDEX nu se aplică indecșilor care au fost creați prin crearea constrângerilor PRIMARY KEY și UNIQUE. În acest caz, pentru a elimina indexul, trebuie să utilizați instrucțiunea ALTER TABLE cu clauza DROP CONSTRAINT.
Optimizarea indicilor în Microsoft SQL Server
Ca rezultat al efectuării operațiunilor de actualizare, adăugare sau ștergere a datelor în tabele SQL serverul face automat modificările corespunzătoare la indexuri, dar în timp toate aceste modificări pot cauza fragmentarea datelor din index, adică. vor ajunge împrăștiați în baza de date. Fragmentarea indexurilor atrage după sine o scădere a performanței interogărilor, astfel că periodic este necesară efectuarea operațiunilor de întreținere a indexului, și anume defragmentare, precum operațiunile de reorganizare și reconstrucție a indexului.
Când să folosiți reorganizarea indexului și când să reconstruiți?
Pentru a răspunde la această întrebare, trebuie mai întâi să determinați gradul de fragmentare a indexului, deoarece în funcție de fragmentarea indexului, una sau alta metodă de defragmentare va fi de preferat și mai eficientă. Puteți utiliza funcția tabel de sistem pentru a determina gradul de fragmentare a indexului sys.dm_db_index_physical_stats, care returnează informații detaliate despre dimensiunea și fragmentarea indicilor. De exemplu, folosind următoarea interogare, puteți afla gradul de fragmentare a indexului pentru toate tabelele din baza de date curentă.
SELECT OBJECT_NAME(T1.object_id) AS NameTable, T1.index_id AS IndexId, T2.name AS IndexName, T1.avg_fragmentation_in_percent AS Fragmentation FROM sys.dm_db_index_physical_stats (DB_ID(), NULL, LEFT NULL) AS T sys1, LEFT NULL. indexează AS T2 ON T1.object_id = T2.object_id ȘI T1.index_id = T2.index_id
În acest caz, ne interesează rubrica medie_fragmentare_în_procent, adică procentul de fragmentare logica.
- Dacă gradul de fragmentare este mai mic de 5%, atunci reorganizarea sau reconstruirea indexului nu trebuie începută deloc;
- Dacă gradul de fragmentare este de la 5 la 30%, atunci este logic să începem reorganizarea indicelui, deoarece această operațiune utilizează resurse minime de sistem și nu necesită blocări pe termen lung;
- Dacă gradul de fragmentare este mai mare de 30%, atunci este necesară reconstrucția indicelui, deoarece această operațiune, cu fragmentare semnificativă, dă un efect mai mare decât operația de reorganizare a indexului.
Personal, pot adăuga următoarele dacă aveți o companie mică și baza de date nu necesită producție maximă 24 de ore pe zi, adică. Deoarece nu este o bază de date super activă, puteți efectua periodic în siguranță operația de reconstrucție a indecșilor, fără a determina măcar gradul de fragmentare.
Reorganizarea indicilor
Reorganizarea indexului este un proces de defragmentare a indexului care defragmentează indecșii grupați la nivel de frunză și non-cluster pe tabele și vizualizări prin reordonarea fizică a paginilor la nivel de frunză în conformitate cu ordinea logică ( de la stânga la dreapta) nodurile de capăt.
Puteți utiliza fie instrumentul grafic SSMS, fie instrucțiunea Transact-SQL pentru a reorganiza indexul.
Reorganizarea unui index folosind Management Studio

Reorganizarea unui index folosind Transact-SQL
ALTER INDEX IX_NonClustered ON TestTable REORGANIZE GO
Reconstruirea indicilor
Reconstruirea indexului este un proces în care vechiul index este șters și se creează unul nou, având ca rezultat eliminarea fragmentării.
Puteți folosi două metode pentru a reconstrui indecși.
Primul. Folosind instrucțiunea ALTER INDEX cu clauza REBUILD. Această instrucțiune înlocuiește instrucțiunea DBCC DBREINDEX. De obicei, aceasta este metoda folosită pentru a reconstrui în masă indici.
Exemplu
ALTER INDEX IX_NonClustered ON TestTable RECONSTRUIRE GO
Și al doilea, folosind instrucțiunea CREATE INDEX cu clauza DROP_EXISTING. Poate fi folosit, de exemplu, pentru a reconstrui un index prin modificarea definiției acestuia, de ex. adăugarea sau eliminarea coloanelor cheie.
Exemplu
CREATE NONCLUSTERED INDEX IX_NonClustered ON TestTable (CategoryID ASC) WITH(DROP_EXISTING = ON) GO
Funcționalitatea de reconstrucție este disponibilă și în Management Studio. Faceți clic dreapta după indicele cerut" Reconstrui».

Aceasta încheie materialul despre elementele de bază ale indicilor în Microsoft SQL Server, dacă sunteți interesat Limbajul T-SQL, atunci recomand să-mi citești cartea „